Reconociento web
Reconocimiento web

El reconocimiento web es la base de una evaluación de seguridad exhaustiva. Este proceso implica recopilar de forma sistemática y meticulosa información sobre un sitio web o una aplicación web específicos.
Constituye una parte fundamental de la fase de «recopilación de información» del proceso de pruebas de penetración.
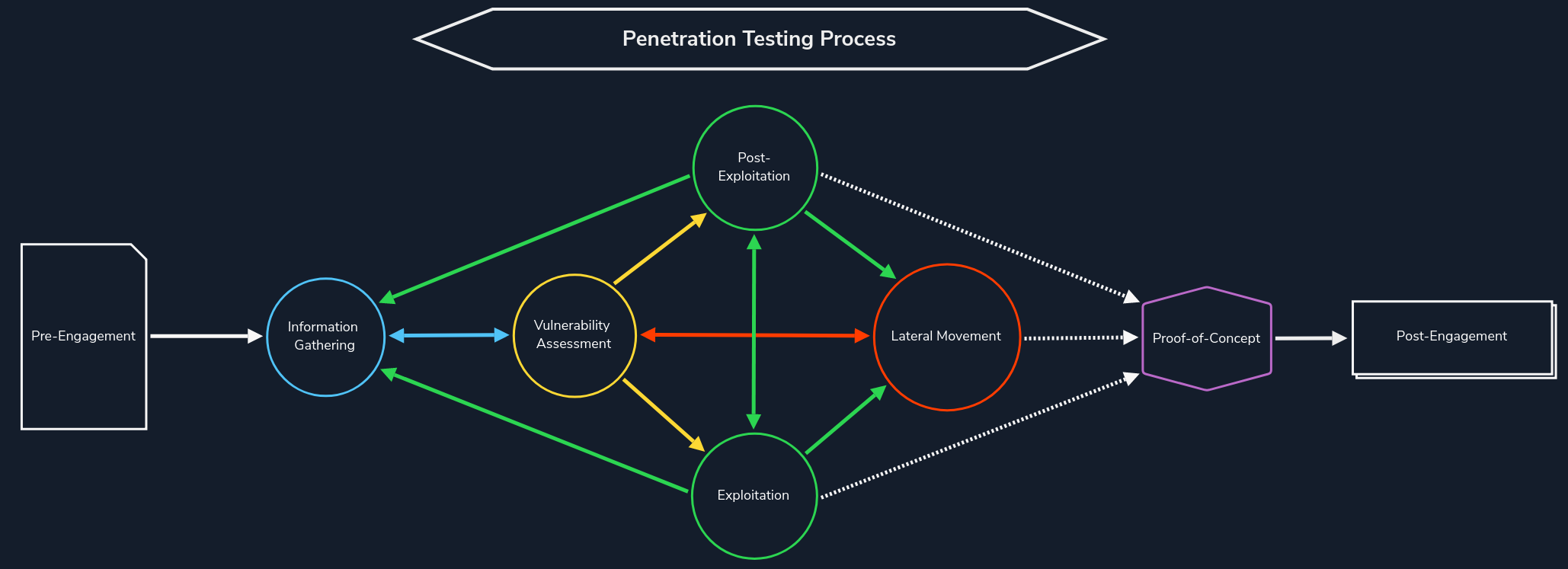
Identificación de activos: Descubrimiento de todos los componentes de acceso público del objetivo, como páginas web, subdominios, direcciones IP y tecnologías utilizadas. Este paso proporciona una visión general completa de la presencia en línea del objetivo.
Descubrimiento de información oculta: localización de información confidencial que podría quedar expuesta inadvertidamente, incluidos archivos de copia de seguridad, archivos de configuración o documentación interna. Estos hallazgos pueden revelar información valiosa y posibles puntos de entrada para ataques.
Análisis de la superficie de ataque: examinar la superficie de ataque del objetivo para identificar posibles vulnerabilidades y puntos débiles. Esto implica evaluar las tecnologías utilizadas, las configuraciones y los posibles puntos de entrada para su explotación.
Recopilación de información: recopilar información que pueda aprovecharse para futuros ataques de explotación o ingeniería social. Esto incluye identificar al personal clave, direcciones de correo electrónico o patrones de comportamiento que puedan explotarse.
Los atacantes aprovechan esta información para adaptar sus ataques, lo que les permite dirigirse a debilidades específicas y eludir las medidas de seguridad. Por el contrario, los defensores utilizan el reconocimiento para identificar y corregir de forma proactiva las vulnerabilidades antes de que los actores maliciosos puedan aprovecharlas.
Tipos de reconocimiento
Activo
En el reconocimiento activo, el atacante interactúa directamente con el sistema objetivo para recopilar información.
| Técnica | Descripción | Ejemplo | Herramientas | Riesgo de detección |
|---|---|---|---|---|
| Port Scanning | Identificación de puertos abiertos y servicios en ejecución en el objetivo. | Usar Nmap para escanear un servidor web en busca de puertos abiertos como el 80 (HTTP) y el 443 (HTTPS). | Nmap, Masscan, Unicornscan | Alto: La interacción directa con el objetivo puede activar los sistemas de detección de intrusiones (IDS) y los cortafuegos. |
| Vulnerability Scanning | Buscar vulnerabilidades conocidas en el objetivo, como software desactualizado o configuraciones incorrectas. | Ejecutar Nessus en una aplicación web para comprobar si hay fallos de inyección SQL o vulnerabilidades de secuencias de comandos entre sitios (XSS). | Nessus, OpenVAS, Nikto | Alta: los escáneres de vulnerabilidades envían cargas útiles de explotación que las soluciones de seguridad pueden detectar. |
| Network Mapping | Mapeo de la topología de red del objetivo, incluidos los dispositivos conectados y sus relaciones. | Utilizar traceroute para determinar la ruta que siguen los paquetes hasta llegar al servidor de destino, revelando posibles saltos de red e infraestructura. | Traceroute, Nmap | Medio a alto: un tráfico de red excesivo o inusual puede levantar sospechas. |
| Banner Grabbing | Recuperación de información de los banners mostrados por los servicios que se ejecutan en el objetivo. | Conectarse a un servidor web en el puerto 80 y examinar el banner HTTP para identificar el software y la versión del servidor web. | Netcat, curl | Bajo: La captura de banners suele implicar una interacción mínima, pero aún así puede registrarse. |
| OS Fingerprinting | Identificar el sistema operativo que se ejecuta en el objetivo. | Utilizar las capacidades de detección del sistema operativo de Nmap (-O) para determinar si el objetivo ejecuta Windows, Linux u otro sistema operativo. | Nmap, Xprobe2 | Bajo: La identificación del sistema operativo suele ser pasiva, pero algunas técnicas avanzadas pueden detectarse. |
| Service Enumeration | Determinación de las versiones específicas de los servicios que se ejecutan en los puertos abiertos | Utilizar la detección de la versión del servicio de Nmap (-sV) para determinar si un servidor web ejecuta Apache 2.4.50 o Nginx 1.18.0. | Nmap | Bajo: Al igual que la captura de banners, la enumeración de servicios se puede registrar, pero es menos probable que active alertas. |
| Web Spidering | Rastrear el sitio web de destino para identificar páginas web, directorios y archivos. | Ejecutar un rastreador web como Burp Suite Spider u OWASP ZAP Spider para trazar la estructura de un sitio web y descubrir recursos ocultos. | Burp Suite Spider, OWASP ZAP Spider, Scrapy (personalizable) | Bajo a medio: Se puede detectar si el comportamiento del rastreador no está cuidadosamente configurado para imitar el tráfico legítimo. |
Pasivo
Por el contrario, el reconocimiento pasivo consiste en recopilar información sobre el objetivo sin interactuar directamente con él. Para ello, se analiza la información y los recursos disponibles públicamente.
