Peticiones Web HTTP
Bases de las peticiones web HTTP.

HyperText Transfer protocol (HTTP)
La mayoría de las comunicaciones se realizan a mediante el navegador a través del protocolo HTTP. Este es un protocolo a nivel de aplicación (capa 7 en el modelo OSI) que se usa para acceder a recursos WWW.
El término “hypertext” viene dado por la posibilidad de contener enlaces a otros recursos y texto que es fácil de interpretar.
La comunicación HTTP consiste en un cliente y un servidor, donde el cliente solicita un recurso al servidor. El servidor procesa las solicitudes y devuelve el recurso solicitado. El puerto predeterminado para la comunicación HTTP es el puerto 80, aunque se puede cambiar a cualquier otro puerto, dependiendo de la configuración del servidor web.
Las mismas solicitudes se utilizan cuando utilizamos Internet para visitar diferentes sitios web. Introducimos un nombre de dominio completo (FQDN) como localizador uniforme de recursos (URL) para llegar al sitio web deseado.
URL
Se accede a los recursos a través de HTTP mediante una URL, que ofrece muchas más especificaciones que simplemente indicar el sitio web que queremos visitar.
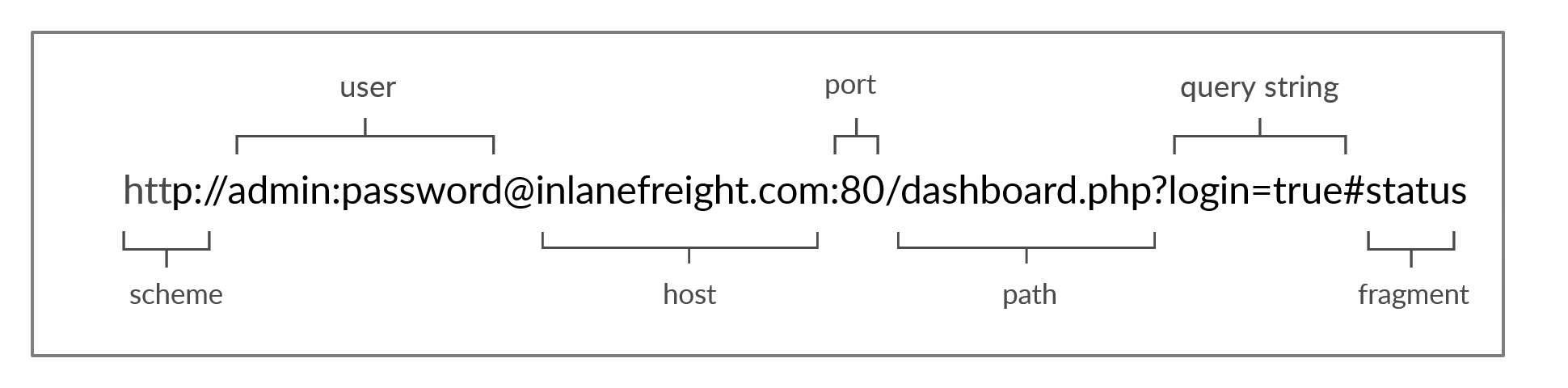
| Elemento | Ejemplo | Explicación |
|---|---|---|
| Esquema | http:// / https:// | Se utiliza para identificar el protocolo al que accede el cliente y termina con dos puntos y dos barras (://). |
| Info de usuario | admin:password@ | Este es un componente opcional que contiene las credenciales (separadas por dos puntos :) utilizadas para autenticarse en el host, y se separa del host con un signo de arroba (@). |
| Host | example.com | El host indica la ubicación del recurso. Puede ser un nombre de host o una dirección IP. |
| Puerto | :80 | El puerto se separa del host mediante dos puntos (:). Si no se especifica ningún puerto, los esquemas http utilizan por defecto el puerto 80 y los https el puerto 443. |
| Ruta | /login.php | Esto apunta al recurso al que se accede, que puede ser un archivo o una carpeta. Si no se especifica ninguna ruta, el servidor devuelve el índice predeterminado (por ejemplo, index.html). |
| Cadena de consulta | ?login=true | La cadena de consulta comienza con un signo de interrogación (?) y consta de un parámetro (por ejemplo, inicio de sesión) y un valor (por ejemplo, verdadero). Se pueden separar varios parámetros con un símbolo «&». |
| Fragmentos | #status | Los fragmentos son procesados por los navegadores en el lado del cliente para localizar secciones dentro del recurso principal (por ejemplo, un encabezado o una sección de la página). |
Los campos obligatorios principales son el esquema y el host, sin los cuales la solicitud no tendría ningún recurso que solicitar.
Flujo HTTP
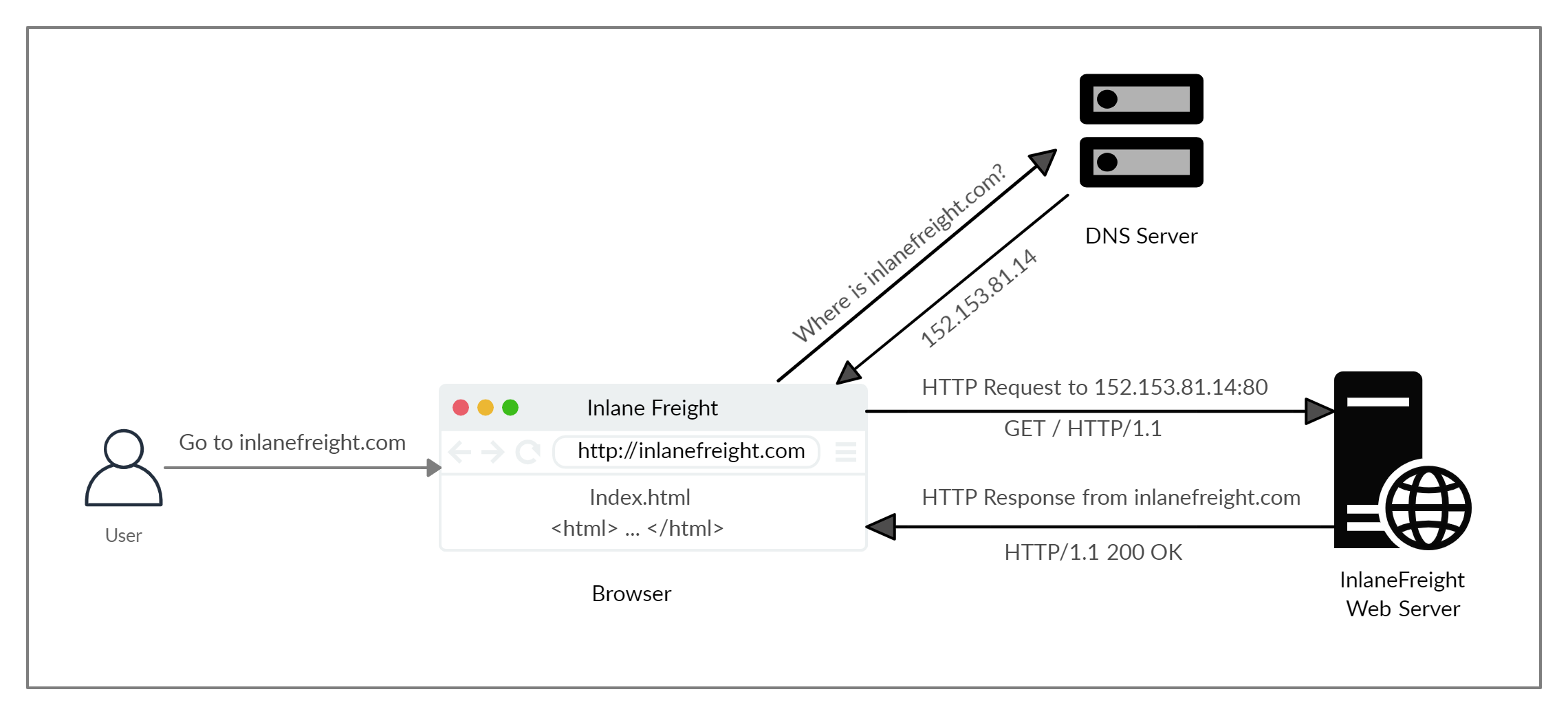
La primera vez que un usuario introduce la URL (inlanefreight.com) en el navegador, este envía una solicitud a un servidor DNS (Sistema de Nombres de Dominio) para resolver el dominio y obtener su IP. El servidor DNS busca la dirección IP de inlanefreight.com y la devuelve. Todos los nombres de dominio deben resolverse de esta manera, ya que un servidor no puede comunicarse sin una dirección IP.
[!NOTE] Nuestros navegadores suelen buscar primero los registros en el archivo local «/etc/hosts» y, si el dominio solicitado no existe en él, se ponen en contacto con otros servidores DNS. Podemos utilizar el archivo «/etc/hosts» para añadir manualmente registros para la resolución DNS, añadiendo la IP seguida del nombre de dominio.
