Broken Authentication
La autenticación se define como «el proceso de verificar una afirmación de que una entidad o recurso del sistema tiene un determinado valor de atributo» en RFC 4949. En seguridad de la información, la autenticación es el proceso de confirmar la identidad de una entidad, asegurándose de que es quien dice ser. Por otro lado, la autorización es una «aprobación que se concede a una entidad del sistema para acceder a un recurso del sistema».

La autenticación se define como «el proceso de verificar una afirmación de que una entidad o recurso del sistema tiene un determinado valor de atributo» en RFC 4949. En seguridad de la información, la autenticación es el proceso de confirmar la identidad de una entidad, asegurándose de que es quien dice ser. Por otro lado, la autorización es una «aprobación que se concede a una entidad del sistema para acceder a un recurso del sistema».
Autenticación vs. Autorización
Autenticación
Determina si los usuarios son quienes dicen ser.
Desafía al usuario para validar sus credenciales (por ejemplo, mediante contraseñas, respuestas a preguntas de seguridad o reconocimiento facial).
Generalmente se realiza antes de la autorización.
Normalmente requiere los datos de inicio de sesión del usuario.
Por lo general, transmite la información a través de un Token de ID (ID Token).
Autorización
Determina a qué pueden y a qué no pueden acceder los usuarios.
Verifica si el acceso está permitido a través de políticas y reglas.
Generalmente se realiza después de una autenticación exitosa.
Requiere los privilegios o niveles de seguridad del usuario.
Por lo general, transmite la información a través de un Token de Acceso (Access Token).
El método de autenticación más extendido en las aplicaciones web son los formularios de inicio de sesión, en los que los usuarios introducen su nombre de usuario y contraseña para demostrar su identidad. Los formularios de inicio de sesión se pueden encontrar en muchos sitios web, incluidos los proveedores de correo electrónico, la banca en línea, etc…
Métodos de Autenticación Comunes
Los sistemas de tecnología de la información pueden implementar diferentes métodos de autenticación. Típicamente, se pueden dividir en las siguientes tres categorías principales:
Autenticación basada en conocimiento
Autenticación basada en posesión (propiedad)
Autenticación basada en inherencia
Conocimiento
La autenticación basada en factores de conocimiento se apoya en algo que el usuario sabe para demostrar su identidad. El usuario proporciona información como contraseñas, frases de contraseña (passphrases), PINs o respuestas a preguntas de seguridad.
Posesión
La autenticación basada en factores de posesión se apoya en algo que el usuario posee. El usuario demuestra su identidad evidenciando la propiedad de un objeto físico o dispositivo, como una tarjeta de identificación, un token de seguridad o un teléfono inteligente con una aplicación de autenticación.
Inherencia
Por último, la autenticación basada en factores de inherencia se apoya en algo que el usuario es o hace. Esto incluye factores biométricos como huellas dactilares, patrones faciales y reconocimiento de voz, o firmas. La autenticación biométrica es altamente efectiva ya que los rasgos biométricos están intrínsecamente ligados a un usuario individual.
|Conocimiento|Posesión (Propiedad)|Inherencia| |—|—|—| |Contraseña|Tarjeta de ID|Huella dactilar| |PIN|Token de seguridad|Patrón facial| |Respuesta a pregunta de seguridad|App de autenticación|Reconocimiento de voz|
Autenticación de Factor Único vs. Autenticación Multifactor
Autenticación de factor único (SFA): Se basa exclusivamente en un único método de autenticación. Por ejemplo, la autenticación por contraseña depende únicamente del conocimiento de la misma. Como tal, es un método de autenticación de factor único.
Autenticación multifactor (MFA): Involucra múltiples métodos de autenticación. Por ejemplo, si una aplicación web requiere una contraseña y una contraseña de un solo uso basada en tiempo (TOTP), depende del conocimiento de la contraseña y de la posesión del dispositivo TOTP para la autenticación. En el caso de que se requieran exactamente dos factores, el MFA se denomina comúnmente autenticación de dos factores (2FA).
Ataques a la Autenticación
Ataque a la Autenticación Basada en Conocimiento
La autenticación basada en conocimiento es prevalente y comparativamente fácil de atacar. Por ello, nos enfocaremos principalmente en este método durante este módulo. Este sistema sufre por su dependencia de información personal estática que puede ser potencialmente obtenida, adivinada o forzada por fuerza bruta. A medida que las ciberamenazas evolucionan, los atacantes se han vuelto expertos en explotar las debilidades de estos sistemas mediante diversos medios, incluyendo la ingeniería social y las brechas de datos.
Ataque a la Autenticación Basada en Posesión (Propiedad)
Una ventaja significativa de la autenticación basada en posesión es su resistencia a muchas ciberamenazas comunes, incluyendo el phishing y los ataques de adivinación de contraseñas. Los métodos basados en la posesión física, como tokens de hardware o tarjetas inteligentes, son intrínsecamente más seguros porque los objetos físicos son más difíciles de adquirir o replicar para un atacante en comparación con la información que puede ser obtenida mediante brechas de datos. Sin embargo, desafíos como el costo y la logística de distribución pueden limitar su adopción generalizada.
Además, estos sistemas pueden ser vulnerables a ataques físicos, como el robo o la clonación del objeto, así como a ataques criptográficos sobre el algoritmo empleado. Por ejemplo, la clonación de objetos como tarjetas NFC en lugares públicos (transporte o cafeterías) es un vector de ataque factible.
Ataque a la Autenticación Basada en Inherencia
La autenticación basada en inherencia aporta conveniencia y facilidad de uso; el usuario no necesita recordar contraseñas complejas ni portar tokens, simplemente proporciona datos biométricos. Sin embargo, estos sistemas deben abordar preocupaciones sobre la privacidad, la seguridad de los datos y los posibles sesgos en los algoritmos de reconocimiento.
Por otro lado, los sistemas basados en inherencia pueden verse comprometidos de forma irreversible en caso de una brecha de datos. Esto se debe a que los usuarios no pueden cambiar sus rasgos biométricos, como las huellas dactilares. Mientras que una contraseña puede cambiarse tras una filtración para mitigar el daño, esto es imposible con los datos biométricos, lo que genera un riesgo permanente para el usuario afectado.
Enumeración de Usuarios
Las vulnerabilidades de enumeración de usuarios ocurren cuando una aplicación web responde de manera diferente a entradas de autenticación registradas y válidas frente a entradas inválidas. Estas vulnerabilidades suelen aparecer en funciones que dependen del nombre de usuario, como el inicio de sesión (login), el registro y el restablecimiento de contraseña.
Los desarrolladores web frecuentemente pasan por alto los vectores de enumeración, asumiendo que información como los nombres de usuario no es confidencial. Sin embargo, los nombres de usuario pueden considerarse confidenciales si son el identificador principal requerido para la autenticación. Además, los usuarios tienden a reutilizar el mismo nombre de usuario en diversos servicios (aplicaciones web, FTP, RDP y SSH). Dado que muchas aplicaciones web permiten identificar nombres de usuario, podemos enumerar cuentas válidas y utilizarlas para ataques posteriores contra la autenticación. Esto es posible porque las aplicaciones web suelen usar el nombre de usuario o el correo electrónico como identificador principal.
Teoría de la Enumeración de Usuarios
La protección contra ataques de enumeración de nombres de usuario puede afectar negativamente la experiencia del usuario (UX). Una aplicación web que revela si un nombre de usuario existe puede ayudar a un usuario legítimo a identificar si escribió mal su nombre. No obstante, lo mismo aplica para un atacante que intenta determinar cuentas válidas.