| Técnica | Descripción | Ejemplo | Herramientas | Riesgo de detección |
|---|---|---|---|---|
| Search Engine Queries | Utilizar motores de búsqueda para descubrir información sobre el objetivo, incluyendo sitios web, perfiles en redes sociales y artículos de noticias. | Buscar en Google «empleados de [nombre del destino]» para encontrar información sobre los empleados o perfiles en redes sociales. | Google, DuckDuckGo, Bing, and specialised search engines (e.g., Shodan) | Muy bajo: Las consultas en motores de búsqueda son una actividad normal en Internet y es poco probable que activen alertas. |
| WHOIS Lookups | Consultar bases de datos WHOIS para recuperar detalles del registro de dominios. | Realizar una búsqueda WHOIS en un dominio de destino para encontrar el nombre del registrante, la información de contacto y los servidores de nombres. | whois command-line tool, online WHOIS lookup services | Muy bajo: Las consultas WHOIS son legítimas y no levantan sospechas. |
| DNS | Análisis de registros DNS para identificar subdominios, servidores de correo y otras infraestructuras. | Usar dig para enumerar los subdominios de un dominio de destino. | dig, nslookup, host, dnsenum, fierce, dnsrecon | Muy bajo: Las consultas DNS son esenciales para navegar por Internet y no suelen marcarse como sospechosas. |
| Web Archive Analysis | Examinar instantáneas históricas del sitio web del objetivo para identificar cambios, vulnerabilidades o información oculta. | Utilizar Wayback Machine para ver versiones anteriores de un sitio web de destino y comprobar cómo ha cambiado con el tiempo. | Wayback Machine | Muy bajo: Acceder a versiones archivadas de sitios web es una actividad normal. |
| Social Media Analysis | Recopilar información de plataformas de redes sociales como LinkedIn, Twitter o Facebook. | Buscar en LinkedIn a los empleados de una organización objetivo para conocer sus funciones, responsabilidades y posibles objetivos de ingeniería social. | LinkedIn, Twitter, Facebook, specialised OSINT tools | Muy bajo: acceder a perfiles públicos en redes sociales no se considera intrusivo. |
| Code Repositories | Analizar repositorios de código de acceso público, como GitHub, en busca de credenciales expuestas o vulnerabilidades. | Buscar en GitHub fragmentos de código o repositorios relacionados con el objetivo que puedan contener información confidencial o vulnerabilidades de código. | GitHub, GitLab | Muy bajo: los repositorios de código están destinados al acceso público, y buscarlos no es sospechoso. |
WHOIS
Asociado principalmente con nombres de dominio, WHOIS también puede proporcionar detalles sobre bloques de direcciones IP y sistemas autónomos. Permite buscar quién es el propietario o responsable de diversos activos en línea.
- Domain Name: el nombre de dominio en sí (por ejemplo, ejemplo.com).
- Registrar: la empresa donde se registró el dominio (por ejemplo, GoDaddy, Namecheap).
- Registrant Contact: la persona u organización que registró el dominio.
- Administrative Contact: la persona responsable de gestionar el dominio.
- Technical Contact: la persona que se encarga de los problemas técnicos relacionados con el dominio.
- Fechas de creación y caducidad: cuándo se registró el dominio y cuándo caduca.
- Name Servers: servidores que traducen el nombre de dominio a una dirección IP.
1
$ sudo apt update
1
$ sudo apt install whois -y
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
$ whois facebook.com
Domain Name: FACEBOOK.COM
Registry Domain ID: 2320948_DOMAIN_COM-VRSN
Registrar WHOIS Server: whois.registrarsafe.com
Registrar URL: http://www.registrarsafe.com
Updated Date: 2024-04-24T19:06:12Z
Creation Date: 1997-03-29T05:00:00Z
Registry Expiry Date: 2033-03-30T04:00:00Z
Registrar: RegistrarSafe, LLC
Registrar IANA ID: 3237
Registrar Abuse Contact Email: abusecomplaints@registrarsafe.com
Registrar Abuse Contact Phone: +1-650-308-7004
Domain Status: clientDeleteProhibited https://icann.org/epp#clientDeleteProhibited
Domain Status: clientTransferProhibited https://icann.org/epp#clientTransferProhibited
Domain Status: clientUpdateProhibited https://icann.org/epp#clientUpdateProhibited
Domain Status: serverDeleteProhibited https://icann.org/epp#serverDeleteProhibited
Domain Status: serverTransferProhibited https://icann.org/epp#serverTransferProhibited
Domain Status: serverUpdateProhibited https://icann.org/epp#serverUpdateProhibited
Name Server: A.NS.FACEBOOK.COM
Name Server: B.NS.FACEBOOK.COM
Name Server: C.NS.FACEBOOK.COM
Name Server: D.NS.FACEBOOK.COM
DNSSEC: unsigned
URL of the ICANN Whois Inaccuracy Complaint Form: https://www.icann.org/wicf/
>>> Last update of whois database: 2024-06-01T11:24:10Z <<<
Domain Registration:
Registrar: RegistrarSafe, LLCCreation Date: 1997-03-29Expiry Date: 2033-03-30
Estos datos indican que el dominio está registrado en RegistrarSafe, LLC, y que lleva activo un periodo considerable, lo que sugiere su legitimidad.
Domain Owner:
Registrant/Admin/Tech Organization: Meta Platforms, Inc.Registrant/Admin/Tech Contact: Domain Admin
Esta información identifica a Meta Platforms, Inc. como la organización detrás de facebook.com, y a «Domain Admin» como el punto de contacto para asuntos relacionados con el dominio.
Domain Status:
clientDeleteProhibited,clientTransferProhibited,clientUpdateProhibited,serverDeleteProhibited,serverTransferProhibited, andserverUpdateProhibited
Estos estados indican que el dominio está protegido contra cambios, transferencias o eliminaciones no autorizadas tanto en el lado del cliente como en el del servidor. Esto pone de relieve un fuerte énfasis en la seguridad y el control sobre el dominio.
Name Servers:
A.NS.FACEBOOK.COM,B.NS.FACEBOOK.COM,C.NS.FACEBOOK.COM,D.NS.FACEBOOK.COM
Todos estos servidores de nombres se encuentran dentro del dominio facebook.com, lo que sugiere que Meta Platforms, Inc. gestiona su infraestructura DNS. Es una práctica habitual que las grandes organizaciones mantengan el control y la fiabilidad sobre su resolución DNS.