Una vez que el navegador obtiene la dirección IP vinculada al dominio solicitado, envía una solicitud GET al puerto HTTP predeterminado (por ejemplo, el 80), solicitando la raíz / ruta. A continuación, el servidor web recibe la solicitud y la procesa. De forma predeterminada, los servidores están configurados para devolver un archivo de índice cuando se recibe una solicitud para /.
La respuesta también contiene el código de estado (por ejemplo, 200 OK), que indica que la solicitud se ha procesado correctamente.
cURL
cURL (URL del cliente) es una herramienta de línea de comandos y una biblioteca que admite principalmente HTTP junto con muchos otros protocolos. Esto lo convierte en un buen candidato para scripts y automatización, lo que lo hace esencial para enviar varios tipos de solicitudes web desde la línea de comandos, algo necesario para muchos tipos de pruebas de penetración web.
1
2
3
4
5
$ curl inlanefreight.com
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
...SNIP...
cURL no renderiza el código HTML/JavaScript/CSS, a diferencia de un navegador web, sino que lo imprime en su formato sin procesar, sin embargo, como probadores de penetración, nos interesa principalmente el contexto de solicitud y respuesta, que suele ser mucho más rápido y cómodo que un navegador web.
También podemos utilizar cURL para descargar una página o un archivo y guardar el contenido en un archivo utilizando el indicador -O. Si queremos especificar el nombre del archivo de salida, podemos utilizar el indicador -o y especificar el nombre. De lo contrario, podemos utilizar -O y cURL utilizará el nombre del archivo remoto.
1
2
3
$ curl -O example.com/index.html
$ ls
index.html
Hemos observado que cURL sigue mostrando algún estado mientras procesa la solicitud. Podemos silenciar el estado con el indicador -s.
1
$ curl -s -O inlanefreight.com/index.html
Hypertext Transfer Protocol Secure (HTTPS)
Una de las desventajas significativas del HTTP es que todos los datos se transfieren en texto sin cifrar. Esto significa que cualquier persona entre el origen y el destino puede realizar un ataque de tipo «man-in-the-middle» (MiTM) para ver los datos transferidos.
Por este motivo, HTTPS se ha convertido en el protocolo estándar para los sitios web en Internet, y HTTP está siendo gradualmente sustituido.
Descripción general de HTTPS
Podemos ver el efecto de no aplicar comunicaciones seguras entre un navegador web y una aplicación web. Por ejemplo, el siguiente es el contenido de una solicitud de inicio de sesión HTTP.
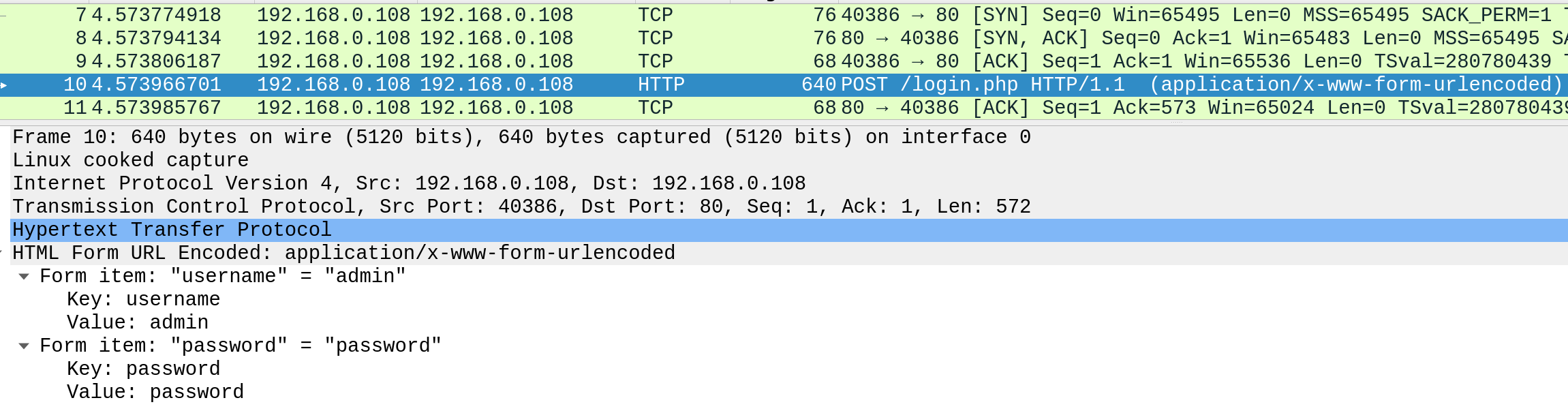
Esto facilitaría que alguien en la misma red (como una red inalámbrica pública) capturara la solicitud y reutilizara las credenciales.
Cuando alguien intercepta y analiza el tráfico de una solicitud HTTPS, vería algo como:
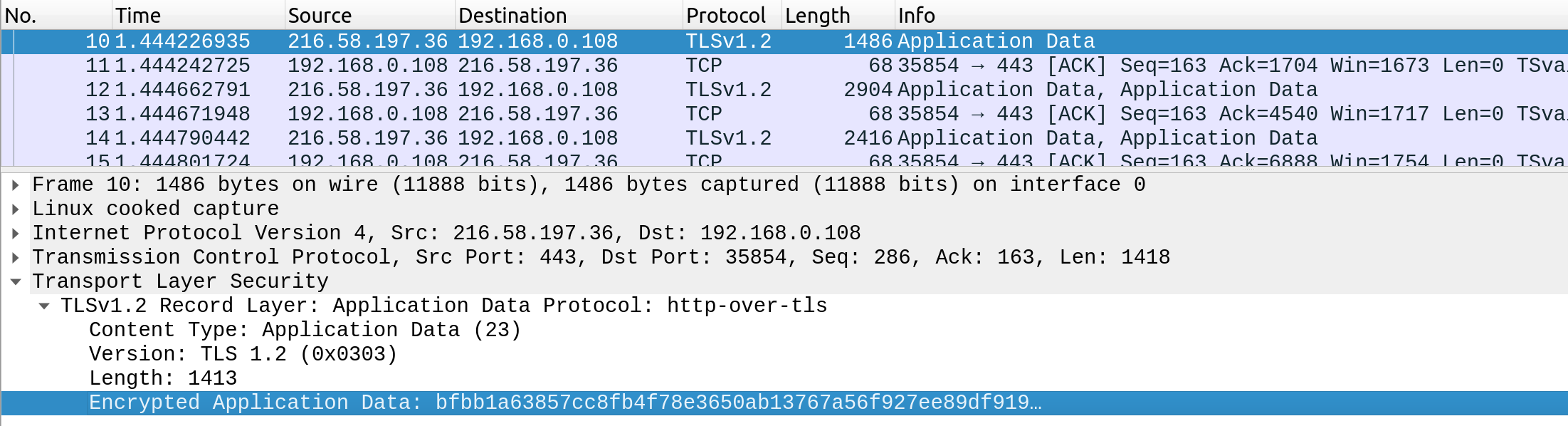
Los datos se transfieren como un único flujo cifrado, lo que dificulta enormemente que alguien pueda capturar la información.
Los sitios web que utilizan HTTPS pueden identificarse por la presencia de «https://» en su URL.