Incluso aplicaciones maduras y conocidas, como WordPress, permiten la enumeración de usuarios de forma predeterminada. Por ejemplo, si intentamos iniciar sesión en WordPress con un nombre de usuario inválido, recibimos el siguiente mensaje de error:
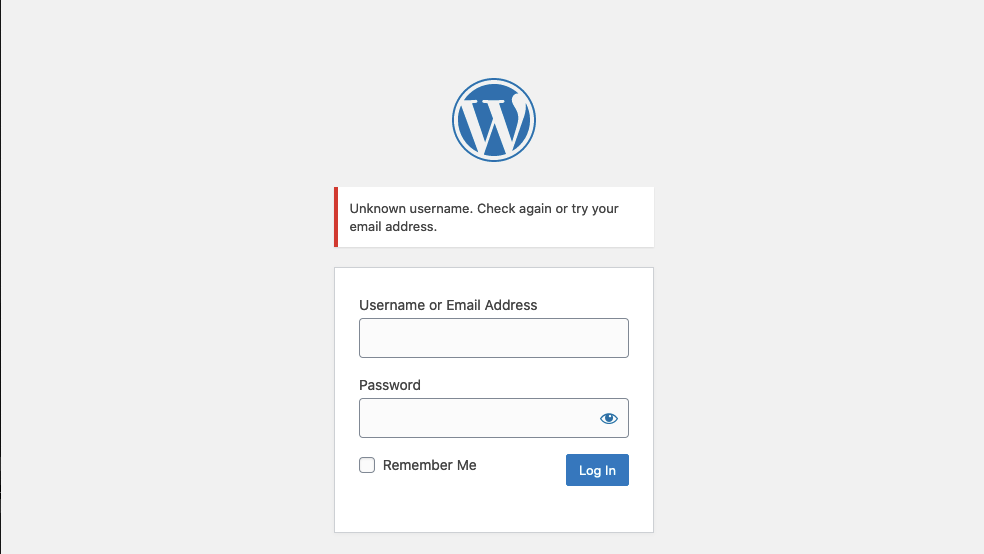
Por otro lado, un nombre de usuario válido da lugar a un mensaje de error diferente:
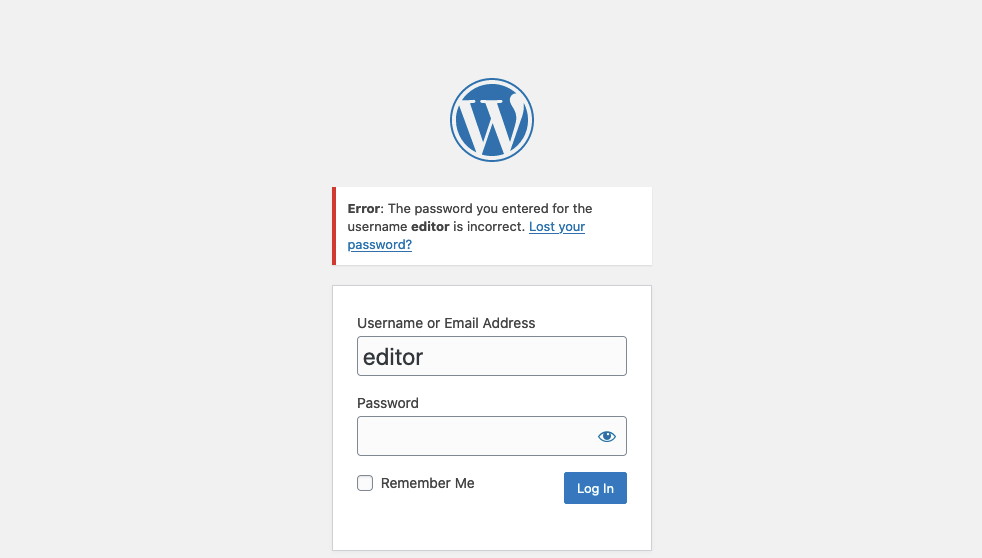
Enumeración de Usuarios mediante Mensajes de Error Diferenciados
Para obtener una lista de usuarios válidos, un atacante normalmente requiere una lista de palabras (wordlist) de nombres de usuario para probar. Los nombres de usuario suelen ser mucho menos complicados que las contraseñas; rara vez contienen caracteres especiales cuando no son direcciones de correo electrónico.
Una lista de usuarios comunes permite a un atacante reducir el alcance de un ataque de fuerza bruta o llevar a cabo ataques dirigidos (aprovechando OSINT) contra empleados de soporte o usuarios específicos. Además, se podría realizar un ataque de password spraying (probar una contraseña común contra muchas cuentas válidas), lo que a menudo conduce al compromiso exitoso de una cuenta.
Otros métodos para recolectar nombres de usuario incluyen el rastreo (crawling) de una aplicación web o la utilización de información disponible públicamente, como perfiles de empresa en redes sociales. Un buen punto de partida es la colección de listas de palabras SecLists.
Enumeración de Usuarios mediante Ataques de Canal Lateral (Side-Channel)
Aunque las diferencias en las respuestas de la aplicación web son la forma más sencilla y obvia de enumerar nombres de usuario válidos, también podemos ser capaces de enumerarlos a través de canales laterales. Los ataques de canal lateral no apuntan directamente al contenido de la respuesta de la aplicación, sino a información adicional que puede ser obtenida o inferida de ella.
Un ejemplo de canal lateral es el tiempo de respuesta (response timing), es decir, el tiempo que tarda la respuesta de la aplicación web en llegarnos. Supongamos que una aplicación realiza búsquedas en la base de datos únicamente para nombres de usuario válidos; en ese caso, podríamos medir una diferencia en el tiempo de respuesta y enumerar usuarios de esta manera, incluso si el mensaje de error es idéntico para todos.
Fuerza Bruta de Contraseñas
Las contraseñas siguen siendo uno de los métodos de autenticación en línea más comunes, pero están plagadas de problemas. Un problema prominente es la reutilización de contraseñas, donde los individuos usan la misma clave en múltiples cuentas. Esta práctica representa un riesgo de seguridad significativo porque, si una cuenta se ve comprometida, los atacantes pueden potencialmente obtener acceso a otras cuentas con las mismas credenciales.
La reutilización de contraseñas permite que un atacante, tras obtener una lista de contraseñas de una filtración de datos, pruebe esas mismas claves en otras aplicaciones web (técnica conocida como “Password Spraying”). Otro problema es el uso de contraseñas débiles basadas en frases típicas, palabras de diccionario o patrones simples. Estas contraseñas son vulnerables a ataques de fuerza bruta, donde herramientas automatizadas prueban sistemáticamente diferentes combinaciones hasta encontrar la correcta, comprometiendo la seguridad de la cuenta.
Fuerza Bruta de Contraseñas (Optimización)
El éxito de un ataque de fuerza bruta depende enteramente del número de intentos que un atacante pueda realizar y del tiempo que tarde en completarlos. Por ello, es crucial asegurarse de utilizar una buena lista de palabras (wordlist). Si una aplicación web aplica una política de contraseñas, debemos asegurarnos de que nuestra wordlist solo contenga contraseñas que cumplan con dicha política. De lo contrario, estaremos perdiendo tiempo valioso con contraseñas que los usuarios no podrían usar, ya que la política no las permitiría.
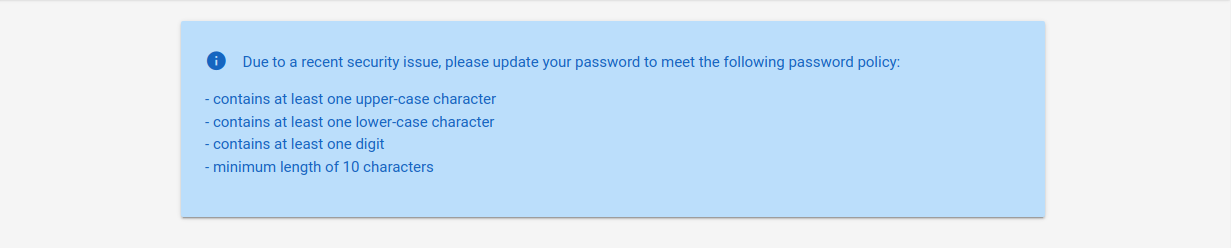
Por ejemplo, la popular wordlist rockyou.txt contiene más de 14 millones de contraseñas:
Bash
1
2
$ wc -l /opt/useful/seclists/Passwords/Leaked-Databases/rockyou.txt
14344391 /opt/useful/seclists/Passwords/Leaked-Databases/rockyou.txt
Ahora, podemos usar grep para filtrar únicamente aquellas contraseñas que coincidan con la política implementada por nuestro objetivo (por ejemplo: mínimo 10 caracteres, mayúsculas, minúsculas y números). Esto reduce la lista a unas 150,000 contraseñas, una reducción del 99%:
Bash
1
2
3
4
$ grep '[[:upper:]]' /opt/useful/seclists/Passwords/Leaked-Databases/rockyou.txt | grep '[[:lower:]]' | grep '[[:digit:]]' | grep -E '.{10}' > custom_wordlist.txt
$ wc -l custom_wordlist.txt
151647 custom_wordlist.txt
Alternativamente, podemos combinar los parámetros de búsqueda en un solo comando de awk:
Bash
1
$ awk 'length($0) >= 10 && /[a-z]/ && /[A-Z]/ && /[0-9]/' /opt/useful/seclists/Passwords/Leaked-Databases/rockyou.txt > custom_wordlist.txt
Para comenzar la fuerza bruta, necesitamos un usuario o una lista de usuarios objetivo.

Al proporcionar un nombre de usuario incorrecto, la respuesta de inicio de sesión contiene el mensaje (subcadena) «Nombre de usuario no válido», por lo tanto, podemos utilizar esta información para crear nuestro comando ffuf y realizar un ataque de fuerza bruta a la contraseña del usuario:
1
2
3
4
5
6
$ ffuf -w ./custom_wordlist.txt -u http://172.17.0.2/index.php -X POST -H "Content-Type: application/x-www-form-urlencoded" -d "username=admin&password=FUZZ" -fr "Invalid username"
<SNIP>
[Status: 302, Size: 0, Words: 1, Lines: 1, Duration: 4764ms]
* FUZZ: Buttercup1
Brute-Forcing Password Reset Tokens
Ataques a la Recuperación de Contraseña
Muchas aplicaciones web implementan una funcionalidad de recuperación de contraseña en caso de que un usuario la olvide. Esta funcionalidad normalmente se basa en un token de restablecimiento de un solo uso, que se transmite al usuario, por ejemplo, a través de SMS o correo electrónico. El usuario puede entonces autenticarse utilizando este token, lo que le permite restablecer su contraseña y acceder a su cuenta.
Como tal, un token de restablecimiento débil puede ser forzado por fuerza bruta o predicho por un atacante para obtener acceso no autorizado a la cuenta de una víctima.
Identificación de Tokens de Restablecimiento Débiles
Los tokens de restablecimiento (ya sea en forma de código o contraseña temporal) son datos secretos generados por una aplicación cuando un usuario solicita un cambio de contraseña. El usuario puede entonces cambiar su clave presentando dicho token.
Dado que los tokens de restablecimiento permiten a un atacante cambiar la contraseña de una cuenta sin conocer la original, pueden aprovecharse como un vector de ataque para la toma de control de cuentas si se implementan incorrectamente. Los flujos de restablecimiento de contraseña pueden ser complicados porque consisten en varios pasos secuenciales.