DNS
Tu ordenador solicita direcciones (consulta DNS): cuando introduces el nombre de dominio, tu ordenador comprueba primero su memoria (caché) para ver si recuerda la dirección IP de una visita anterior. Si no es así, se pone en contacto con un resolutor DNS, normalmente proporcionado por tu proveedor de servicios de Internet (ISP).
El resolutor DNS comprueba su mapa (búsqueda recursiva): el resolutor también tiene una caché y, si no encuentra la dirección IP allí, comienza un recorrido por la jerarquía DNS. Empieza preguntando a un servidor de nombres raíz, que es como el bibliotecario de Internet.
El servidor raíz de nombres indica el camino: el servidor raíz no conoce la dirección exacta, pero sabe quién la conoce: el servidor de nombres de dominio de nivel superior (TLD) responsable de la terminación del dominio (por ejemplo, .com, .org). Indica al resolutor la dirección correcta.
El servidor de nombres TLD lo reduce: el servidor de nombres TLD es como un mapa regional. Sabe qué servidor de nombres autoritativo es responsable del dominio específico que estás buscando (por ejemplo, example.com) y envía el resolutor allí.
El servidor de nombres autoritativo proporciona la dirección: El servidor de nombres autoritativo es la última parada. Es como la dirección postal del sitio web que desea visitar. Contiene la dirección IP correcta y la envía de vuelta al resolutor.
El resolutor DNS devuelve la información: el resolutor recibe la dirección IP y se la envía a tu ordenador. También la recuerda durante un tiempo (la almacena en caché), por si quieres volver a visitar el sitio web pronto.
Tu ordenador se conecta: ahora que tu ordenador conoce la dirección IP, puede conectarse directamente al servidor web que aloja el sitio web y puedes empezar a navegar.
Archivo local hosts
El archivo hosts permite modificaciones locales directas. Esto puede resultar especialmente útil para el desarrollo, la resolución de problemas o el bloqueo de sitios web.
El archivo hosts se encuentra en C:\Windows\System32\drivers\etc\hosts en Windows y en /etc/hosts en Linux y MacOS.
127.0.0.1 localhost
192.168.1.10 devserver.local
Podemos bloquear también sitios web no deseados redirigiendo sus dominios a una dirección IP inexistente.
0.0.0.0 unwanted-site.com
Conceptos clave
En el Sistema de Nombres de Dominio (DNS), una zona es una parte diferenciada del espacio de nombres de dominio que gestiona una entidad o administrador específico. Piensa en ella como un contenedor virtual para un conjunto de nombres de dominio. Por ejemplo, example.com y todos sus subdominios (como mail.example.com o blog.example.com) normalmente pertenecerían a la misma zona DNS.
El archivo de zona, un archivo de texto que reside en un servidor DNS, define los registros de recursos dentro de esta zona, proporcionando información crucial para traducir los nombres de dominio a direcciones IP.
$TTL 3600 ; Default Time-To-Live (1 hour)
@ IN SOA ns1.example.com. admin.example.com. (
2024060401 ; Serial number (YYYYMMDDNN)
3600 ; Refresh interval
900 ; Retry interval
604800 ; Expire time
86400 ) ; Minimum TTL
@ IN NS ns1.example.com.
@ IN NS ns2.example.com.
@ IN MX 10 mail.example.com.
www IN A 192.0.2.1
mail IN A 198.51.100.1
ftp IN CNAME www.example.com.
Este archivo define los servidores de nombres autoritativos (registros NS), el servidor de correo (registro MX) y las direcciones IP (registros A) para varios hosts dentro del dominio example.com.
| Concepto | Explicación | Ejemplo |
|---|---|---|
| DNS Resolver | Un servidor que traduce nombres de dominio a direcciones IP. | El servidor DNS de tu proveedor de servicios de Internet o resolutores públicos como Google DNS (8.8.8.8) |
| Root Name Server | Los servidores de nivel superior en la jerarquía DNS. | Hay 13 servidores raíz en todo el mundo, denominados de la A a la M: a.root-servers.net |
| TLD Name Server | Servidores responsables de dominios de nivel superior específicos (por ejemplo, .com, .org). | Verisign para .com, PIR para .org |
| Authoritative Name Server | El servidor que contiene la dirección IP real de un dominio. | A menudo gestionados por proveedores de alojamiento o registradores de dominios. |
Tipos de registros DNS
| Tipo | Nombre | Descripción | Ejemplo |
|---|---|---|---|
| A | Address Record | Asigna un nombre de host a su dirección IPv4. | www.example.com. IN A 192.0.2.1 |
| AAAA | IPv6 Address Record | Asigna un nombre de host a su dirección IPv6. | www.example.com. IN AAAA 2001:db8:85a3::8a2e:370:7334 |
| CNAME | Canonical Name Record | Crea un alias para un nombre de host, apuntándolo a otro nombre de host. | blog.example.com. IN CNAME webserver.example.net. |
| MX | Mail Exchange Record | Especifica los servidores de correo responsables de gestionar el correo electrónico del dominio. | example.com. IN MX 10 mail.example.com. |
| NS | Name Server Record | Delega una zona DNS a un servidor de nombres autoritativo específico. | example.com. IN NS ns1.example.com. |
| TXT | Text Record | Almacena información de texto arbitraria, que suele utilizarse para la verificación de dominios o políticas de seguridad. | example.com. IN TXT "v=spf1 mx -all" (SPF record) |
| SOA | Start of Authority Record | Especifica información administrativa sobre una zona DNS, incluyendo el servidor de nombres principal, el correo electrónico de la persona responsable y otros parámetros. | example.com. IN SOA ns1.example.com. admin.example.com. 2024060301 10800 3600 604800 86400 |
| SRV | Service Record | Define el nombre de host y el número de puerto para servicios específicos. | _sip._udp.example.com. IN SRV 10 5 5060 sipserver.example.com. |
| PTR | Pointer Record | Se utiliza para búsquedas DNS inversas, asignando una dirección IP a un nombre de host. | 1.2.0.192.in-addr.arpa. IN PTR www.example.com. |
«IN» es simplemente una convención que indica que el registro se aplica a los protocolos estándar de Internet que utilizamos hoy en día.
Descubrimiento de activos: los registros DNS pueden revelar una gran cantidad de información, incluidos subdominios, servidores de correo y registros de servidores de nombres. Por ejemplo, un registro CNAME que apunte a un servidor obsoleto (dev.example.com CNAME oldserver.example.net) podría dar lugar a un sistema vulnerable.
Mapeo de la infraestructura de red: puede crear un mapa completo de la infraestructura de red del objetivo analizando los datos DNS. Por ejemplo, identificar los servidores de nombres (registros NS) de un dominio puede revelar el proveedor de alojamiento utilizado, mientras que un registro A para loadbalancer.example.com puede localizar un equilibrador de carga. Esto ayuda a comprender cómo se conectan los diferentes sistemas, identificar el flujo de tráfico y localizar posibles puntos de o debilidades que podrían explotarse.