[!NOTE] Aunque los datos transferidos a través del protocolo HTTPS pueden estar cifrados, la solicitud puede revelar la URL visitada si se ha conectado a un servidor DNS de texto sin cifrar. Por este motivo, se recomienda utilizar servidores DNS cifrados (por ejemplo, 8.8.8.8 o 1.1.1.1) o un servicio VPN para garantizar que todo el tráfico esté correctamente cifrado
Flujo HTTPS
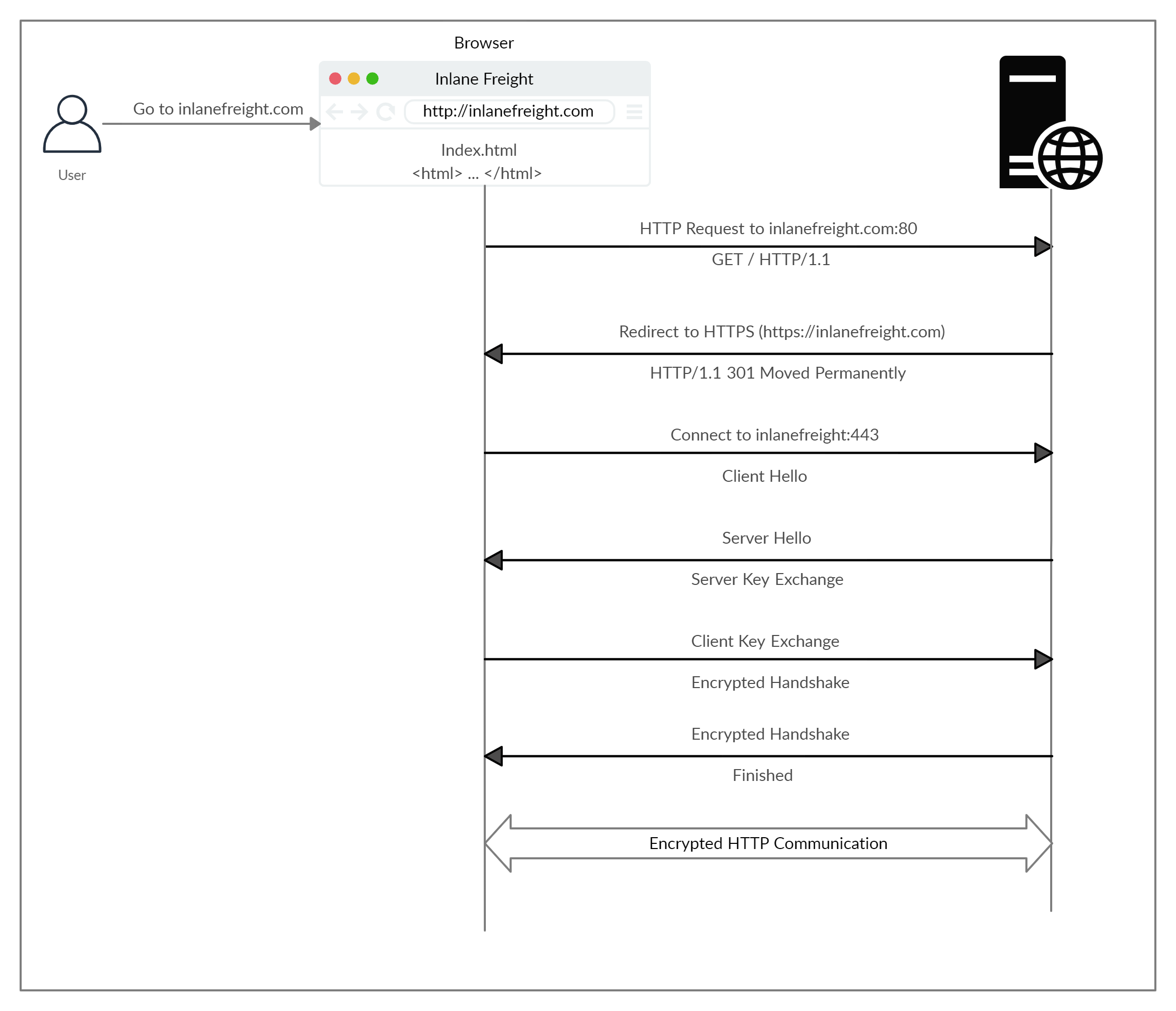 Si escribimos http:// en lugar de https:// para visitar un sitio web que utiliza HTTPS, el navegador intenta resolver el dominio y redirige al usuario al servidor web que aloja el sitio web de destino. Primero se envía una solicitud al puerto 80, que es el protocolo HTTP sin cifrar. El servidor detecta esto y redirige al cliente al puerto HTTPS seguro 443. Esto se hace mediante el código de respuesta 301 Moved Permanently, que discutiremos en una sección posterior.
Si escribimos http:// en lugar de https:// para visitar un sitio web que utiliza HTTPS, el navegador intenta resolver el dominio y redirige al usuario al servidor web que aloja el sitio web de destino. Primero se envía una solicitud al puerto 80, que es el protocolo HTTP sin cifrar. El servidor detecta esto y redirige al cliente al puerto HTTPS seguro 443. Esto se hace mediante el código de respuesta 301 Moved Permanently, que discutiremos en una sección posterior.
El cliente (navegador web) envía un paquete «client hello» con información sobre sí mismo. A continuación, el servidor responde con un «server hello», seguido de un intercambio de claves para intercambiar certificados SSL. El cliente verifica la clave/certificado y envía uno propio. Después, se inicia un protocolo de enlace cifrado para confirmar que el cifrado y la transferencia funcionan correctamente.
Una vez que el protocolo de enlace se completa con éxito, se continúa con la comunicación HTTP normal, que se cifra a partir de ese momento.
[!NOTE] Dependiendo de las circunstancias, un atacante puede realizar un ataque de degradación HTTP, que degrada la comunicación HTTPS a HTTP, haciendo que los datos se transfieran en texto claro. Esto se hace configurando un proxy Man-In-The-Middle (MITM) para transferir todo el tráfico a través del host del atacante sin el conocimiento del usuario. Sin embargo, la mayoría de los navegadores, servidores y aplicaciones web modernos protegen contra este ataque.
cURL for HTTPS
cURL debería gestionar automáticamente todos los estándares de comunicación HTTPS y realizar un protocolo de enlace seguro, para luego cifrar y descifrar los datos automáticamente. Sin embargo, si alguna vez nos conectamos a un sitio web con un certificado SSL no válido u obsoleto, cURL, por defecto, no continuaría con la comunicación para protegernos contra los ataques MITM mencionados anteriormente.
1
2
3
4
5
$ curl https://example.com
curl: (60) SSL certificate problem: Invalid certificate chain
More details here: https://curl.haxx.se/docs/sslcerts.html
...SNIP...
Los navegadores harían lo mismo, advirtiendo al usuario que no visite un sitio web con un certificado SSL no válido.
Para omitir la comprobación del certificado con cURL, podemos utilizar el indicador -k.
1
2
3
4
5
$ curl -k https://inlanefreight.com
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
...SNIP...
Peticiones y respuestas HTTP
El cliente (por ejemplo, cURL/navegador) realiza una solicitud HTTP, que es procesada por el servidor (por ejemplo, servidor web). Las solicitudes contienen todos los detalles que requerimos del servidor, incluyendo el recurso (por ejemplo, URL, ruta, parámetros), cualquier dato de solicitud, encabezados u opciones que especifiquemos.
Peticiones HTTP
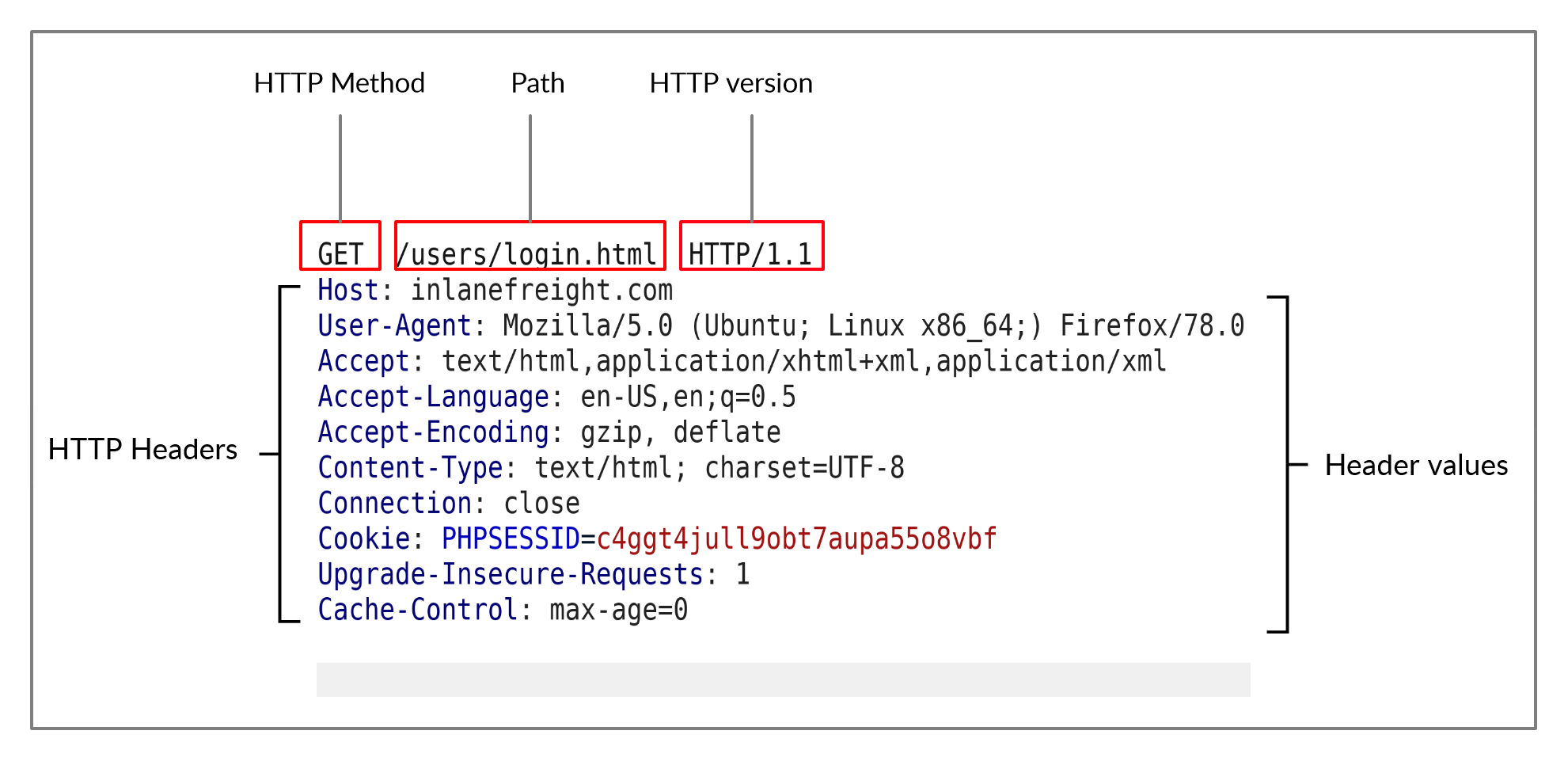 La primera línea de cualquier solicitud HTTP contiene tres campos principales separados por espacios.