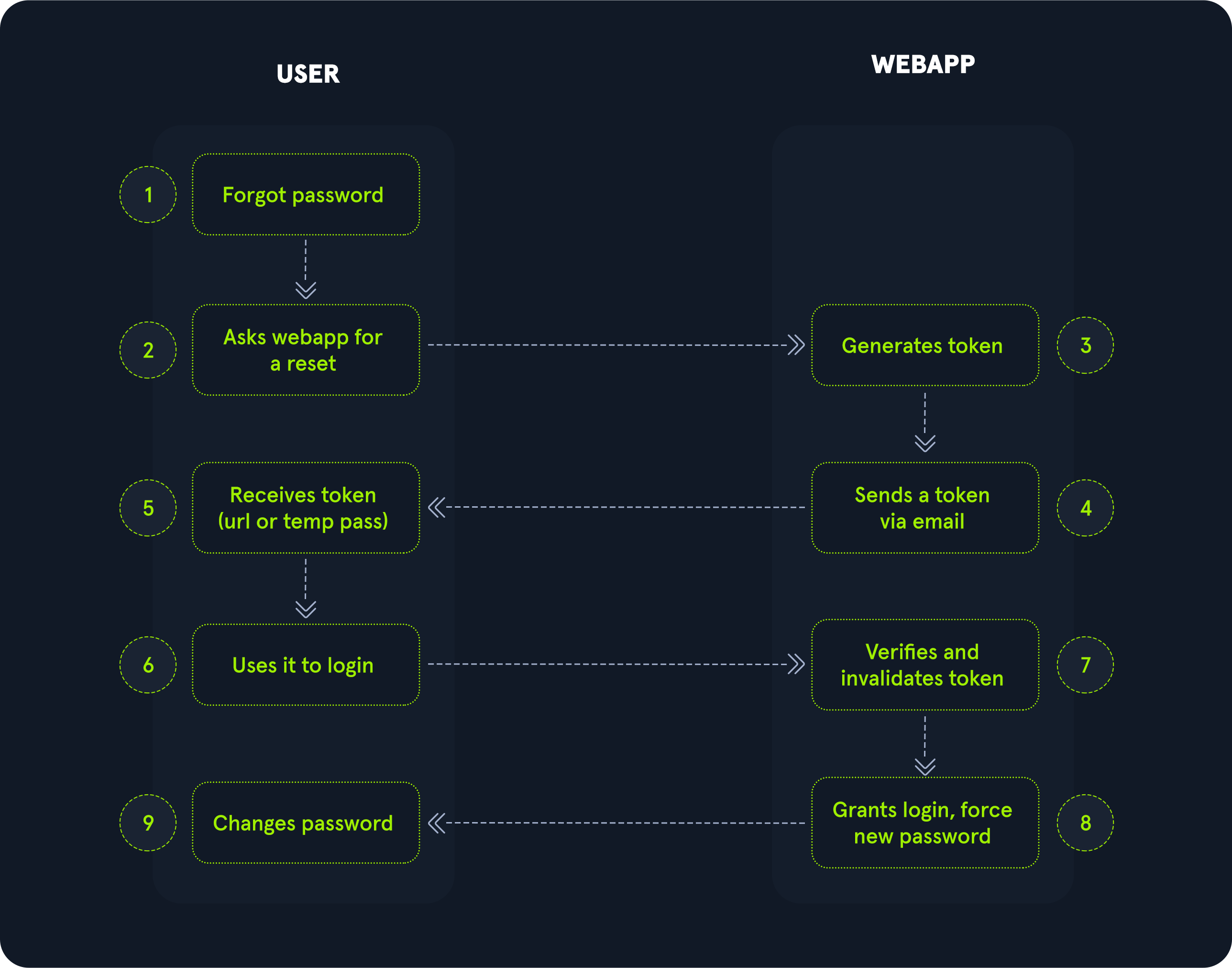
Atacando tokens débiles
Usaremos ffuf para aplicar fuerza bruta a todos los tokens de restablecimiento posibles. Primero, necesitamos crear una lista de palabras con todos los tokens posibles, desde 0000 hasta 9999, lo cual podemos lograr con seq:
1
$ seq -w 0 9999 > tokens.txt
La bandera -w rellena todos los números con la misma longitud añadiendo ceros al principio, lo que podemos verificar mirando las primeras líneas del archivo de salida:
1
2
3
4
5
6
7
8
9
10
11
12
$ head tokens.txt
0000
0001
0002
0003
0004
0005
0006
0007
0008
0009
Suponiendo que hay usuarios que están actualmente en proceso de restablecer sus contraseñas, podemos intentar aplicar fuerza bruta a todos los tokens de restablecimiento activos. Si queremos centrarnos en un usuario específico, primero debemos enviar una solicitud de restablecimiento de contraseña para ese usuario con el fin de crear un token de restablecimiento. A continuación, podemos especificar la lista de palabras en ffuf para aplicar fuerza bruta a todos los tokens de restablecimiento activos:
1
2
3
4
5
6
$ ffuf -w ./tokens.txt -u http://weak_reset.htb/reset_password.php?token=FUZZ -fr "The provided token is invalid"
<SNIP>
[Status: 200, Size: 2667, Words: 538, Lines: 90, Duration: 1ms]
* FUZZ: 6182
Al especificar el token de restablecimiento en el parámetro GET token en el punto final /reset_password.php, podemos restablecer la contraseña de la cuenta correspondiente, lo que nos permite tomar el control de la cuenta:
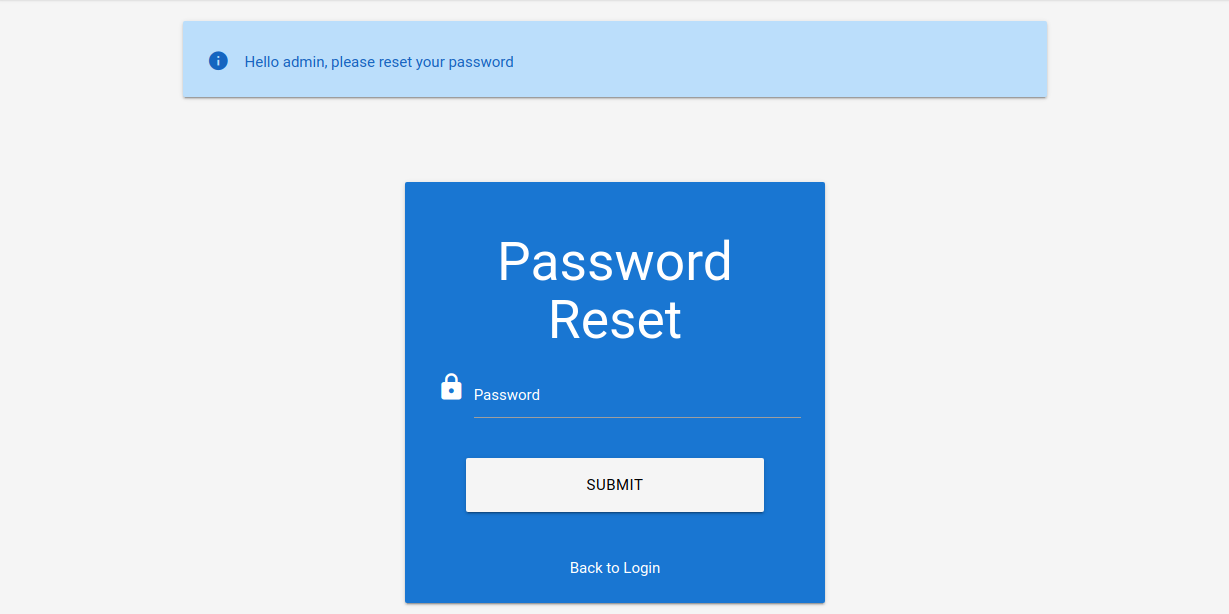
Brute-Forcing 2FA Codes
La autenticación de dos factores (2FA) proporciona una capa adicional de seguridad para proteger las cuentas de los usuarios contra el acceso no autorizado. Por lo general, esto se logra combinando la autenticación basada en el conocimiento (como una contraseña) con la autenticación basada en la propiedad (utilizando un dispositivo 2FA).
Sin embargo, la 2FA también se puede lograr combinando dos de las tres categorías principales de autenticación que hemos comentado anteriormente. Por lo tanto, la 2FA dificulta considerablemente el acceso de los atacantes a una cuenta, incluso si logran obtener las credenciales del usuario. Al exigir a los usuarios que proporcionen una segunda forma de autenticación, como un código de un solo uso generado por una aplicación de autenticación o enviado por SMS, la 2FA mitiga el riesgo de acceso no autorizado. Esta capa adicional de seguridad mejora significativamente la postura de seguridad general de una cuenta, reduciendo la probabilidad de que se produzcan violaciones de la misma.
Atacando Two-Factor Authentication (2FA)
Una de las implementaciones más comunes de la autenticación de dos factores (2FA) se basa en la contraseña del usuario y una contraseña de un solo uso basada en el tiempo (TOTP) que se envía al smartphone del usuario mediante una aplicación de autenticación o por SMS.