Su pervisión de cambios: la supervisión continua de los registros DNS puede revelar cambios en la infraestructura del objetivo a lo largo del tiempo. Por ejemplo, la aparición repentina de un nuevo subdominio (vpn.example.com) podría indicar un nuevo punto de entrada a la red, mientras que un registro TXT que contenga un valor como 1password=… sugiere claramente que la organización utiliza 1Password, lo que podría aprovecharse para ataques de ingeniería social o campañas de phishing dirigidas.
Herramientas DNS
| Herramienta | Funcionalidades | Ejemplo |
|---|---|---|
| dig | Herramienta versátil de búsqueda de DNS que admite varios tipos de consultas (A, MX, NS, TXT, etc.) y ofrece resultados detallados. | Consultas DNS manuales, transferencias de zona (si están permitidas), resolución de problemas DNS y análisis en profundidad de registros DNS. |
| nslookup | Herramienta de búsqueda DNS más sencilla, principalmente para registros A, AAAA y MX. | Consultas DNS básicas, comprobaciones rápidas de resolución de dominios y registros de servidores de correo. |
| host | Herramienta optimizada de búsqueda de DNS con resultados concisos. | Comprobaciones rápidas de registros A, AAAA y MX. |
| dnsenum | Herramienta automatizada de enumeración de DNS, ataques de diccionario, fuerza bruta, transferencias de zona (si están permitidas). | Descubrir subdominios y recopilar información DNS de manera eficiente. |
| fierce | Herramienta de reconocimiento DNS y enumeración de subdominios con búsqueda recursiva y detección de “wildcards”. | Interfaz fácil de usar para el reconocimiento de DNS, la identificación de subdominios y posibles objetivos. |
| dnsrecon | Combina múltiples técnicas de reconocimiento DNS y admite varios formatos de salida. | Enumeración exhaustiva de DNS, identificación de subdominios y recopilación de registros DNS para su posterior análisis. |
| theHarvester | Herramienta OSINT que recopila información de diversas fuentes, incluidos registros DNS (direcciones de correo electrónico). | Recopilación de direcciones de correo electrónico, información de empleados y otros datos asociados a un dominio procedentes de múltiples fuentes. |
| Online DNS Lookup Services | Interfaces fáciles de usar para realizar búsquedas DNS. | Búsquedas DNS rápidas y sencillas, muy útiles cuando no se dispone de herramientas de línea de comandos, para comprobar la disponibilidad de un dominio o obtener información básica. |
DIG - Domain Information Groper
El comando dig (Domain Information Groper) es una utilidad potente para consultar servidores DNS y recuperar diversos tipos de registros DNS.
| Comando | Descripción |
|---|---|
dig domain.com | Realiza una búsqueda predeterminada del registro A del dominio. |
dig domain.com A | Recupera la dirección IPv4 (registro A) asociada al dominio. |
dig domain.com AAAA | Recupera la dirección IPv6 (registro AAAA) asociada al dominio. |
dig domain.com MX | Encuentra los servidores de correo (registros MX) responsables del dominio. |
dig domain.com NS | Identifica los servidores de nombres autoritativos del dominio. |
dig domain.com TXT | Recupera cualquier registro TXT asociado al dominio. |
dig domain.com CNAME | Recupera el registro de nombre canónico (CNAME) del dominio. |
dig domain.com SOA | Recupera el registro de inicio de autoridad (SOA) del dominio. |
dig @1.1.1.1 domain.com | Especifica un servidor de nombres específico para la consulta; en este caso, 1.1.1.1. |
dig +trace domain.com | Muestra toda la ruta de resolución DNS. |
dig -x 192.168.1.1 | Realiza una búsqueda inversa de la dirección IP 192.168.1.1 para encontrar el nombre de host asociado. Es posible que necesites especificar un servidor de nombres. |
dig +short domain.com | Proporciona una respuesta corta y concisa a la consulta. |
dig +noall +answer domain.com | Muestra únicamente la sección de respuesta del resultado de la consulta. |
dig domain.com ANY | Recupera todos los registros DNS disponibles del dominio (Nota: Muchos servidores DNS ignoran las consultas ANY para reducir la carga y prevenir abusos, según el RFC 8482). |
[!NOTE] Advertencia Algunos servidores pueden detectar y bloquear consultas DNS excesivas. Usa estas herramientas con precaución y respeta los límites de frecuencia. ```shell-session $ dig google.com
; «» DiG 9.18.24-0ubuntu0.22.04.1-Ubuntu «» google.com ;; global options: +cmd ;; Got answer: ;; -»HEADER«- opcode: QUERY, status: NOERROR, id: 16449 ;; flags: qr rd ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0 ;; WARNING: recursion requested but not available
;; QUESTION SECTION: ;google.com. IN A
;; ANSWER SECTION: google.com. 0 IN A 142.251.47.142
;; Query time: 0 msec ;; SERVER: 172.23.176.1#53(172.23.176.1) (UDP) ;; WHEN: Thu Jun 13 10:45:58 SAST 2024 ;; MSG SIZE rcvd: 54
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
Este resultado es el producto de una consulta DNS usando el comando **`dig`** para el dominio **google.com**.
##### **Encabezado (Header)**
`;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 16449`
- **opcode: QUERY** – Indica que es una consulta estándar.
- **status: NOERROR** – La consulta se completó correctamente, sin errores.
- **id: 16449** – Identificador único asignado a esta consulta.
`;; flags: qr rd ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0`
Describe las banderas (flags) incluidas en el encabezado DNS:
- **qr** – Indica que es una respuesta (Query Response).
- **rd** – Se solicitó recursión (Recursion Desired).
- **ad** – Los datos son considerados auténticos por el resolvedor (Authentic Data).
- **QUERY: 1** – Número de preguntas (1).
- **ANSWER: 1** – Número de respuestas (1).
- **AUTHORITY: 0** – Sin registros de autoridad.
- **ADDITIONAL: 0** – Sin registros adicionales.
`;; WARNING: recursion requested but not available`
Se solicitó recursión, pero el servidor no la admite.
##### **Sección de Pregunta (Question Section)**
`;google.com. IN A`
Esto muestra la pregunta enviada:
**"¿Cuál es la dirección IPv4 (registro A) de google.com?"**
##### **Sección de Respuesta (Answer Section)**
`google.com. 0 IN A 142.251.47.142`
Respuesta a la consulta:
- **google.com** – Nombre de dominio consultado.
- **0** – Tiempo de vida (TTL) del registro, en segundos (0 indica que no se puede almacenar en caché).
- **IN** – Clase de Internet.
- **A** – Tipo de registro (IPv4).
- **142.251.47.142** – Dirección IP correspondiente.
##### **Pie de Página (Footer)**
`;; Query time: 0 msec`
Tiempo que tardó la consulta en completarse: **0 milisegundos**.
`;; SERVER: 172.23.176.1#53(172.23.176.1) (UDP)`
Servidor DNS que respondió: **172.23.176.1**, usando el puerto **53** sobre **UDP**.
`;; WHEN: Thu Jun 13 10:45:58 SAST 2024`
Fecha y hora en que se realizó la consulta: **jueves 13 de junio de 2024 a las 10:45:58 (hora SAST)**.