La primera línea de cualquier solicitud HTTP contiene tres campos principales separados por espacios.
| Campo | Ejemplo | Descripción | | ——- | —————– | ——————————————————————————————————————————— | | Método | GET | El método o verbo HTTP, que especifica el tipo de acción que se va a realizar. | | Ruta | /users/login.html | La ruta al recurso al que se accede. Este campo también puede ir seguido de una cadena de consulta (por ejemplo, ?username=user). | | Versión | HTTP/1.1 | El tercer y último campo se utiliza para indicar la versión HTTP. | El siguiente conjunto de líneas contiene pares de valores de encabezados HTTP, como Host, User-Agent, Cookie y muchos otros encabezados posibles. Estos encabezados se utilizan para especificar diversos atributos de una solicitud. Los encabezados terminan con una nueva línea, lo cual es necesario para que el servidor valide la solicitud.
Por último, una solicitud puede terminar con el cuerpo y los datos de la solicitud.
[!NOTE] La versión 1.X de HTTP envía las solicitudes como texto sin cifrar y utiliza un carácter de nueva línea para separar los diferentes campos y solicitudes. Por otro lado, la versión 2.X de HTTP envía las solicitudes como datos binarios en forma de diccionario.
Respuesta HTTP
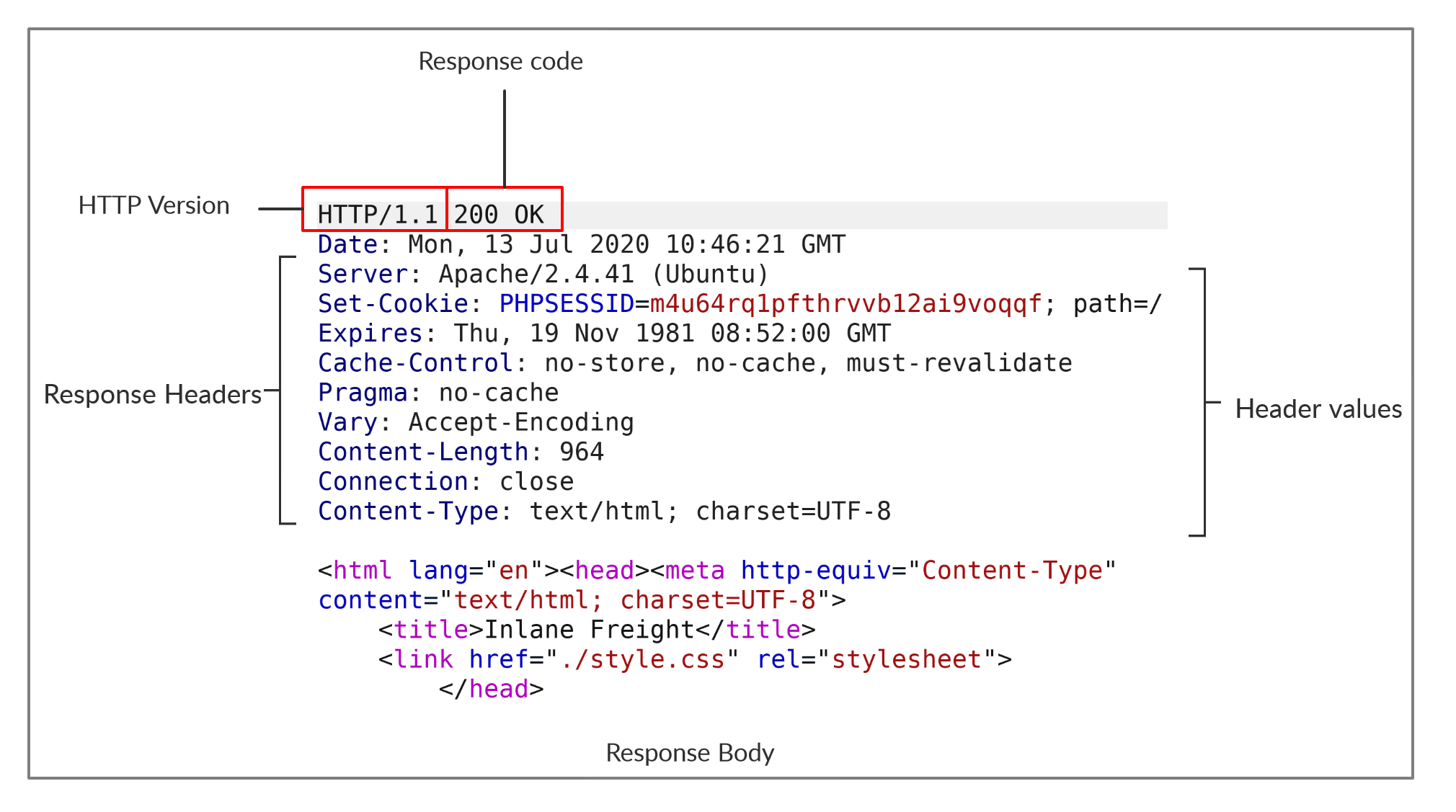 La primera línea de una respuesta HTTP contiene dos campos separados por espacios. El primero es la versión HTTP (por ejemplo, HTTP/1.1) y el segundo indica el código de respuesta HTTP (por ejemplo, 200 OK). Después de la primera línea, la respuesta enumera sus encabezados, de forma similar a una solicitud HTTP.
La primera línea de una respuesta HTTP contiene dos campos separados por espacios. El primero es la versión HTTP (por ejemplo, HTTP/1.1) y el segundo indica el código de respuesta HTTP (por ejemplo, 200 OK). Después de la primera línea, la respuesta enumera sus encabezados, de forma similar a una solicitud HTTP.
El cuerpo de la respuesta suele definirse como código HTML. Sin embargo, también puede responder con otros tipos de código, como JSON, recursos de sitios web, como imágenes, hojas de estilo o scripts, o incluso un documento, como un documento PDF alojado en el servidor web.
cURL
cURL también nos permite previsualizar la solicitud HTTP completa y la respuesta HTTP completa, lo que puede resultar muy útil al realizar pruebas de penetración web o escribir exploits. Para ver la solicitud y la respuesta HTTP completas, solo tenemos que añadir el indicador -v verbose.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
$ curl inlanefreight.com -v
* Trying SERVER_IP:80...
* TCP_NODELAY set
* Connected to example.com (SERVER_IP) port 80 (#0)
> GET / HTTP/1.1
> Host: example.com
> User-Agent: curl/7.65.3
> Accept: */*
> Connection: close
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 401 Unauthorized
< Date: Tue, 21 Jul 2020 05:20:15 GMT
< Server: Apache/X.Y.ZZ (Ubuntu)
< WWW-Authenticate: Basic realm="Restricted Content"
< Content-Length: 464
< Content-Type: text/html; charset=iso-8859-1
<
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
...SNIP...
[!NOTE] El parámetro -vvv muestra una salida aún más detallada.
Browser DevTools
Estas herramientas pueden ser un recurso fundamental en cualquier evaluación web que realicemos, ya que el navegador (y sus DevTools) se encuentran entre los recursos que más probablemente tendremos a nuestra disposición en cada ejercicio de evaluación web.
Para abrir las herramientas de desarrollo del navegador en Chrome o Firefox, podemos pulsar [CTRL+MAYÚS+I] o simplemente pulsar [F12].
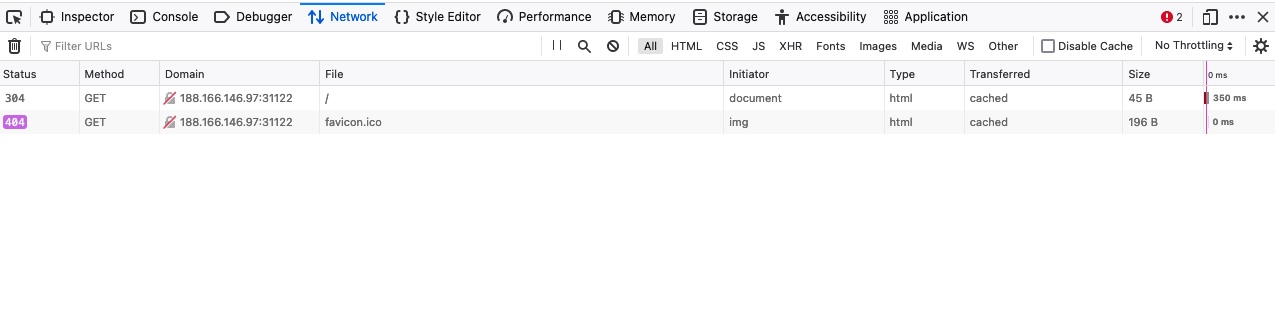
Las herramientas de desarrollo nos muestran de un vistazo el estado de la respuesta (es decir, el código de respuesta), el método de solicitud utilizado (GET), el recurso solicitado (es decir, la URL/dominio), junto con la ruta solicitada.