Estas TOTP suelen estar compuestas únicamente por dígitos, lo que las hace potencialmente adivinables si la longitud es insuficiente y la aplicación web no implementa medidas contra el envío sucesivo de TOTP incorrectas. Supondremos que hemos obtenido credenciales válidas en un ataque de phishing anterior: admin:admin. Sin embargo, la aplicación web está protegida con 2FA, como podemos ver después de iniciar sesión con las credenciales obtenidas:
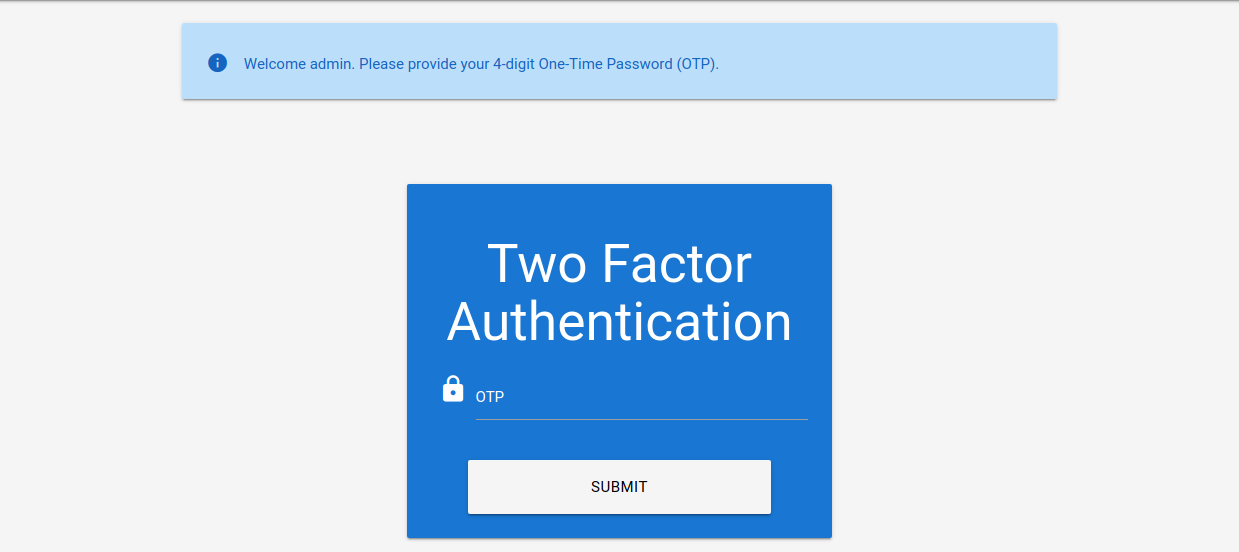
El mensaje de la aplicación web indica que el TOTP es un código de 4 dígitos. Dado que solo hay 10 000 variaciones posibles, podemos probar fácilmente todos los códigos posibles. Para ello, veamos primero la solicitud correspondiente para preparar nuestros parámetros para ffuf:

Como podemos ver, el TOTP se pasa en el parámetro POST otp. Además, necesitamos especificar nuestro token de sesión en la cookie PHPSESSID para asociar el TOTP con nuestra sesión autenticada. Al igual que en la sección anterior, podemos generar una lista de palabras que contenga todos los números de 4 dígitos del 0000 al 9999 de la siguiente manera:
1
$ seq -w 0 9999 > tokens.txt
Después, podemos utilizar el siguiente comando para forzar por fuerza bruta el TOTP correcto filtrando las respuestas que contienen el mensaje de error «Código 2FA no válido»:
1
2
3
4
5
6
7
8
9
10
11
$ ffuf -w ./tokens.txt -u http://bf_2fa.htb/2fa.php -X POST -H "Content-Type: application/x-www-form-urlencoded" -b "PHPSESSID=fpfcm5b8dh1ibfa7idg0he7l93" -d "otp=FUZZ" -fr "Invalid 2FA Code"
<SNIP>
[Status: 302, Size: 0, Words: 1, Lines: 1, Duration: 648ms]
* FUZZ: 6513
[Status: 302, Size: 0, Words: 1, Lines: 1, Duration: 635ms]
* FUZZ: 6514
<SNIP>
[Status: 302, Size: 0, Words: 1, Lines: 1, Duration: 1ms]
* FUZZ: 9999
Como podemos ver, obtenemos muchos resultados. Esto se debe a que nuestra sesión superó con éxito la verificación 2FA después de haber proporcionado el TOTP correcto. Dado que 6513 fue el primer resultado, podemos suponer que este era el TOTP correcto. A continuación, nuestra sesión se marca como totalmente autenticada, por lo que todas las solicitudes que utilizan nuestra cookie de sesión se redirigen a /admin.php. Para acceder a la página protegida, solo tenemos que acceder al punto final /admin.php en un navegador web y verificar que hemos superado con éxito la 2FA.
Protección Débil contra Fuerza Bruta
Los mecanismos más comunes son los límites de tasa (rate limits) y los CAPTCHAs.
Límites de Tasa (Rate Limits)
El rate limiting es una técnica crucial para controlar la frecuencia de solicitudes entrantes a un sistema o API. Su propósito principal es evitar que los servidores se saturen, prevenir tiempos de inactividad y proteger contra ataques de fuerza bruta.
Funcionamiento: Establece un umbral máximo de solicitudes en un periodo de tiempo determinado.
Efecto en el ataque: Cuando un atacante alcanza el límite, el sistema suele incrementar el tiempo de respuesta de forma iterativa hasta que el ataque sea inviable, o bloquea el acceso por un periodo específico.
Identificación del atacante: Muchos sistemas usan la dirección IP para identificar al agresor. Sin embargo, si existen proxies inversos, balanceadores de carga o cachés web, la IP de origen será la del intermediario y no la del atacante.
Vulnerabilidad de Bypass: Algunos sistemas confían en encabezados HTTP como
X-Forwarded-Forpara obtener la IP real. Un atacante puede manipular estos encabezados, aleatorizando el valor deX-Forwarded-Foren cada solicitud para evadir el límite por completo, como se vio en la vulnerabilidad CVE-2020-35590.
CAPTCHAs
Un CAPTCHA es una medida de seguridad diseñada para distinguir entre humanos y bots. Al obligar a que las solicitudes sean realizadas por humanos, los ataques de fuerza bruta se convierten en una tarea manual, volviéndolos inviables en la mayoría de los casos.
Desafíos comunes: Identificar texto distorsionado, seleccionar objetos en imágenes o resolver acertijos simples.
Propósito: Evitar acciones automatizadas dañinas como el spam, la creación de cuentas falsas o ataques en páginas de inicio de sesión.
Punto ciego de seguridad: Es fundamental no revelar la solución del CAPTCHA en la respuesta HTTP, ya que una implementación defectuosa permitiría a un script leer la respuesta y resolver el desafío automáticamente.
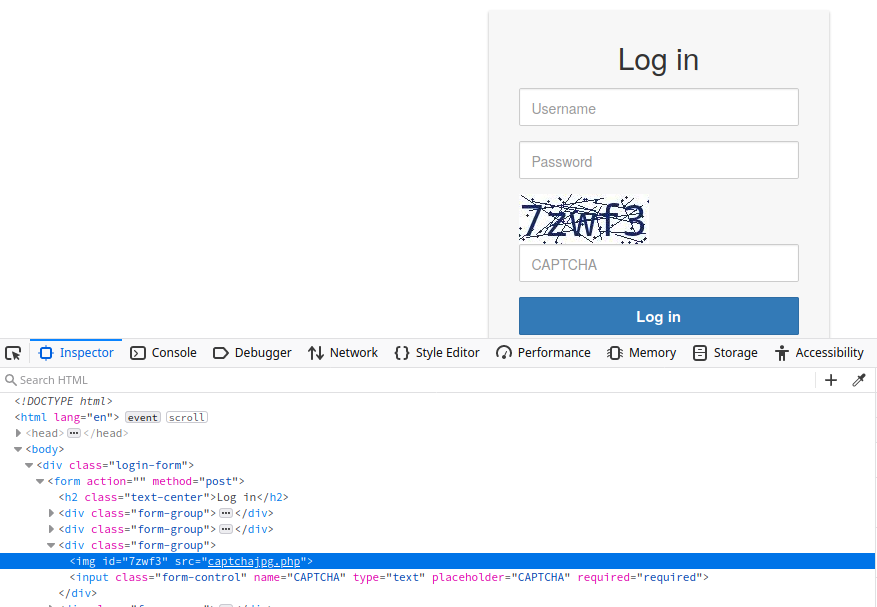
Además, cada vez son más frecuentes las herramientas y extensiones de navegador que resuelven los CAPTCHA automáticamente. Existen muchos solucionadores de CAPTCHA de código abierto disponibles. En particular, el auge de las herramientas basadas en inteligencia artificial proporciona capacidades de resolución de CAPTCHA mediante el uso de potentes modelos de aprendizaje automático de reconocimiento de imágenes o reconocimiento de voz.
Credenciales por defecto
Muchas aplicaciones web se configuran con credenciales predeterminadas para permitir el acceso tras la instalación. Sin embargo, estas credenciales deben cambiarse tras la configuración inicial de la aplicación web; de lo contrario, facilitan a los atacantes la obtención de acceso autenticado. Por ello, la comprobación de credenciales predeterminadas es una parte esencial de las pruebas de autenticación de la Guía de pruebas de seguridad de aplicaciones web de OWASP. Según OWASP, las credenciales predeterminadas más comunes son «admin» y «password».