`;; MSG SIZE rcvd: 54`
Tamaño del mensaje DNS recibido: **54 bytes**.
## Subdominios
Los subdominios son extensiones del dominio principal, y a menudo se crean para organizar y separar diferentes secciones o funcionalidades de un sitio web. Por ejemplo, una empresa podría usar:
- **blog.example.com** para su blog,
- **shop.example.com** para su tienda en línea, o
- **mail.example.com** para sus servicios de correo electrónico.
###### Entornos de Desarrollo y Pruebas (Staging):
Las empresas suelen utilizar subdominios para probar nuevas funciones o actualizaciones antes de implementarlas en el sitio principal. Debido a medidas de seguridad más relajadas, estos entornos a veces contienen **vulnerabilidades** o **información sensible expuesta**.
###### Portales de Inicio de Sesión Ocultos:
Algunos subdominios alojan paneles administrativos u otras páginas de inicio de sesión que **no están pensadas para acceso público**. Para los atacantes que buscan acceso no autorizado, estos representan **objetivos atractivos**.
###### Aplicaciones Obsoletas (Legacy):
Aplicaciones web antiguas y olvidadas pueden residir en subdominios, con software **desactualizado y vulnerabilidades conocidas** que pueden ser explotadas fácilmente.
###### Información Sensible Expuesta:
Los subdominios también pueden exponer, sin querer, **documentos confidenciales**, **datos internos** o **archivos de configuración** que podrían ser **valiosos para un atacante**.
#### Enumeración
Desde una perspectiva DNS, los subdominios suelen estar representados por **registros A** (o **AAAA** en el caso de direcciones IPv6), los cuales asignan el nombre del subdominio a su correspondiente dirección IP.
Además, también se pueden utilizar **registros CNAME**, que sirven para crear **alias** de subdominios, apuntándolos a otros dominios o subdominios.
##### Activa
Esto implica interactuar directamente con los servidores DNS del dominio objetivo para descubrir subdominios. Un método es intentar una transferencia de zona DNS, donde un servidor mal configurado podría filtrar inadvertidamente una lista completa de subdominios.
Una técnica activa más común es la enumeración por fuerza bruta.
Herramientas como **dnsenum**, **ffuf** y **gobuster** pueden automatizar este proceso, utilizando listas de palabras con nombres de subdominios comunes o listas personalizadas generadas a partir de patrones específicos.
##### Pasiva
Esto se basa en fuentes externas de información para descubrir subdominios sin consultar directamente los servidores DNS del objetivo. Una fuente valiosa son los **registros de Transparencia de Certificados (Certificate Transparency, CT)**, repositorios públicos de certificados SSL/TLS. Estos certificados suelen incluir una lista de subdominios asociados en su campo **Subject Alternative Name (SAN)**, proporcionando una gran cantidad de objetivos potenciales.
Empleando operadores de búsqueda especializados (por ejemplo, `site:`) puedes filtrar resultados para mostrar únicamente subdominios relacionados con el dominio objetivo.
Además, existen diversas bases de datos y herramientas en línea que agregan datos DNS de múltiples fuentes, permitiéndote buscar subdominios sin interactuar directamente con el objetivo.
### Fuerza bruta sobre subdominios
El proceso se divide en cuatro pasos:
1. **Selección de la lista de palabras (wordlist):**
El proceso comienza seleccionando una lista de palabras que contenga posibles nombres de subdominios. Estas listas pueden ser:
- **De propósito general:** Contienen una amplia gama de nombres de subdominios comunes (p. ej., `dev`, `staging`, `blog`, `mail`, `admin`, `test`). Esta aproximación es útil cuando no se conocen las convenciones de nombres del objetivo.
- **Dirigidas (targeted):** Enfocadas en industrias, tecnologías o patrones de nombres específicos relevantes para el objetivo. Este enfoque es más eficiente y reduce las probabilidades de falsos positivos.
- **Personalizadas:** Puedes crear tu propia lista basada en palabras clave, patrones o inteligencia recopilada de otras fuentes.
2. **Iteración y consultas:**
Un script o herramienta recorre la lista de palabras, concatenando cada palabra o frase con el dominio principal (p. ej., `example.com`) para generar nombres de subdominio potenciales (p. ej., `dev.example.com`, `staging.example.com`).
3. **Búsqueda DNS:**
Se realiza una consulta DNS para cada subdominio potencial para verificar si se resuelve a una dirección IP. Normalmente se usan los tipos de registro **A** o **AAAA**.
4. **Filtrado y validación:**
Si un subdominio se resuelve correctamente, se añade a la lista de subdominios válidos. Pueden realizarse pasos adicionales de validación para confirmar la existencia y funcionalidad del subdominio (por ejemplo, intentando acceder a él mediante un navegador web).
|**Herramienta**|**Descripción**|
|---|---|
|`dnsenum`|Herramienta integral de enumeración DNS que soporta ataques por diccionario y fuerza bruta para descubrir subdominios.|
|`fierce`|Herramienta fácil de usar para descubrimiento recursivo de subdominios, con detección de comodines (wildcard) y una interfaz sencilla.|
|`dnsrecon`|Herramienta versátil que combina múltiples técnicas de reconocimiento DNS y ofrece formatos de salida personalizables.|
|`amass`|Herramienta en mantenimiento activo enfocada en el descubrimiento de subdominios, conocida por su integración con otras herramientas y sus extensas fuentes de datos.|
|`assetfinder`|Herramienta simple pero efectiva para encontrar subdominios usando diversas técnicas; ideal para escaneos rápidos y ligeros.|
|`puredns`|Herramienta potente y flexible de fuerza bruta DNS, capaz de resolver y filtrar resultados de forma efectiva.|
### DNSEnum
`dnsenum` es una herramienta de línea de comandos versátil y ampliamente utilizada escrita en Perl. Es un conjunto de herramientas integral para el reconocimiento DNS, que proporciona diversas funcionalidades para recopilar información sobre la infraestructura DNS de un dominio objetivo y sus posibles subdominios.
- **Enumeración de registros DNS:** `dnsenum` puede recuperar diversos registros DNS, incluidos A, AAAA, NS, MX y TXT, proporcionando una visión completa de la configuración DNS del objetivo.
- **Intentos de transferencia de zona:** La herramienta intenta automáticamente transferencias de zona desde los servidores de nombres descubiertos. Aunque la mayoría de los servidores están configurados para prevenir transferencias de zona no autorizadas, un intento exitoso puede revelar una gran cantidad de información DNS.
- **Fuerza bruta de subdominios:** `dnsenum` soporta la enumeración por fuerza bruta de subdominios usando una lista de palabras. Esto implica probar sistemáticamente nombres de subdominios potenciales contra el dominio objetivo para identificar los válidos.
- Scrapping de Google:** La herramienta puede recolectar resultados de búsqueda de Google para encontrar subdominios adicionales que podrían no aparecer directamente en los registros DNS.
- **Búsqueda inversa (reverse lookup):** `dnsenum` puede realizar búsquedas DNS inversas para identificar dominios asociados a una dirección IP determinada, lo que potencialmente revela otros sitios alojados en el mismo servidor.