Cabeceras HTTP
Los encabezados HTTP transmiten información entre el cliente y el servidor. Algunos encabezados solo se utilizan con solicitudes o respuestas, mientras que otros encabezados generales son comunes a ambos.
Los encabezados pueden tener uno o varios valores, añadidos después del nombre del encabezado y separados por dos puntos. Podemos dividir los encabezados en las siguientes categorías:
Encabezados generales
Se utilizan tanto en las solicitudes HTTP como en las respuestas. Son contextuales y se utilizan para describir el mensaje, más que su contenido.
| Header | Ejemplo | Explicación |
|---|---|---|
| Date | Date: Wed, 16 Feb 2022 10:38:44 GMT | Contiene la fecha y la hora en que se originó el mensaje. Es preferible convertir la hora a la zona horaria UTC estándar. |
| Connection | Connection: close | Determina si la conexión de red actual debe permanecer activa una vez finalizada la solicitud. Dos valores que se utilizan habitualmente para este encabezado son «close» y «keep-alive». El valor «close», tanto del cliente como del servidor, significa que desean terminar la conexión, mientras que el encabezado «keep-alive» indica que la conexión debe permanecer abierta para recibir más datos y entradas. |
Encabezados de entidad
| Header | Ejemplo | Explicación |
|---|---|---|
| Content-Type | Content-Type: text/html | Se utiliza para describir el tipo de recurso que se transfiere. El valor lo añaden automáticamente los navegadores en el lado del cliente y se devuelve en la respuesta del servidor. El campo charset indica el estándar de codificación, como UTF-8. |
| Media-Type | Media-Type: application/pdf | Es similar al tipo de contenido y describe los datos que se transfieren. Este encabezado puede desempeñar un papel crucial a la hora de hacer que el servidor interprete nuestra entrada. El campo charset también se puede utilizar con este encabezado. |
| Boundary | boundary=”b4e4fbd93540” | Actúa como marcador para separar contenidos cuando hay más de uno en el mismo mensaje. Por ejemplo, dentro de los datos de un formulario, este límite se utiliza como –b4e4fbd93540 para separar las diferentes partes del formulario. |
| Content-Length | Content-Length: 385 | Contiene el tamaño de la entidad que se está transmitiendo. Este encabezado es necesario, ya que el servidor lo utiliza para leer los datos del cuerpo del mensaje, y es generado automáticamente por el navegador y herramientas como cURL. |
| Content-Encoding | Content-Encoding: gzip | Los datos pueden sufrir múltiples transformaciones antes de ser transmitidos. Por ejemplo, se pueden comprimir grandes cantidades de datos para reducir el tamaño del mensaje. El tipo de codificación utilizado debe especificarse mediante el encabezado Content-Encoding. |
Pueden ser comunes tanto para la solicitud como para la respuesta. Estos encabezados se utilizan para describir el contenido (entidad) transferido por un mensaje. Suelen encontrarse en las respuestas y en las solicitudes POST o PUT.
Encabezados de solicitud
Estos encabezados se utilizan en una solicitud HTTP y no están relacionados con el contenido del mensaje.
| Header | Ejemplo | Explicación |
|---|---|---|
| Host | Host: www.example.com | Se utiliza para especificar el host al que se solicita el recurso. Puede ser un nombre de dominio o una dirección IP. Los servidores HTTP pueden configurarse para alojar diferentes sitios web, que se revelan en función del nombre de host. Esto convierte al encabezado del host en un objetivo de enumeración importante, ya que puede indicar la existencia de otros hosts en el servidor de destino. |
| User-Agent | User-Agent: curl/7.77.0 | El encabezado User-Agent se utiliza para describir el cliente que solicita recursos. Este encabezado puede revelar mucha información sobre el cliente, como el navegador, su versión y el sistema operativo. |
| Referer | Referer: http://www.example.com/ | Indica de dónde proviene la solicitud actual. Por ejemplo, al hacer clic en un enlace de los resultados de búsqueda de Google, https://google.com sería el referente. Confiar en este encabezado puede ser peligroso, ya que se puede manipular fácilmente, lo que puede tener consecuencias no deseadas. |
| Accept | Accept: / | El encabezado Accept describe los tipos de medios que el cliente puede comprender. Puede contener varios tipos de medios separados por comas. El valor / significa que se aceptan todos los tipos de medios. |
| Cookie | Cookie: PHPSESSID=b4e4fbd93540 | Contiene pares de valores de cookies en el formato nombre=valor. Una cookie es un fragmento de datos almacenado en el lado del cliente y en el servidor, que actúa como identificador. Estos se envían al servidor por solicitud, manteniendo así el acceso del cliente. Las cookies también pueden tener otros fines, como guardar las preferencias del usuario o realizar un seguimiento de la sesión. Puede haber varias cookies en un solo encabezado separadas por un punto y coma. |
| Authorization | Authorization: BASIC cGFzc3dvcmQK | Otro método para que el servidor identifique a los clientes. Tras una autenticación satisfactoria, el servidor devuelve un token único para el cliente. A diferencia de las cookies, los tokens solo se almacenan en el lado del cliente y el servidor los recupera por solicitud. Existen varios tipos de autenticación en función del servidor web y el tipo de aplicación utilizados. |
Encabezados de respuesta
Se pueden utilizar en una respuesta HTTP y no están relacionados con el contenido. Ciertos encabezados de respuesta, como Age, Location y Server, se utilizan para proporcionar más contexto sobre la respuesta.
| Header | Ejemplo | Explicación |
|---|---|---|
| Server | Server: Apache/2.2.14 (Win32) | Contiene información sobre el servidor HTTP que procesó la solicitud. Se puede utilizar para obtener información sobre el servidor, como su versión, y enumerarla con más detalle. |
| Set-Cookie | Set-Cookie: PHPSESSID=b4e4fbd93540 | Contiene las cookies necesarias para la identificación del cliente. Los navegadores analizan las cookies y las almacenan para futuras solicitudes. Este encabezado sigue el mismo formato que el encabezado de solicitud de cookies. |
| WWW-Authenticate | WWW-Authenticate: BASIC realm=”localhost” | Notifica al cliente el tipo de autenticación requerido para acceder al recurso solicitado. |
Encabezados de seguridad
Los encabezados de seguridad HTTP son una clase de encabezados de respuesta que se utilizan para especificar ciertas reglas y políticas que debe seguir el navegador al acceder al sitio web.
| Header | Ejemplo | Explicación |
|---|---|---|
| Content-Security-Policy | Content-Security-Policy: script-src ‘self’ | Dicta la política del sitio web con respecto a los recursos inyectados externamente. Estos pueden ser código JavaScript o recursos de script. Este encabezado indica al navegador que solo acepte recursos de determinados dominios de confianza, lo que evita ataques como el Cross-site scripting (XSS). |
| Strict-Transport-Security | Strict-Transport-Security: max-age=31536000 | Impide que el navegador acceda al sitio web a través del protocolo HTTP de texto sin cifrar y obliga a que todas las comunicaciones se realicen a través del protocolo seguro HTTPS. |
| Referrer-Policy | Referrer-Policy: origin | Determina si el navegador debe incluir el valor especificado a través del encabezado Referer o no. Puede ayudar a evitar la divulgación de URL e información confidenciales mientras se navega por el sitio web. |
cURL
Si solo nos interesara ver los encabezados de respuesta, podríamos utilizar el indicador -I para enviar una solicitud HEAD y mostrar únicamente los encabezados de respuesta.
Podemos utilizar el indicador -i para mostrar tanto los encabezados como el cuerpo de la respuesta (por ejemplo, el código HTML). La diferencia entre ambos es que -I envía una solicitud HEAD mientras que -i envía cualquier solicitud que especifiquemos y también imprime los encabezados.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
$ curl -I https://www.example.com
Host: www.example.com
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/605.1.15 (KHTML, like Gecko)
Cookie: cookie1=298zf09hf012fh2; cookie2=u32t4o3tb3gg4
Accept: text/plain
Referer: https://www.example.com/
Authorization: BASIC cGFzc3dvcmQK
Date: Sun, 06 Aug 2020 08:49:37 GMT
Connection: keep-alive
Content-Length: 26012
Content-Type: text/html; charset=ISO-8859-4
Content-Encoding: gzip
Server: Apache/2.2.14 (Win32)
Set-Cookie: name1=value1,name2=value2; Expires=Wed, 09 Jun 2021 10:18:14 GMT
WWW-Authenticate: BASIC realm="localhost"
Content-Security-Policy: script-src 'self'
Strict-Transport-Security: max-age=31536000
Referrer-Policy: origin
cURL también nos permite establecer encabezados de solicitud con el indicador -H, como veremos en una sección posterior. Algunos encabezados, como los encabezados User-Agent o Cookie, tienen sus propios indicadores. Por ejemplo, podemos usar -A para establecer nuestro User-Agent.