Probando credenciales por defecto
Muchas plataformas proporcionan listas de credenciales predeterminadas para una amplia variedad de aplicaciones web. Un ejemplo de ello es la base de datos web mantenida por CIRT.net. Por ejemplo, si identificamos un dispositivo Cisco durante una prueba de penetración, podemos buscar en la base de datos las credenciales predeterminadas para los dispositivos Cisco:
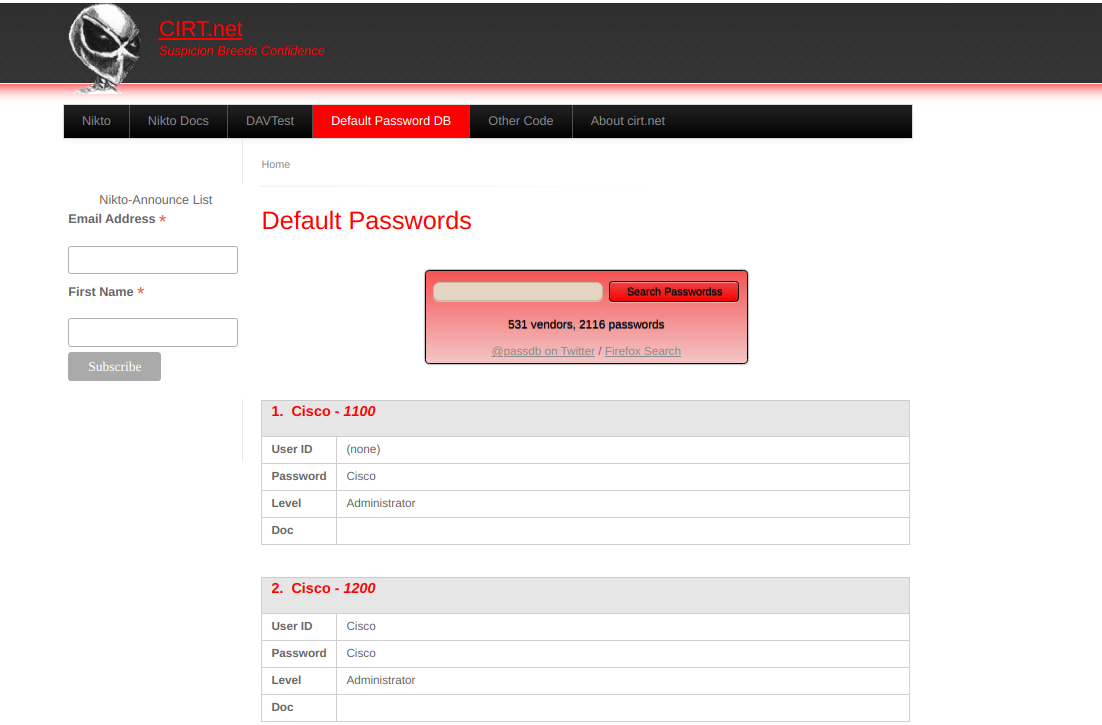
Otros recursos incluyen SecLists Default Credentials, así como el repositorio SCADA GitHub, que contiene una lista de contraseñas predeterminadas para una variedad de proveedores diferentes.
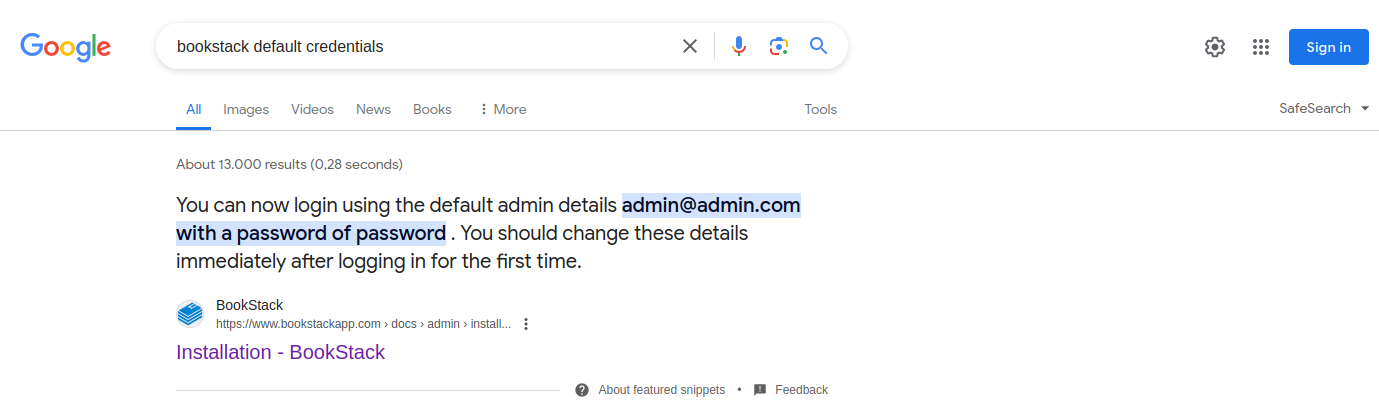
Una búsqueda específica en Internet es otra forma de obtener credenciales predeterminadas para una aplicación web. Supongamos que nos topamos con una aplicación web BookStack durante una intervención:
Podemos intentar buscar las credenciales predeterminadas buscando algo como «credenciales predeterminadas de Bookstack»:
Password reset vulnerable
A menudo, las aplicaciones web autentican a los usuarios que han perdido sus contraseñas pidiéndoles que respondan a una o varias preguntas de seguridad. Durante el registro, los usuarios proporcionan respuestas a preguntas de seguridad predefinidas y genéricas, sin permitirles introducir preguntas personalizadas. Por lo tanto, dentro de la misma aplicación web, las preguntas de seguridad de todos los usuarios serán las mismas, lo que permitirá a los atacantes abusar de ellas.
Suponiendo que hubiéramos encontrado dicha funcionalidad en un sitio web objetivo, deberíamos intentar explotarla para eludir la autenticación. A menudo, el eslabón débil en una funcionalidad de restablecimiento de contraseña basada en preguntas es la previsibilidad de las respuestas. Es habitual encontrar preguntas como las siguientes:
«¿Cuál es el apellido de soltera de tu madre?»
«¿En qué ciudad naciste?»
Aunque estas preguntas parecen estar vinculadas al usuario individual, a menudo se pueden obtener a través de OSINT o adivinar, si se realiza un número suficiente de intentos, es decir, si no hay protección contra ataques de fuerza bruta.
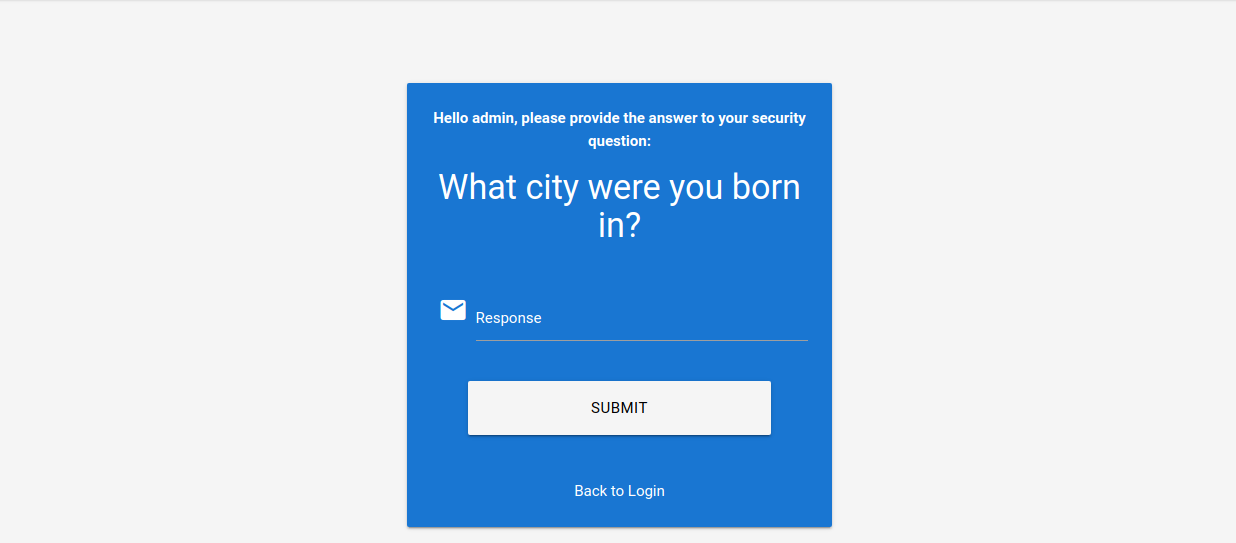
Podemos intentar resolver esta pregunta por fuerza bruta utilizando una lista de palabras adecuada. Existen múltiples listas que contienen las grandes ciudades de todo el mundo. Por ejemplo, este archivo CSV contiene una lista de más de 25 000 ciudades con más de 15 000 habitantes de todo el mundo. Este es un excelente punto de partida para resolver por fuerza bruta la ciudad en la que nació un usuario.
Dado que el archivo CSV contiene el nombre de la ciudad en el primer campo, podemos crear nuestra lista de palabras que contenga solo el nombre de la ciudad en cada línea utilizando el siguiente comando:
1
$ cat world-cities.csv | cut -d ',' -f1 > city_wordlist.txt
1
2
3
$ wc -l city_wordlist.txt
26468 city_wordlist.txt
Como podemos ver, esto da como resultado un total de 26 468 ciudades.