- **Consultas WHOIS:** La herramienta también puede realizar consultas WHOIS para recopilar información sobre la propiedad del dominio y detalles de registro.
```bash
dnsenum --enum inlanefreight.com -f /usr/share/seclists/Discovery/DNS/subdomains-top1million-20000.txt -r
dnsenum --enum inlanefreight.com: Especificamos el dominio objetivo que queremos enumerar, junto con el atajo--enumpara activar varias opciones de ajuste.-f /usr/share/seclists/Discovery/DNS/subdomains-top1million-20000.txt: Indicamos la ruta a la wordlist de SecLists que usaremos para la fuerza bruta. Ajusta la ruta si tu instalación de SecLists está en una ubicación distinta.-r: Esta opción habilita la fuerza bruta recursiva de subdominios, es decir, sidnsenumencuentra un subdominio, intentará a su vez enumerar subdominios de ese subdominio.
DNS Zone Transfers
Este mecanismo, diseñado para replicar registros DNS entre servidores de DNS.
Una transferencia de zona DNS es, básicamente, una copia completa de todos los registros DNS dentro de una zona (un dominio y sus subdominios) de un servidor de nombres a otro. Este proceso es esencial para mantener la coherencia y la redundancia entre los servidores DNS. Sin embargo, si no se protege adecuadamente, terceros no autorizados pueden descargar todo el archivo de zona, revelando una lista completa de subdominios, sus direcciones IP asociadas y otros datos DNS confidenciales.
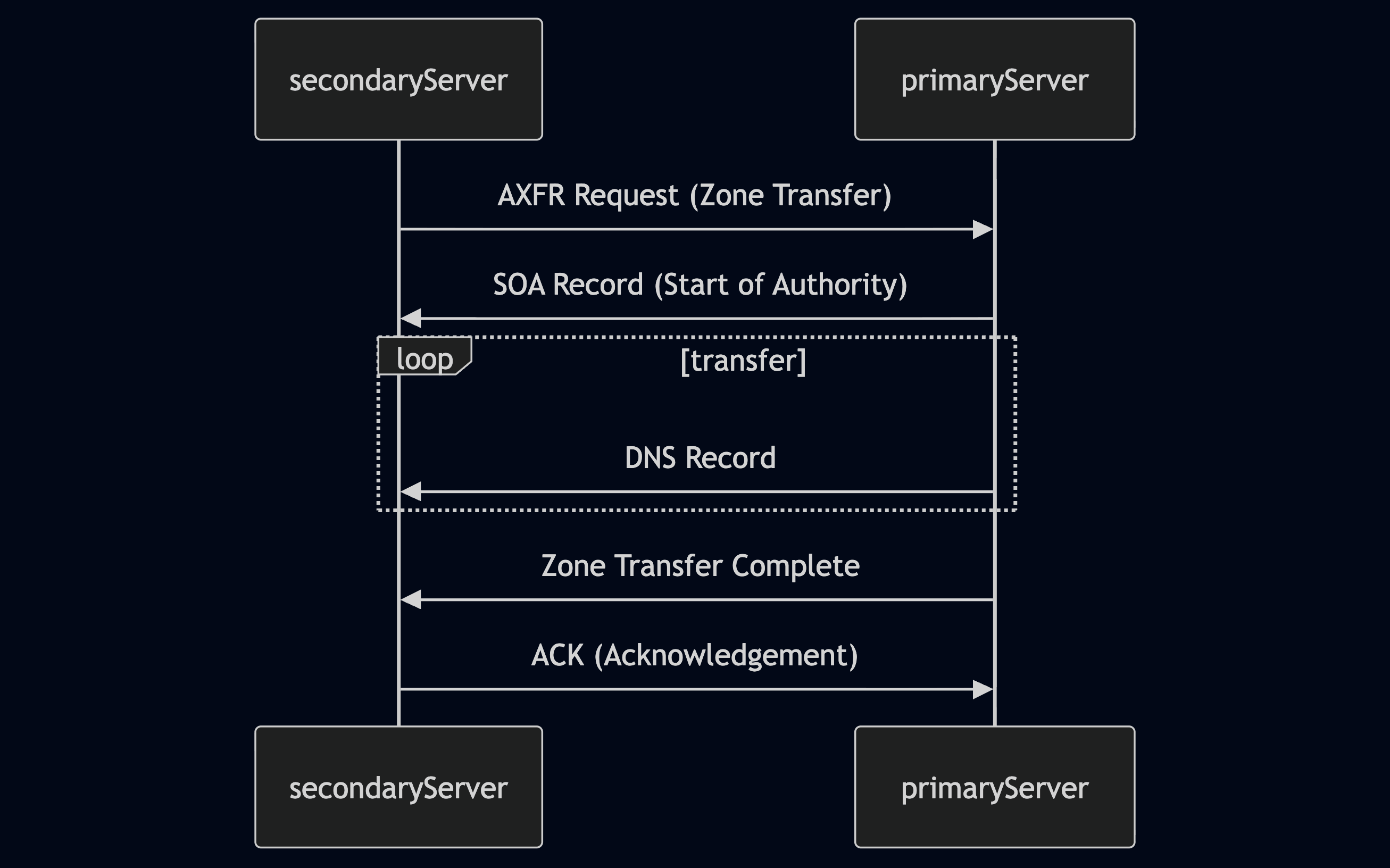
Solicitud de Transferencia de Zona (AXFR): El servidor DNS secundario inicia el proceso enviando una solicitud de transferencia de zona al servidor primario. Esta solicitud generalmente utiliza el tipo AXFR (Transferencia Completa de Zona).
Transferencia del Registro SOA: Al recibir la solicitud (y potencialmente autenticar al servidor secundario), el servidor primario responde enviando su registro de Inicio de Autoridad (SOA). El registro SOA contiene información vital sobre la zona, incluyendo su número de serie, que ayuda al servidor secundario a determinar si sus datos de zona están actualizados.
Transmisión de Registros DNS: Luego, el servidor primario transfiere todos los registros DNS de la zona al servidor secundario, uno por uno. Esto incluye registros como A, AAAA, MX, CNAME, NS y otros que definen los subdominios del dominio, servidores de correo, servidores de nombres y otras configuraciones.
Transferencia de Zona Completa: Una vez que todos los registros han sido transmitidos, el servidor primario señala el final de la transferencia de zona. Esta notificación informa al servidor secundario que ha recibido una copia completa de los datos de la zona.
Reconocimiento (ACK): El servidor secundario envía un mensaje de reconocimiento al servidor primario, confirmando la recepción y el procesamiento exitoso de los datos de la zona. Esto completa el proceso de transferencia de zona.
La vulnerabilidad
Un servidor DNS mal configurado puede convertir este proceso en una importante vulnerabilidad de seguridad.
Revela un mapa completo de la infraestructura DNS del objetivo, que incluye:
Subdominios: Una lista completa de subdominios, muchos de los cuales podrían no estar vinculados desde el sitio web principal ni ser fácilmente descubribles por otros medios. Estos subdominios ocultos podrían alojar servidores de desarrollo, entornos de pruebas (staging), paneles administrativos u otros recursos sensibles.