1
2
3
4
5
$ curl https://www.example.com -A 'Mozilla/5.0'
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
...SNIP...
Métodos y codigos HTTP
En el protocolo HTTP, varios métodos de solicitud permiten al navegador enviar información, formularios o archivos al servidor. Estos métodos se utilizan, entre otras cosas, para indicar al servidor cómo procesar la solicitud que enviamos y cómo responder.
Métodos de petición
| Método | Descripción | | ——- | —————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————- | | GET | Solicita un recurso específico. Se pueden enviar datos adicionales al servidor mediante cadenas de consulta en la URL (por ejemplo, ?param=value). | | POST | Envía datos al servidor. Puede manejar múltiples tipos de entrada, como texto, PDF y otras formas de datos binarios. Estos datos se añaden al cuerpo de la solicitud que se encuentra después de los encabezados. El método POST se utiliza comúnmente al enviar información (por ejemplo, formularios/inicios de sesión) o al cargar datos en un sitio web, como imágenes o documentos. | | HEAD | Solicita los encabezados que se devolverían si se realizara una solicitud GET al servidor. No devuelve el cuerpo de la solicitud y normalmente se realiza para comprobar la longitud de la respuesta antes de descargar recursos. | | PUT | Crea nuevos recursos en el servidor. Permitir este método sin los controles adecuados puede dar lugar a la carga de recursos maliciosos. | | DELETE | Elimina un recurso existente en el servidor web. Si no se protege adecuadamente, puede provocar una denegación de servicio (DoS) al eliminar archivos críticos del servidor web. | | OPTIONS | Devuelve información sobre el servidor, como los métodos que acepta. | | PATCH | Aplica modificaciones parciales al recurso en la ubicación especificada. | La disponibilidad de un método concreto depende del servidor y de la configuración de la aplicación.
[!NOTE] Las aplicaciones web modernas se basan principalmente en los métodos GET y POST. Sin embargo, cualquier aplicación web que utilice API REST también se basa en PUT y DELETE, que se utilizan para actualizar y eliminar datos en el punto final de la API, respectivamente.
Códigos de estado
Los códigos de estado se utilizan para informar al cliente del estado de su solicitud. Un servidor HTTP puede devolver cinco clases de códigos de estado.
| Clase | Descripción |
|---|---|
| 1xx | Proporciona información y no afecta al procesamiento de la solicitud. |
| 2xx | Se devuelve cuando una solicitud tiene éxito. |
| 3xx | Devuelto cuando el servidor redirige al cliente. |
| 4xx | Indica solicitudes incorrectas del cliente. Por ejemplo, solicitar un recurso que no existe o solicitar un formato incorrecto. |
| 5xx | Se devuelve cuando hay algún problema con el propio servidor HTTP. |
Algunas de las más comunes son:
| Código | Descripción |
|---|---|
| 200 OK | Se devuelve tras una solicitud satisfactoria, y el cuerpo de la respuesta suele contener el recurso solicitado. |
| 302 Found | Redirige al cliente a otra URL. Por ejemplo, redirigir al usuario a su panel de control después de iniciar sesión correctamente. |
| 301 Moved Permanently | La URL del recurso solicitado ha cambiado de forma permanente. La nueva URL se indica en la respuesta. |
| 400 Bad Request | Devuelto al encontrar solicitudes malformadas, como solicitudes con terminadores de línea faltantes. |
| 403 Forbidden | Significa que el cliente no tiene acceso adecuado al recurso. También puede devolverse cuando el servidor detecta una entrada maliciosa del usuario. |
| 404 Not Found | Se devuelve cuando el cliente solicita un recurso que no existe en el servidor. |
| 500 Internal Server Error | Se devuelve cuando el servidor no puede procesar la solicitud. |
Para obtener una lista completa de los códigos de estado HTTP estándar, puede visitar este enlace.
GET
Cada vez que visitamos una URL, nuestros navegadores envían por defecto una solicitud GET para obtener los recursos remotos alojados en esa URL. Una vez que el navegador recibe la página inicial que solicita, puede enviar otras solicitudes utilizando diversos métodos HTTP.
Autenticación básica HTTP
A diferencia de los formularios de inicio de sesión habituales, que utilizan parámetros HTTP para validar las credenciales del usuario (por ejemplo, solicitud POST), este tipo de autenticación utiliza una autenticación HTTP básica, que es gestionada directamente por el servidor web para proteger una página o directorio específico, sin interactuar directamente con la aplicación web.
Intentemos acceder a la página con cURL y añadiremos -i para ver los encabezados de respuesta.
1
2
3
4
5
6
7
8
9
10
$ curl -i http://<SERVER_IP>:<PORT>/
HTTP/1.1 401 Authorization Required
Date: Mon, 21 Feb 2022 13:11:46 GMT
Server: Apache/2.4.41 (Ubuntu)
Cache-Control: no-cache, must-revalidate, max-age=0
WWW-Authenticate: Basic realm="Access denied"
Content-Length: 13
Content-Type: text/html; charset=UTF-8
Access denied
Como podemos ver, obtenemos «Acceso denegado» en el cuerpo de la respuesta, y también obtenemos «Basic realm=”Acceso denegado”» en el encabezado WWW-Authenticate, lo que confirma que esta página utiliza efectivamente la autenticación HTTP básica.
Para proporcionar las credenciales a través de cURL, podemos utilizar el indicador -u.
1
2
3
4
5
6
7
$ curl -u admin:admin http://<SERVER_IP>:<PORT>/
<!DOCTYPE html>
<html lang="en">
<head>
...SNIP...
Existe otro método para proporcionar las credenciales básicas de autenticación HTTP, que es directamente a través de la URL como (nombre de usuario:contraseña@URL).
1
2
3
4
5
6
7
$ curl http://admin:admin@<SERVER_IP>:<PORT>/
<!DOCTYPE html>
<html lang="en">
<head>
...SNIP...
Cabecera de autenticación HTTP
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
$ curl -v http://admin:admin@<SERVER_IP>:<PORT>/
* Trying <SERVER_IP>:<PORT>...
* Connected to <SERVER_IP> (<SERVER_IP>) port PORT (#0)
* Server auth using Basic with user 'admin'
> GET / HTTP/1.1
> Host: <SERVER_IP>
> Authorization: Basic YWRtaW46YWRtaW4=
> User-Agent: curl/7.77.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Date: Mon, 21 Feb 2022 13:19:57 GMT
< Server: Apache/2.4.41 (Ubuntu)
< Cache-Control: no-store, no-cache, must-revalidate
< Expires: Thu, 19 Nov 1981 08:52:00 GMT
< Pragma: no-cache
< Vary: Accept-Encoding
< Content-Length: 1453
< Content-Type: text/html; charset=UTF-8
<
<!DOCTYPE html>
<html lang="en">
<head>
...SNIP...
Como estamos utilizando la autenticación HTTP básica, vemos que nuestra solicitud HTTP establece el encabezado de autorización en Basic YWRtaW46YWRtaW4=, que es el valor codificado en base64 de admin:admin. Si estuviéramos utilizando un método de autenticación moderno (por ejemplo, JWT), la autorización sería de tipo Bearer y contendría un token cifrado más largo.
Intentemos configurar manualmente la autorización, sin proporcionar las credenciales.
Podemos configurar el encabezado con el indicador -H y utilizaremos el mismo valor de la solicitud HTTP anterior. Podemos añadir el indicador -H varias veces para especificar varios encabezados.
1
2
3
4
5
6
7
$ curl -H 'Authorization: Basic YWRtaW46YWRtaW4=' http://<SERVER_IP>:<PORT>/
<!DOCTYPE html
<html lang="en">
<head>
...SNIP...
La mayoría de las aplicaciones web modernas utilizan formularios de inicio de sesión creados con el lenguaje de programación back-end (por ejemplo, PHP), que utilizan solicitudes HTTP POST para autenticar a los usuarios y, a continuación, devuelven una cookie para mantener su autenticación.
Parámetros GET
Tenemos acceso a una función de búsqueda de ciudades, en la que podemos introducir un término de búsqueda y obtener una lista de ciudades coincidentes.

Cuando la página muestra nuestros resultados, es posible que se ponga en contacto con un recurso remoto para obtener la información y, a continuación, la muestre en la página. Para verificarlo, podemos abrir las herramientas de desarrollo del navegador y dirigirnos a la pestaña Red, o utilizar el atajo [CTRL+MAYÚS+E] para acceder a la misma pestaña.