Para configurar nuestro ataque de fuerza bruta, primero debemos especificar el usuario al que queremos atacar. Como ejemplo, nos centraremos en el usuario admin. Después de especificar el nombre de usuario, debemos responder a la pregunta de seguridad del usuario. La solicitud correspondiente tiene el siguiente aspecto:

Podemos configurar el comando ffuf correspondiente a partir de esta solicitud para forzar la respuesta. Ten en cuenta que debemos especificar nuestra cookie de sesión para asociar nuestra solicitud con el nombre de usuario admin:
1
2
3
4
5
6
$ ffuf -w ./city_wordlist.txt -u http://pwreset.htb/security_question.php -X POST -H "Content-Type: application/x-www-form-urlencoded" -b "PHPSESSID=39b54j201u3rhu4tab1pvdb4pv" -d "security_response=FUZZ" -fr "Incorrect response."
<SNIP>
[Status: 302, Size: 0, Words: 1, Lines: 1, Duration: 0ms]
* FUZZ: Houston
Podríamos reducir el número de ciudades si tuviéramos información adicional sobre nuestro objetivo para reducir el tiempo necesario para nuestro ataque de fuerza bruta a la pregunta de seguridad. Por ejemplo, si supiéramos que nuestro usuario objetivo es de Alemania, podríamos crear una lista de palabras que contuviera solo ciudades alemanas, reduciendo el número a unas mil ciudades:
1
$ cat world-cities.csv | grep Germany | cut -d ',' -f1 > german_cities.txt
1
2
3
$ wc -l german_cities.txt
1117 german_cities.txt
Manipulación de la solicitud de restablecimiento
Otro ejemplo de una lógica defectuosa para restablecer contraseñas se produce cuando un usuario puede manipular un parámetro potencialmente oculto para restablecer la contraseña de otra cuenta.
Utilizaremos nuestra cuenta de demostración example, lo que da como resultado la siguiente solicitud:
1
2
3
4
5
6
7
POST /reset.php HTTP/1.1
Host: pwreset.test
Content-Length: 18
Content-Type: application/x-www-form-urlencoded
Cookie: PHPSESSID=39b54j201u3rhu4tab1pvdb4pv
username=example
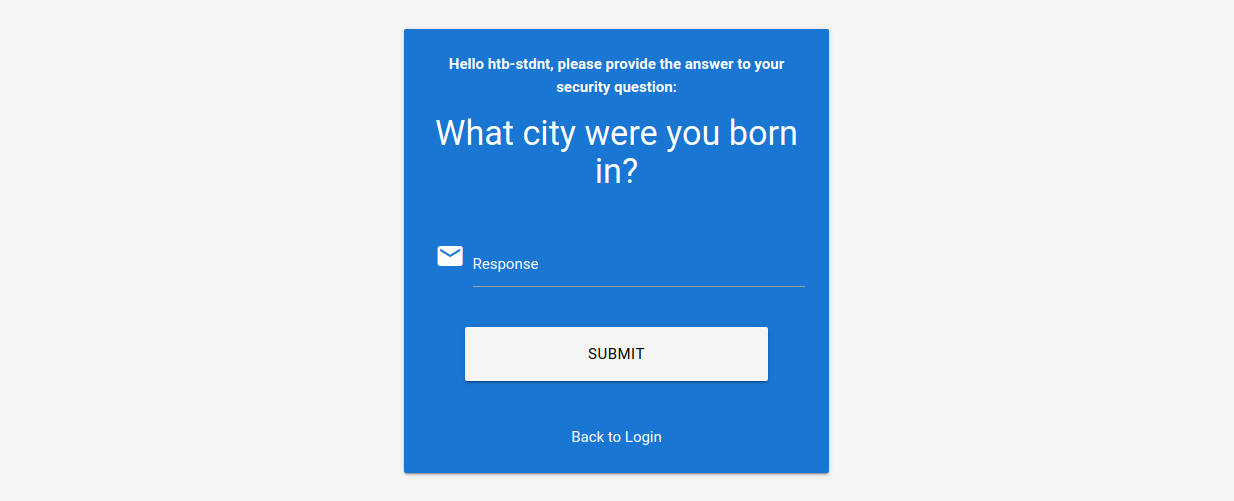
El suministro de la respuesta de seguridad de Londres da lugar a la siguiente solicitud:
1
2
3
4
5
6
7
POST /security_question.php HTTP/1.1
Host: pwreset.test
Content-Length: 43
Content-Type: application/x-www-form-urlencoded
Cookie: PHPSESSID=39b54j201u3rhu4tab1pvdb4pv
security_response=London&username=example
Como podemos ver, el nombre de usuario está incluido en el formulario como un parámetro oculto y se envía junto con la respuesta de seguridad. Por último, podemos restablecer la contraseña del usuario.
1
2
3
4
5
6
7
POST /reset_password.php HTTP/1.1
Host: pwreset.test
Content-Length: 36
Content-Type: application/x-www-form-urlencoded
Cookie: PHPSESSID=39b54j201u3rhu4tab1pvdb4pv
password=P@$$w0rd&username=example
Al igual que la solicitud anterior, la solicitud contiene el nombre de usuario en un parámetro POST independiente. Supongamos que la aplicación web no verifica correctamente que los nombres de usuario de ambas solicitudes coincidan. En ese caso, podemos omitir la pregunta de seguridad o proporcionar la respuesta a nuestra pregunta de seguridad y, a continuación, establecer la contraseña de una cuenta completamente diferente. Por ejemplo, podemos cambiar la contraseña del usuario administrador manipulando el parámetro de nombre de usuario de la solicitud de restablecimiento de contraseña:
1
2
3
4
5
6
7
POST /reset_password.php HTTP/1.1
Host: pwreset.test
Content-Length: 32
Content-Type: application/x-www-form-urlencoded
Cookie: PHPSESSID=39b54j201u3rhu4tab1pvdb4pv
password=P@$$w0rd&username=admin
Bypass de autenticación
Acceso directo
La forma más sencilla de eludir los controles de autenticación es solicitar el recurso protegido directamente desde un contexto no autenticado. Un atacante no autenticado puede acceder a información protegida si la aplicación web no verifica correctamente que la solicitud esté autenticada.