Direcciones IP: Las direcciones IP asociadas a cada subdominio, proporcionando objetivos potenciales para un mayor reconocimiento o ataques.
Registros de servidores de nombres: Detalles sobre los servidores de nombres autorizados para el dominio, que revelan el proveedor de alojamiento y posibles malas configuraciones.
Los servidores DNS modernos suelen estar configurados para permitir transferencias de zona solo a servidores secundarios de confianza, lo que garantiza que los datos confidenciales de la zona permanezcan confidenciales.
Ejemplo de explotación
1
$ dig axfr @nsztm1.digi.ninja zonetransfer.me
Este comando indica a dig que solicite una transferencia completa de zona (axfr) al servidor DNS responsable de zonetransfer.me. Si el servidor está mal configurado y permite la transferencia, recibirás una lista completa de los registros DNS del dominio, incluidos todos los subdominios.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
$ dig axfr @nsztm1.digi.ninja zonetransfer.me
; <<>> DiG 9.18.12-1~bpo11+1-Debian <<>> axfr @nsztm1.digi.ninja zonetransfer.me
; (1 server found)
;; global options: +cmd
zonetransfer.me. 7200 IN SOA nsztm1.digi.ninja. robin.digi.ninja. 2019100801 172800 900 1209600 3600
zonetransfer.me. 300 IN HINFO "Casio fx-700G" "Windows XP"
zonetransfer.me. 301 IN TXT "google-site-verification=tyP28J7JAUHA9fw2sHXMgcCC0I6XBmmoVi04VlMewxA"
zonetransfer.me. 7200 IN MX 0 ASPMX.L.GOOGLE.COM.
...
zonetransfer.me. 7200 IN A 5.196.105.14
zonetransfer.me. 7200 IN NS nsztm1.digi.ninja.
zonetransfer.me. 7200 IN NS nsztm2.digi.ninja.
_acme-challenge.zonetransfer.me. 301 IN TXT "6Oa05hbUJ9xSsvYy7pApQvwCUSSGgxvrbdizjePEsZI"
_sip._tcp.zonetransfer.me. 14000 IN SRV 0 0 5060 www.zonetransfer.me.
14.105.196.5.IN-ADDR.ARPA.zonetransfer.me. 7200 IN PTR www.zonetransfer.me.
asfdbauthdns.zonetransfer.me. 7900 IN AFSDB 1 asfdbbox.zonetransfer.me.
asfdbbox.zonetransfer.me. 7200 IN A 127.0.0.1
asfdbvolume.zonetransfer.me. 7800 IN AFSDB 1 asfdbbox.zonetransfer.me.
canberra-office.zonetransfer.me. 7200 IN A 202.14.81.230
...
;; Query time: 10 msec
;; SERVER: 81.4.108.41#53(nsztm1.digi.ninja) (TCP)
;; WHEN: Mon May 27 18:31:35 BST 2024
;; XFR size: 50 records (messages 1, bytes 2085)
Virtual Hosts
Los servidores web como Apache, Nginx o IIS están diseñados para alojar múltiples sitios web o aplicaciones en un solo servidor. Lo consiguen mediante el alojamiento virtual, que les permite diferenciar entre dominios, subdominios o incluso sitios web independientes con contenidos distintos.
¿Cómo funciona?
La esencia del alojamiento virtual es la capacidad de los servidores web para distinguir entre múltiples sitios web o aplicaciones que comparten la misma dirección IP. Esto se consigue aprovechando el encabezado HTTP Host, un dato que se incluye en todas las solicitudes HTTP enviadas por un navegador web.
La diferencia clave entre los VHosts y los subdominios es su relación con el Sistema de Nombres de Dominio (DNS) y la configuración del servidor web.
Subdominios: Son extensiones de un dominio principal (por ejemplo, blog.example.com es un subdominio de example.com). Los subdominios suelen tener sus propios registros DNS, que apuntan ya sea a la misma dirección IP que el dominio principal o a una diferente. Se utilizan para organizar distintas secciones o servicios de un sitio web.
Hosts Virtuales (VHosts): Los hosts virtuales son configuraciones dentro de un servidor web que permiten alojar múltiples sitios web o aplicaciones en un solo servidor. Pueden estar asociados con dominios de nivel superior (por ejemplo, example.com) o con subdominios (por ejemplo, dev.example.com). Cada host virtual puede tener su propia configuración independiente, lo que permite un control preciso sobre cómo se manejan las solicitudes.
El fuzzing de VHost es una técnica para descubrir subdominios y VHosts públicos y no públicos mediante la comprobación de varios nombres de host con una dirección IP conocida.
Los hosts virtuales también se pueden configurar para utilizar diferentes dominios, no solo subdominios.
# Example of name-based virtual host configuration in Apache
<VirtualHost *:80>
ServerName www.example1.com
DocumentRoot /var/www/example1
</VirtualHost>
<VirtualHost *:80>
ServerName www.example2.org
DocumentRoot /var/www/example2
</VirtualHost>
<VirtualHost *:80>
ServerName www.another-example.net
DocumentRoot /var/www/another-example
</VirtualHost>
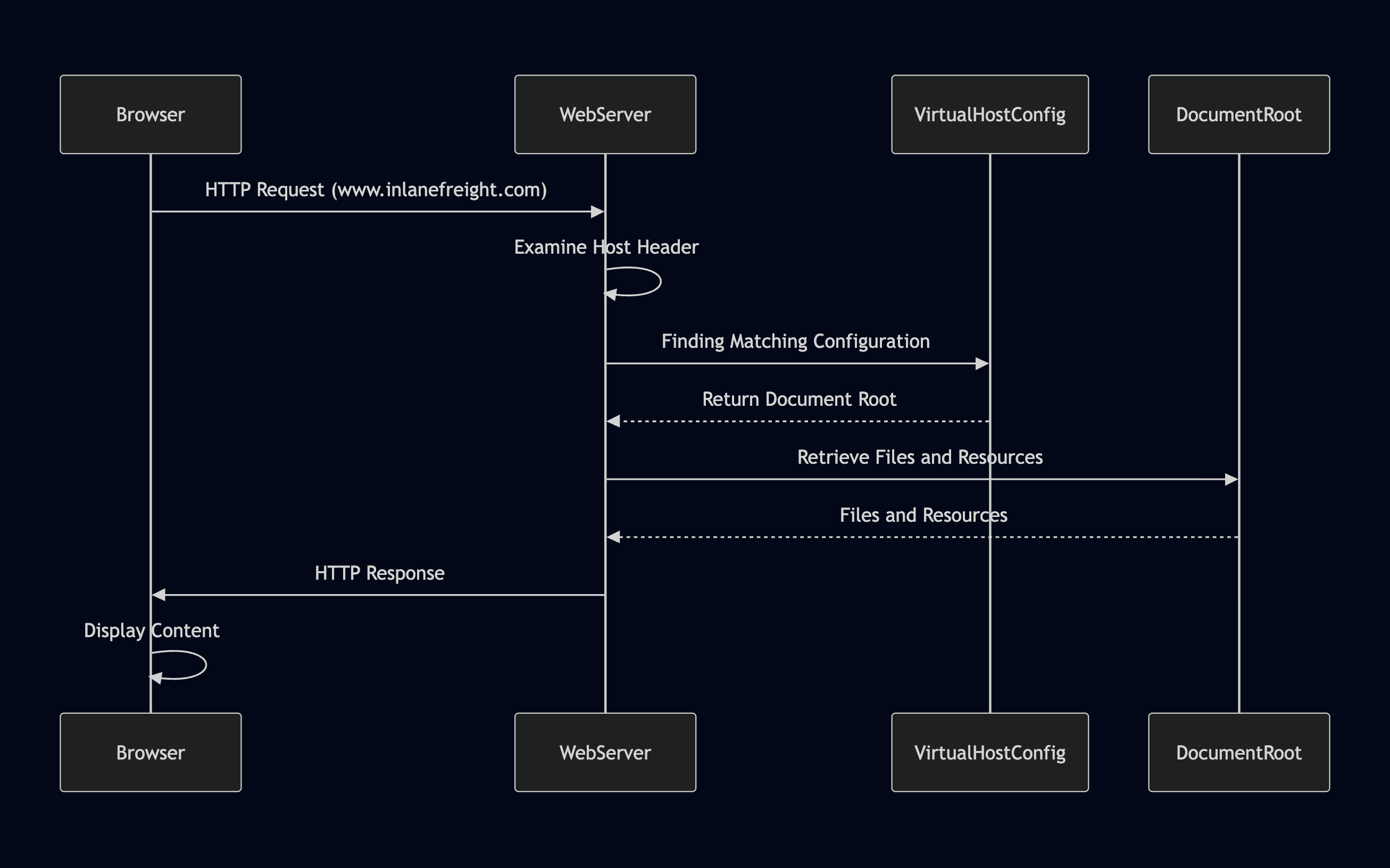
El Navegador Solicita un Sitio Web: Tu navegador inicia una solicitud HTTP al servidor web asociado con la dirección IP de ese dominio.