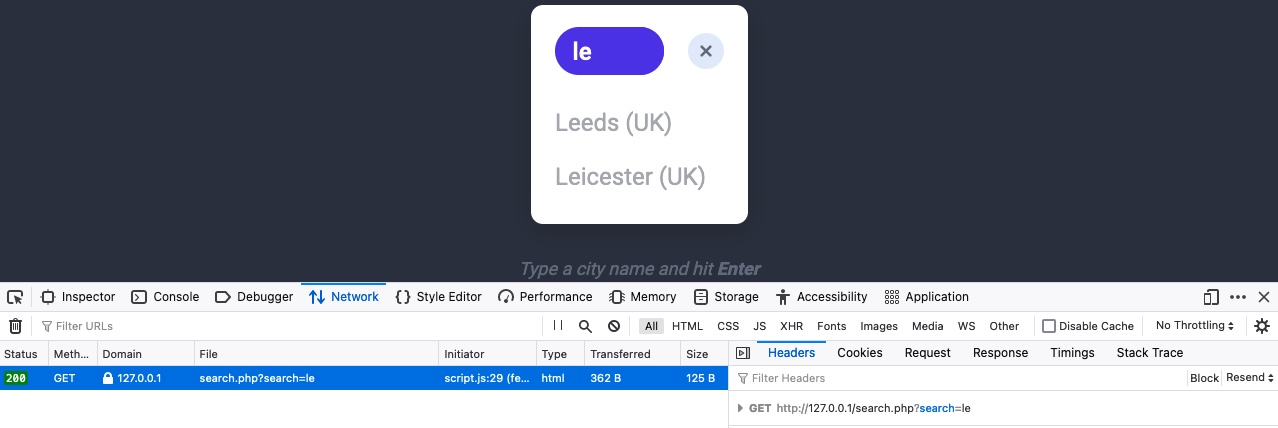
Cuando hacemos clic en la solicitud, esta se envía a search.php con el parámetro GET search=le utilizado en la URL.
Ahora, podemos enviar la misma solicitud directamente a search.php para obtener los resultados completos de la búsqueda. Las herramientas de desarrollo del navegador proporcionan un método más cómodo para obtener el comando cURL. Podemos hacer clic con el botón derecho del ratón en la solicitud y seleccionar Copiar > Copiar como cURL. A continuación, podemos pegar el comando copiado en nuestro terminal y ejecutarlo.
1
2
3
4
$ curl 'http://<SERVER_IP>:<PORT>/search.php?search=le' -H 'Authorization: Basic YWRtaW46YWRtaW4='
Leeds (UK)
Leicester (UK)
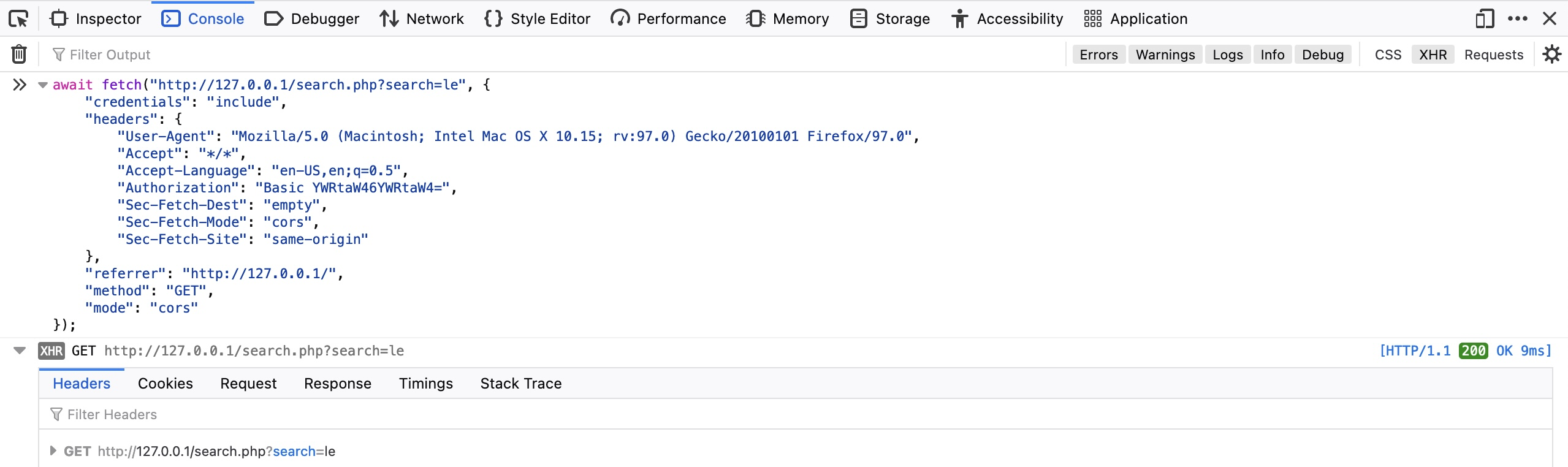
También podemos repetir la solicitud exacta directamente en las herramientas de desarrollo del navegador, seleccionando Copiar > Copiar como Fetch. Esto copiará la misma solicitud HTTP utilizando la biblioteca JavaScript Fetch. A continuación, podemos ir a la pestaña de la consola JavaScript pulsando [CTRL+MAYÚS+K], pegar nuestro comando Fetch y pulsar Intro para enviar la solicitud.
POST
Siempre que las aplicaciones web necesitan transferir archivos o mover los parámetros del usuario desde la URL, utilizan solicitudes POST.
HTTP POST coloca los parámetros del usuario dentro del cuerpo de la solicitud HTTP. Esto tiene tres ventajas principales.
Falta de registro: dado que las solicitudes POST pueden transferir archivos de gran tamaño (por ejemplo, carga de archivos), no sería eficiente que el servidor registrara todos los archivos cargados como parte de la URL solicitada, como sería el caso de un archivo cargado a través de una solicitud GET.
Menos requisitos de codificación: las URL están diseñadas para ser compartidas, lo que significa que deben ajustarse a caracteres que puedan convertirse en letras. La solicitud POST coloca los datos en el cuerpo, que puede aceptar datos binarios. Los únicos caracteres que deben codificarse son los que se utilizan para separar los parámetros.
Se pueden enviar más datos: la longitud máxima de las URL varía entre navegadores (Chrome/Firefox/IE), servidores web (IIS, Apache, nginx), redes de distribución de contenidos (Fastly, Cloudfront, Cloudflare) e incluso acortadores de URL (bit.ly, amzn.to). En términos generales, la longitud de una URL debe ser inferior a 2000 caracteres, por lo que no pueden manejar una gran cantidad de datos.
Formularios de login
Una vez que visitamos la aplicación web, vemos que utiliza un formulario de inicio de sesión PHP en lugar de la autenticación básica HTTP.
Si intentamos iniciar sesión con admin:admin, entramos y vemos una función de búsqueda similar a la que vimos anteriormente en la sección GET.
En las herramientas de desarrollo de nuestro navegador, intentemos iniciar sesión de nuevo y veremos que se envían muchas solicitudes. Podemos filtrar las solicitudes por la IP de nuestro servidor, de modo que solo se muestren las solicitudes que van al servidor web de la aplicación web (es decir, se filtran las solicitudes externas), y observaremos que se envía la siguiente solicitud POST.
Podemos hacer clic en la solicitud, hacer clic en la pestaña Solicitud y, a continuación, hacer clic en el botón Sin procesar para mostrar los datos sin procesar de la solicitud.
Con los datos de la solicitud a mano, podemos intentar enviar una solicitud similar con cURL, para ver si esto nos permitiría iniciar sesión también.
Usaremos el indicador -X POST para enviar una solicitud POST. A continuación, para añadir nuestros datos POST, podemos usar el indicador -d y añadir los datos anteriores después de él.
1
2
3
4
5
$ curl -X POST -d 'username=admin&password=admin' http://<SERVER_IP>:<PORT>/
...SNIP...
<em>Type a city name and hit <strong>Enter</strong></em>
...SNIP...
[!NOTE] Muchos formularios de inicio de sesión nos redirigen a una página diferente una vez autenticados (por ejemplo, /dashboard.php). Si queremos seguir la redirección con cURL, podemos utilizar el indicador -L.
Cookies de autenticación
Si la autenticación se ha realizado correctamente, deberíamos haber recibido una cookie para que nuestros navegadores puedan mantener nuestra autenticación.
1
2
3
4
5
6
7
8
9
10
$ curl -X POST -d 'username=admin&password=admin' http://<SERVER_IP>:<PORT>/ -i
HTTP/1.1 200 OK
Date:
Server: Apache/2.4.41 (Ubuntu)
Set-Cookie: PHPSESSID=c1nsa6op7vtk7kdis7bcnbadf1; path=/
...SNIP...
<em>Type a city name and hit <strong>Enter</strong></em>
...SNIP...
Ahora deberíamos poder interactuar con la aplicación web sin necesidad de proporcionar nuestras credenciales cada vez. Para probarlo, podemos establecer la cookie anterior con el indicador -b en cURL.
1
2
3
4
5
$ curl -b 'PHPSESSID=c1nsa6op7vtk7kdis7bcnbadf1' http://<SERVER_IP>:<PORT>/
...SNIP...
<em>Type a city name and hit <strong>Enter</strong></em>
...SNIP...
JSON
Podemos realizar cualquier consulta de búsqueda para ver qué solicitudes se envían.