Por ejemplo, supongamos que sabemos que la aplicación web redirige a los usuarios al punto final /admin.php tras una autenticación satisfactoria, proporcionando información protegida solo a los usuarios autenticados. Si la aplicación web se basa únicamente en la página de inicio de sesión para autenticar a los usuarios, podemos acceder al recurso protegido directamente accediendo al punto final /admin.php.
Aunque este escenario es poco habitual en el mundo real, en ocasiones se produce una ligera variante en aplicaciones web vulnerables. Supongamos que una aplicación web utiliza el siguiente fragmento de código PHP para verificar si un usuario está autenticado:
1
2
3
if(!$_SESSION['active']) {
header("Location: index.php");
}
Este código redirige al usuario a /index.php si la sesión no está activa, es decir, si el usuario no está autenticado. Sin embargo, el script PHP no detiene la ejecución, lo que da como resultado que la información protegida dentro de la página se envíe en el cuerpo de la respuesta.
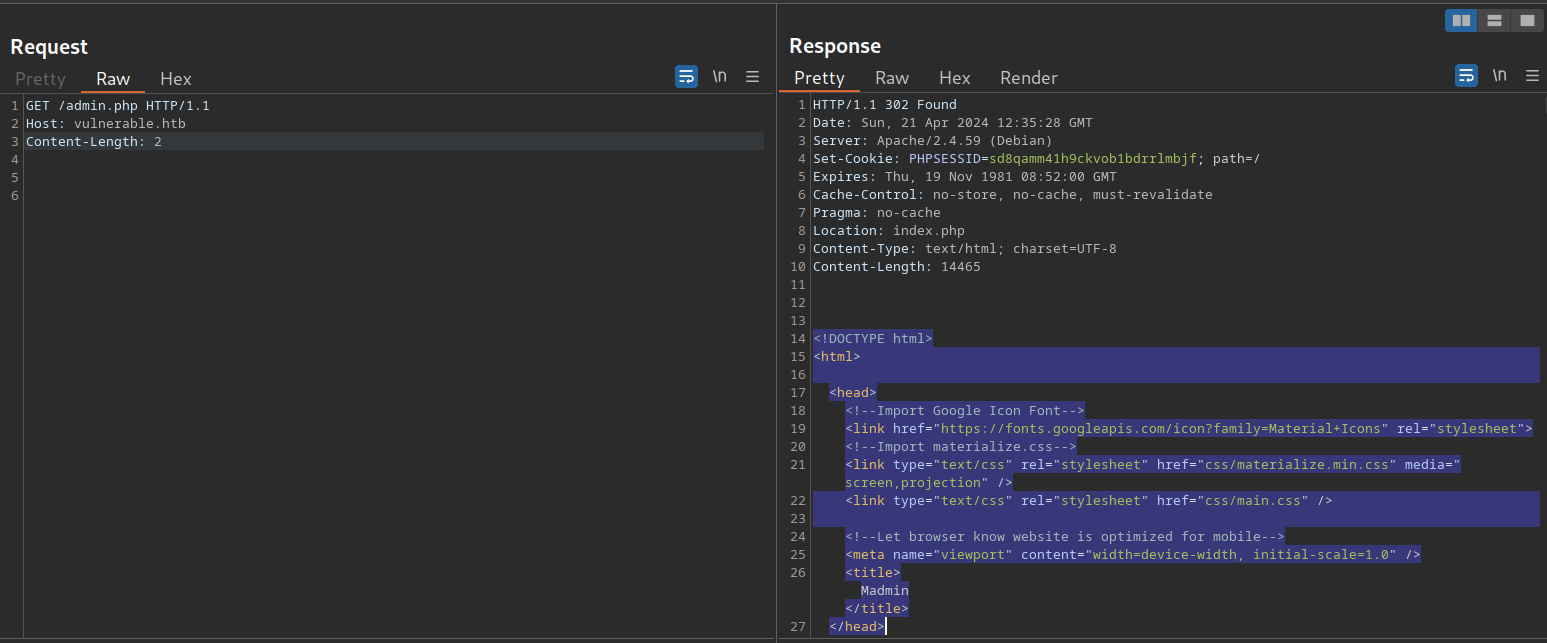
Como podemos ver, toda la página de administración está contenida en el cuerpo de la respuesta. Sin embargo, si intentamos acceder a la página en nuestro navegador web, este sigue la redirección y muestra el mensaje de inicio de sesión en lugar de la página de administración protegida. Podemos engañar fácilmente al navegador para que muestre la página de administración interceptando la respuesta y cambiando el código de estado de 302 a 200. Para ello, habilite Intercept en Burp. A continuación, navegue hasta el punto final /admin.php en el navegador web. A continuación, haga clic con el botón derecho del ratón en la solicitud y seleccione Do intercept > Response to this request para interceptar la respuesta:
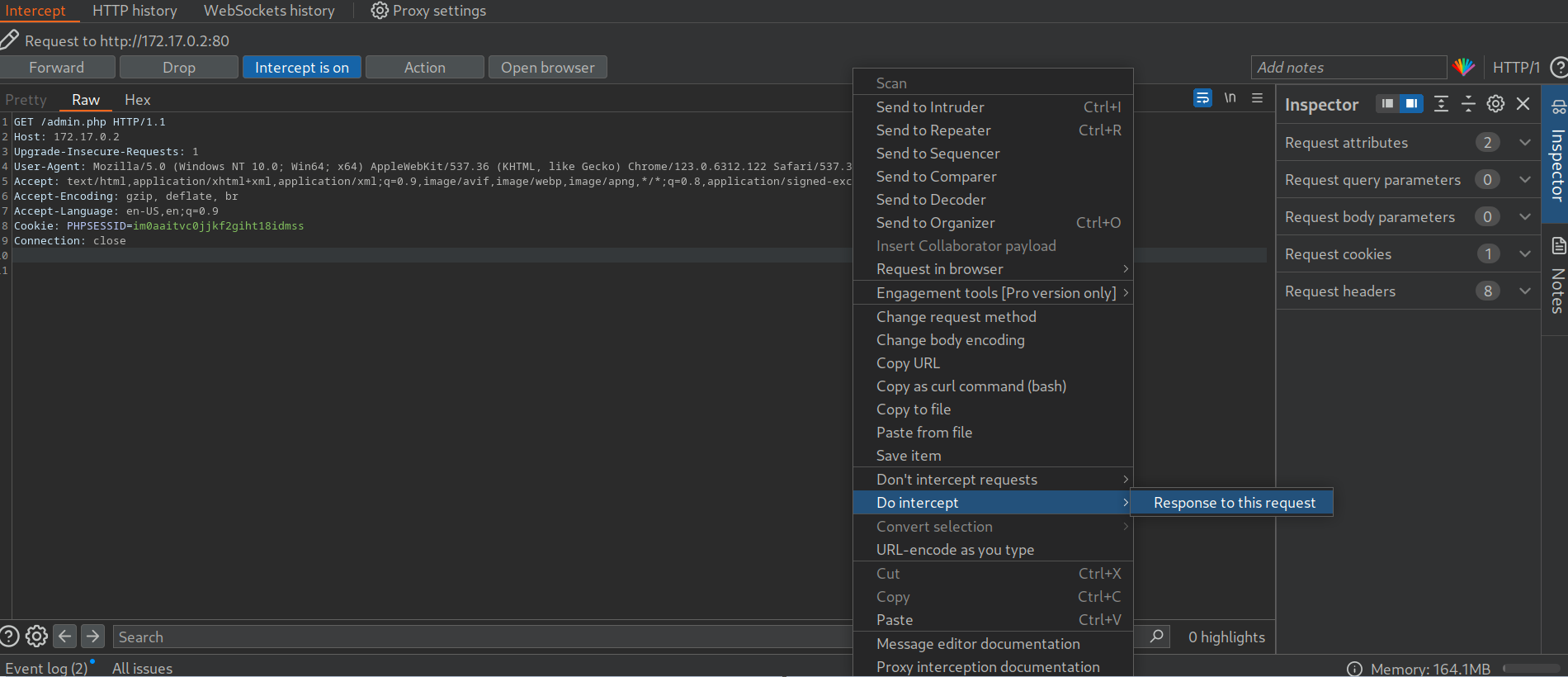
A continuación, reenviamos la solicitud haciendo clic en “Reenviar”. Como hemos interceptado la respuesta, ahora podemos editarla. Para obligar al navegador a mostrar el contenido, debemos cambiar el código de estado de 302 Encontrado a 200 OK:

Después, podemos reenviar la respuesta. Si volvemos a la ventana del navegador, podemos ver que la información protegida se muestra:
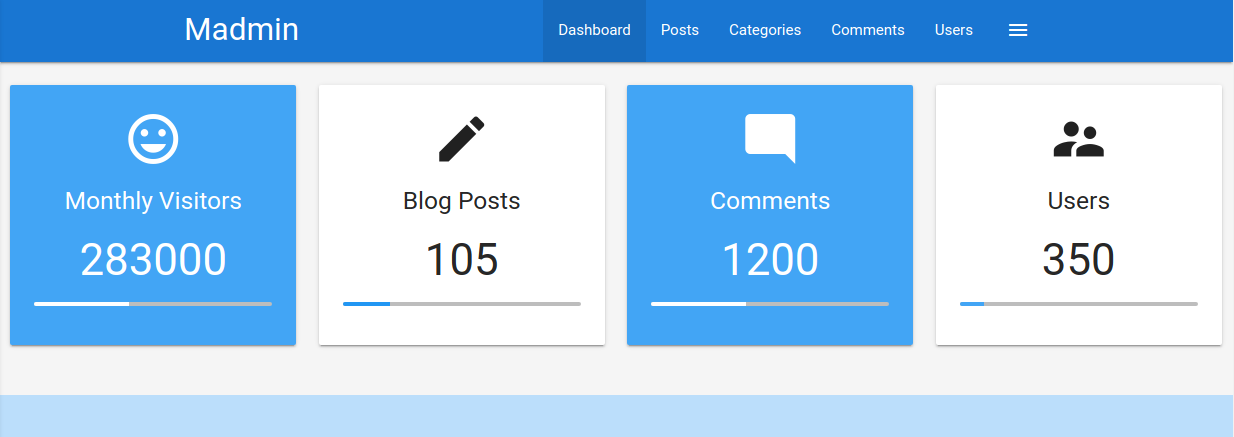
Para evitar que la información protegida se devuelva en el cuerpo de la respuesta de redireccionamiento, el script PHP debe salir después de emitir el redireccionamiento:
1
2
3
4
if(!$_SESSION['active']) {
header("Location: index.php");
exit;
}
Modificación de parámetros
Una implementación de autenticación puede ser defectuosa si depende de la presencia o el valor de un parámetro HTTP, lo que introduce vulnerabilidades de autenticación.
Este tipo de vulnerabilidad está estrechamente relacionada con problemas de autorización, como las vulnerabilidades de referencia directa a objetos inseguros (IDOR).
En esta ocasión, se nos proporcionan las credenciales del usuario htb-stdnt. Tras iniciar sesión, se nos redirige a /admin.php?user_id=183:

En nuestro navegador web, podemos ver que parece que nos faltan privilegios, ya que solo podemos ver una parte de los datos disponibles:
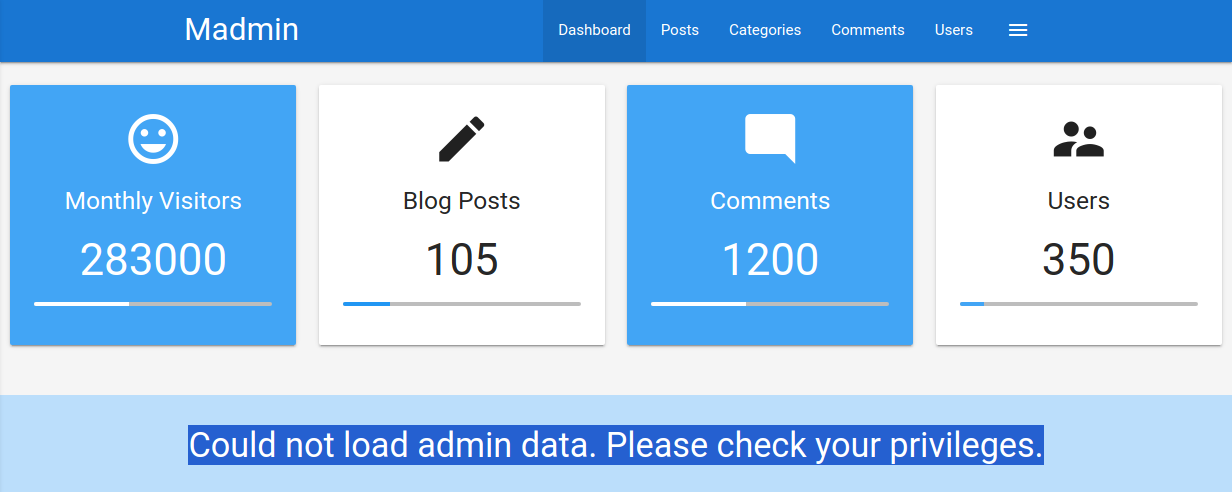
Para investigar la finalidad del parámetro user_id, vamos a eliminarlo de nuestra solicitud a /admin.php. Al hacerlo, se nos redirige de nuevo a la pantalla de inicio de sesión en /index.php, aunque nuestra sesión proporcionada en la cookie PHPSESSID sigue siendo válida:

Por lo tanto, podemos suponer que el parámetro user_id está relacionado con la autenticación. Podemos omitir la autenticación por completo accediendo directamente a la URL /admin.php?user_id=183:

Basándonos en el nombre del parámetro user_id, podemos deducir que el parámetro especifica el ID del usuario que accede a la página. Si podemos adivinar o forzar el ID de usuario de un administrador, es posible que podamos acceder a la página con privilegios administrativos, revelando así la información del administrador.
Tokens de sesión
Las vulnerabilidades relacionadas con la autenticación pueden surgir no solo de la implementación de la autenticación en sí, sino también del manejo de los tokens de sesión. Los tokens de sesión son identificadores únicos que una aplicación web utiliza para identificar a un usuario. Más concretamente, el token de sesión está vinculado a la sesión del usuario. Si un atacante puede obtener un token de sesión válido de otro usuario, puede suplantar al usuario en la aplicación web, apropiándose así de su sesión.
Brute Force
Supongamos que un token de sesión no proporciona suficiente aleatoriedad y es criptográficamente débil. En ese caso, podemos aplicar fuerza bruta a los tokens de sesión válidos de forma similar a como pudimos aplicar fuerza bruta a los tokens válidos de restablecimiento de contraseña. Esto puede ocurrir si un token de sesión es demasiado corto o contiene datos estáticos que no proporcionan aleatoriedad al token, es decir, el token proporciona una entropía insuficiente.
Consideramos la siguiente aplicación web que asigna un token de sesión de cuatro caracteres:

Una cadena de cuatro caracteres puede ser fácilmente descifrada mediante fuerza bruta. Por lo tanto, podemos utilizar las técnicas y los comandos de fuerza bruta para descifrar todos los tokens de sesión posibles y secuestrar todas las sesiones activas.
Este escenario es relativamente poco común en el mundo real. En una variante ligeramente más común, el token de sesión en sí mismo proporciona una longitud suficiente; sin embargo, el token consta de valores antepuestos y añadidos codificados de forma fija, mientras que solo una pequeña parte del token de sesión es dinámica para proporcionar aleatoriedad. Por ejemplo, consideremos el siguiente token de sesión asignado por una aplicación web:

El token de sesión tiene una longitud de 32 caracteres, por lo que parece inviable enumerar las sesiones válidas de otros usuarios. Sin embargo, enviemos la solicitud de inicio de sesión varias veces y tomemos nota de los tokens de sesión asignados por la aplicación web, lo que da como resultado la siguiente lista de tokens de sesión:
2c0c58b27c71a2ec5bf2b4b6e892b9f9
2c0c58b27c71a2ec5bf2b4546092b9f9
2c0c58b27c71a2ec5bf2b497f592b9f9
2c0c58b27c71a2ec5bf2b48bcf92b9f9
2c0c58b27c71a2ec5bf2b4735e92b9f9
Como podemos ver, todos los tokens de sesión son muy similares. De hecho, de los 32 caracteres, 28 son iguales en las cinco sesiones capturadas. Los tokens de sesión consisten en la cadena estática 2c0c58b27c71a2ec5bf2b4 seguida de cuatro caracteres aleatorios y la cadena estática 92b9f9, lo que reduce la aleatoriedad efectiva de los tokens de sesión. Dado que 28 de los 32 caracteres son estáticos, solo hay cuatro caracteres que necesitamos enumerar para aplicar la fuerza bruta a todas las sesiones activas existentes, lo que nos permite secuestrar todas las sesiones activas.
Otro ejemplo vulnerable sería un identificador de sesión incremental. Por ejemplo, la siguiente captura de tokens de sesión sucesivos:
141233
141234
141237
141238
141240
Como podemos ver, los tokens de sesión parecen ser números incrementales. Esto hace que la enumeración de todas las sesiones pasadas y futuras sea trivial, ya que solo tenemos que incrementar o decrementar nuestro token de sesión para obtener sesiones activas y secuestrar las cuentas de otros usuarios.
Por lo tanto, es fundamental capturar varios tokens de sesión y analizarlos para garantizar que proporcionan suficiente aleatoriedad como para impedir los ataques de fuerza bruta contra ellos.
Tokens de sesión predecibles
En un escenario más realista, el token de sesión proporciona suficiente aleatoriedad en apariencia. Sin embargo, la generación de tokens de sesión no es verdaderamente aleatoria; puede ser predicha por un atacante que conozca la lógica de generación de tokens de sesión.
La forma más simple de tokens de sesión predecibles contiene datos codificados que podemos manipular. Por ejemplo, consideremos el siguiente token de sesión:

Aunque este token de sesión pueda parecer aleatorio a primera vista, un simple análisis revela que se trata de datos codificados en base64:
1
2
3
$ echo -n dXNlcj1odGItc3RkbnQ7cm9sZT11c2Vy | base64 -d
user=htb-stdnt;role=user
Como podemos ver, la cookie contiene información sobre el usuario y el rol vinculado a la sesión. Sin embargo, no existe ninguna medida de seguridad que nos impida manipular los datos. Podemos falsificar nuestro propio token de sesión manipulando los datos y codificándolos en base64 para que coincidan con el formato esperado, lo que nos permite falsificar una cookie de administrador:
1
2
3
$ echo -n 'user=htb-stdnt;role=admin' | base64
dXNlcj1odGItc3RkbnQ7cm9sZT1hZG1pbg==

El mismo exploit funciona para cookies que contienen datos codificados de forma diferente. También debemos estar atentos a los datos en codificación hexadecimal o codificación URL. Por ejemplo, un token de sesión que contenga datos codificados en hexadecimal podría tener este aspecto:

1
2
3
$ echo -n 'user=htb-stdnt;role=admin' | xxd -p
757365723d6874622d7374646e743b726f6c653d61646d696e
Otra variante de los tokens de sesión contiene el resultado del cifrado de una secuencia de datos. Un algoritmo criptográfico débil podría dar lugar a una escalada de privilegios o a eludir la autenticación, al igual que la codificación simple. El manejo inadecuado de los algoritmos criptográficos o la inyección de datos proporcionados por el usuario en la entrada de una función de cifrado pueden dar lugar a vulnerabilidades en la generación de tokens de sesión. Sin embargo, a menudo resulta difícil atacar los tokens de sesión basados en el cifrado con un enfoque de caja negra sin tener acceso al código fuente responsable de generar el token de sesión.
Session fixation (Fijación de sesión)
La fijación de sesión es un ataque que permite al atacante obtener la sesión válida de la víctima. Una aplicación web vulnerable a la fijación de sesión no asigna un nuevo token de sesión tras una autenticación correcta. Si el atacante puede obligar a la víctima a utilizar un token de sesión elegido por él, la fijación de sesión le permite robar la sesión de la víctima y acceder a su cuenta.
Por ejemplo, supongamos que una aplicación web vulnerable a la fijación de sesión utiliza un token de sesión en la sesión de cookies HTTP. Además, la aplicación web establece la cookie de sesión del usuario en un valor proporcionado en el parámetro GET sid. En estas circunstancias, un ataque de fijación de sesión podría ser similar al siguiente:
Un atacante obtiene un token de sesión válido al autenticarse en la aplicación web. Por ejemplo, supongamos que el token de sesión es a1b2c3d4e5f6. A continuación, el atacante invalida su sesión cerrando la sesión.
El atacante engaña a la víctima para que utilice el token de sesión conocido enviándole el siguiente enlace: http://vulnerable.htb/?sid=a1b2c3d4e5f6. Cuando la víctima hace clic en este enlace, la aplicación web establece la cookie de sesión con el valor proporcionado, es decir, la respuesta es similar a esta:
1
2
3
4
HTTP/1.1 200 OK
[...]
Set-Cookie: session=a1b2c3d4e5f6
[...]
La víctima se autentica en la aplicación web vulnerable. El navegador de la víctima ya almacena la cookie de sesión proporcionada por el atacante, por lo que se envía junto con la solicitud de inicio de sesión. La víctima utiliza el token de sesión proporcionado por el atacante, ya que la aplicación web no asigna uno nuevo.
Dado que el atacante conoce el token de sesión de la víctima “a1b2c3d4e5f6”, puede secuestrar la sesión de la víctima.
Una aplicación web debe asignar un nuevo token de sesión generado aleatoriamente tras una autenticación satisfactoria para evitar ataques de fijación de sesión.
Tiempo de espera de sesión incorrecto
Por último, una aplicación web debe definir un tiempo de espera de sesión adecuado para un token de sesión. Una vez transcurrido el intervalo de tiempo definido en el tiempo de espera de la sesión, esta caducará y el token de sesión dejará de ser válido. Si una aplicación web no define un tiempo de espera de sesión, el token de sesión seguirá siendo válido indefinidamente, lo que permitirá a un atacante utilizar eficazmente una sesión secuestrada durante un periodo ilimitado.
Para la seguridad de una aplicación web, el tiempo de espera de la sesión debe configurarse adecuadamente. Dado que cada aplicación web tiene diferentes requisitos comerciales, no existe un valor universal para el tiempo de espera de la sesión.
Por ejemplo, una aplicación web que maneja datos confidenciales sobre la salud probablemente debería establecer un tiempo de espera de la sesión en el rango de minutos. Por el contrario, una aplicación web de redes sociales podría establecer un tiempo de espera de la sesión de varias horas.