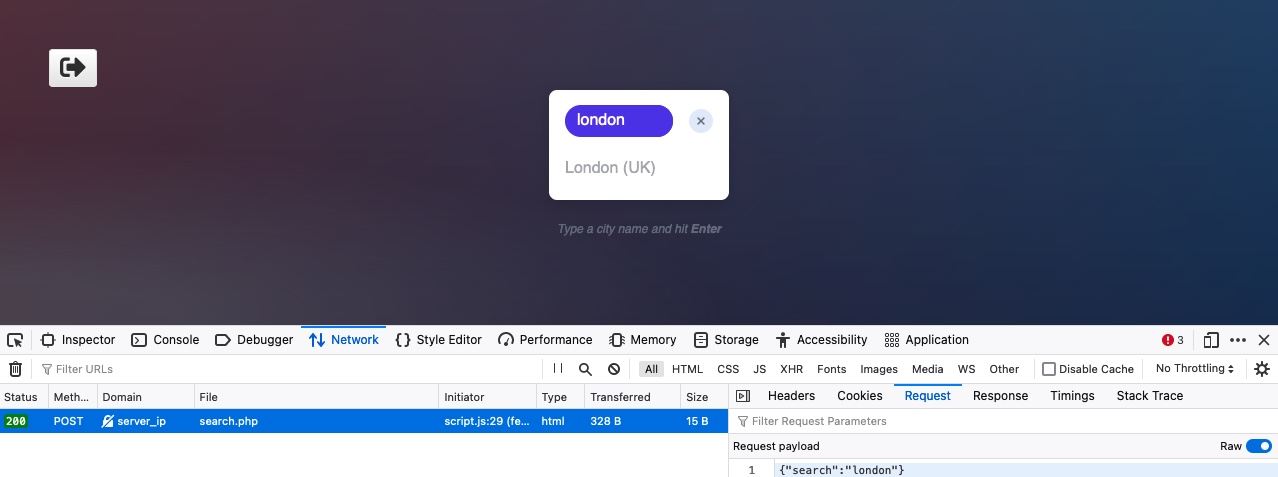
1
{"search":"london"}
Los datos POST parecen estar en formato JSON, por lo que nuestra solicitud debe haber especificado el encabezado Content-Type como application/json.
1
2
3
4
5
6
7
8
9
10
11
12
13
POST /search.php HTTP/1.1
Host: server_ip
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:97.0) Gecko/20100101 Firefox/97.0
Accept: */*
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: http://server_ip/index.php
Content-Type: application/json
Origin: http://server_ip
Content-Length: 19
DNT: 1
Connection: keep-alive
Cookie: PHPSESSID=c1nsa6op7vtk7kdis7bcnbadf1
Intentemos replicar esta solicitud como hicimos anteriormente, pero incluyendo tanto las cabeceras de cookie como las de tipo de contenido, y enviemos nuestra solicitud a search.php.
1
2
$ curl -X POST -d '{"search":"london"}' -b 'PHPSESSID=c1nsa6op7vtk7kdis7bcnbadf1' -H 'Content-Type: application/json' http://<SERVER_IP>:<PORT>/search.php
["London (UK)"]
Pudimos interactuar directamente con la función de búsqueda sin necesidad de iniciar sesión ni interactuar con la interfaz de la aplicación web. Esto puede ser una habilidad esencial a la hora de realizar evaluaciones de aplicaciones web.
CRUD API
APIs
Existen varios tipos de API. Muchas API se utilizan para interactuar con una base de datos, de modo que podamos especificar la tabla y la fila solicitadas en nuestra consulta API y, a continuación, utilizar un método HTTP para realizar la operación necesaria.
Si quisiéramos actualizar la tabla «city» en la base de datos, y la fila que vamos a actualizar tiene el nombre de ciudad «london», entonces la URL sería algo así:
1
curl -X PUT http://<SERVER_IP>:<PORT>/api.php/city/london ...SNIP...
CRUD
Podemos especificar fácilmente la tabla y la fila en la que queremos realizar una operación a través de dichas API. A continuación, podemos utilizar diferentes métodos HTTP para realizar diferentes operaciones en esa fila. En general, las API realizan cuatro operaciones principales en la entidad de la base de datos solicitada.
| Operación | Método HTTP | Descripción |
|---|---|---|
| Create | POST | Añade los datos especificados a la tabla de la base de datos. |
| Read | GET | Lee la entidad especificada de la tabla de la base de datos. |
| Update | PUT | Actualiza los datos de la tabla de base de datos especificada. |
| Delete | DELETE | Elimina la fila especificada de la tabla de la base de datos. |
Estas cuatro operaciones están relacionadas principalmente con las API CRUD comúnmente conocidas, pero el mismo principio también se utiliza en las API REST y en varios otros tipos de API.
No todas las API funcionan de la misma manera, y el control de acceso de los usuarios limitará las acciones que podemos realizar y los resultados que podemos ver.
Read
1
2
3
$ curl http://<SERVER_IP>:<PORT>/api.php/city/london
[{"city_name":"London","country_name":"(UK)"}]
Para que tenga el formato JSON adecuado, podemos canalizar la salida a la utilidad jq, que la formateará correctamente. También silenciaremos cualquier salida innecesaria de cURL con -s.
1
2
3
4
5
6
7
8
$ curl -s http://<SERVER_IP>:<PORT>/api.php/city/london | jq
[
{
"city_name": "London",
"country_name": "(UK)"
}
]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
$ curl -s http://<SERVER_IP>:<PORT>/api.php/city/le | jq
[
{
"city_name": "Leeds",
"country_name": "(UK)"
},
{
"city_name": "Dudley",
"country_name": "(UK)"
},
{
"city_name": "Leicester",
"country_name": "(UK)"
},
...SNIP...
]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
$ curl -s http://<SERVER_IP>:<PORT>/api.php/city/ | jq
[
{
"city_name": "London",
"country_name": "(UK)"
},
{
"city_name": "Birmingham",
"country_name": "(UK)"
},
{
"city_name": "Leeds",
"country_name": "(UK)"
},
...SNIP...
]
Create
Simplemente podemos enviar nuestros datos JSON mediante POST y se añadirán a la tabla. Como esta API utiliza datos JSON, también configuraremos el encabezado Content-Type como JSON.
1
$ curl -X POST http://<SERVER_IP>:<PORT>/api.php/city/ -d '{"city_name":"TEST_City", "country_name":"TEST"}' -H 'Content-Type: application/json'
1
2
3
4
5
6
7
8
curl -s http://<SERVER_IP>:<PORT>/api.php/city/HTB_City | jq
[
{
"city_name": "TEST_City",
"country_name": "TEST"
}
]
Update
PUT se utiliza para actualizar entradas API y modificar sus detalles, mientras que DELETE se utiliza para eliminar una entidad específica.
[!NOTE] El método HTTP PATCH también se puede utilizar para actualizar entradas API en lugar de PUT. Para ser precisos, PATCH se utiliza para actualizar parcialmente una entrada (solo modificar algunos de sus datos, «por ejemplo, solo city_name»), mientras que PUT se utiliza para actualizar toda la entrada. También podemos utilizar el método HTTP OPTIONS para ver cuál de los dos es aceptado por el servidor y, a continuación, utilizar el método adecuado en consecuencia.
El uso de PUT es bastante similar al de POST en este caso, con la única diferencia de que tenemos que especificar el nombre de la entidad que queremos editar en la URL, ya que, de lo contrario, la API no sabrá qué entidad editar.
1
$ curl -X PUT http://<SERVER_IP>:<PORT>/api.php/city/london -d '{"city_name":"New_TEST_City", "country_name":"TEST"}' -H 'Content-Type: application/json'
En el ejemplo vemos que primero especificamos /city/london como nuestra ciudad y pasamos una cadena JSON que contenía «city_name»: «New_TEST_City» en los datos de la solicitud. Por lo tanto, la ciudad de Londres ya no debería existir y debería existir una nueva ciudad con el nombre New_TEST_City.
1
2
3
4
5
6
7
8
$ curl -s http://<SERVER_IP>:<PORT>/api.php/city/New_TEST_City | jq
[
{
"city_name": "New_TEST_City",
"country_name": "TEST"
}
]
[!NOTE] En algunas API, la operación Actualizar también se puede utilizar para crear nuevas entradas. Básicamente, enviaríamos nuestros datos y, si no existen, se crearían. Por ejemplo, en el ejemplo anterior, aunque no existiera una entrada con la ciudad de Londres, se crearía una nueva entrada con los datos que hemos enviado.
DELETE
1
$ curl -X DELETE http://<SERVER_IP>:<PORT>/api.php/city/New_TEST_City
1
2
$ curl -s http://<SERVER_IP>:<PORT>/api.php/city/New_TEST_City | jq
[]
En una aplicación web real, es posible que estas acciones no estén permitidas para todos los usuarios, o se consideraría una vulnerabilidad si cualquiera pudiera modificar o eliminar cualquier entrada. Cada usuario tendría ciertos privilegios sobre lo que puede leer o escribir, donde escribir se refiere a añadir, modificar o eliminar datos.