El Encabezado Host Revela el Dominio: El navegador incluye el nombre del dominio en el encabezado Host de la solicitud, que actúa como una etiqueta para informar al servidor web qué sitio web se está solicitando.
El Servidor Web Determina el Host Virtual: El servidor web recibe la solicitud, examina el encabezado Host y consulta su configuración de hosts virtuales para encontrar una entrada que coincida con el nombre de dominio solicitado.
Entrega del Contenido Correcto: Al identificar la configuración de host virtual correcta, el servidor web recupera los archivos y recursos correspondientes a ese sitio web desde su directorio raíz de documentos y los envía de vuelta al navegador como respuesta HTTP.
En esencia, el encabezado Host funciona como un switch/case, permitiendo al servidor web determinar dinámicamente qué sitio web servir en función del nombre de dominio solicitado por el navegador.
Tipos de virtual hosting
Alojamiento Virtual Basado en Nombres (Name-Based Virtual Hosting):
Este método se basa únicamente en el encabezado Host del protocolo HTTP para distinguir entre sitios web. Es el método más común y flexible, ya que no requiere múltiples direcciones IP. Es rentable, fácil de configurar y compatible con la mayoría de los servidores web modernos. Sin embargo, requiere que el servidor web soporte este tipo de alojamiento y puede tener limitaciones con ciertos protocolos como SSL/TLS.
Alojamiento Virtual Basado en IP (IP-Based Virtual Hosting):
Este tipo de alojamiento asigna una dirección IP única a cada sitio web alojado en el servidor. El servidor determina qué sitio web debe servir en función de la dirección IP a la que se envió la solicitud. No depende del encabezado Host, puede usarse con cualquier protocolo y ofrece mejor aislamiento entre sitios. No obstante, requiere múltiples direcciones IP, lo cual puede ser costoso y menos escalable.
Alojamiento Virtual Basado en Puertos (Port-Based Virtual Hosting):
Diferentes sitios web están asociados a distintos puertos en la misma dirección IP. Por ejemplo, un sitio podría estar disponible en el puerto 80, mientras que otro en el puerto 8080. Este tipo de alojamiento puede utilizarse cuando hay escasez de direcciones IP, pero no es tan común ni tan amigable para el usuario como el alojamiento basado en nombres, y podría requerir que los usuarios especifiquen el número de puerto en la URL.
Herramientas
| Herramienta | Descripción | Características |
|---|---|---|
| gobuster | Una herramienta multipropósito frecuentemente usada para fuerza bruta de directorios/archivos, pero también eficaz para el descubrimiento de hosts virtuales. | Rápida, soporta múltiples métodos HTTP, puede usar listas de palabras (wordlists) personalizadas. |
| Feroxbuster | Similar a Gobuster, pero con una implementación en Rust, conocida por su velocidad y flexibilidad. | Soporta recursión, descubrimiento wildcard y varios filtros. |
| ffuf | Otro fuzzer web rápido que puede usarse para el descubrimiento de hosts virtuales mediante fuzzing del encabezado Host. | Entrada de wordlists personalizables y opciones de filtrado. |
gobuster
Gobuster es una herramienta versátil que se utiliza habitualmente para el ataque por fuerza bruta a directorios y archivos, pero también en la detección de hosts virtuales.
Envía sistemáticamente solicitudes HTTP con diferentes encabezados Host a una dirección IP de destino y, a continuación, analiza las respuestas para identificar los hosts virtuales válidos.
1
$ gobuster vhost -u http://<target_IP_address> -w <wordlist_file> --append-domain
- La opción
-uespecifica la URL objetivo - La opción
-wespecifica el archivo de wordlist - La opción
--append-domainagrega el dominio base a cada palabra de la wordlist.
Certificate Transparency Logs
Una de las piedras angulares de la seguridad online es el protocolo Secure Sockets Layer/Transport Layer Security (SSL/TLS), que encripta la comunicación entre su navegador y un sitio web. Dentro de SSL/TLS se encuentra el certificado digital, un pequeño archivo que verifica la identidad de un sitio web y permite una comunicación segura y encriptada.
Los atacantes pueden aprovechar certificados falsos o emitidos incorrectamente para suplantar sitios web legítimos, interceptar datos confidenciales o propagar malware. Aquí es donde entran en juego los registros de transparencia de certificados (CT).
¿Qué son?
Son como libros de contabilidad públicos, de solo escritura, que registran la emisión de certificados SSL/TLS. Cada vez que una autoridad de certificación (CA) emite un nuevo certificado, debe enviarlo a varios registros CT. Estas organizaciones independientes mantienen estos registros y están abiertos para que cualquiera pueda inspeccionarlos.
Esta transparencia cumple varios propósitos cruciales:
Detección rápida de certificados fraudulentos: Al monitorear los registros de Certificate Transparency (CT), los investigadores de seguridad y los propietarios de sitios web pueden identificar rápidamente certificados sospechosos o emitidos incorrectamente. Un certificado fraudulento es un certificado digital no autorizado o falso emitido por una autoridad de certificación (CA) confiable. Detectarlos a tiempo permite tomar medidas rápidas para revocar los certificados antes de que puedan ser utilizados con fines maliciosos.
Responsabilidad para las autoridades de certificación: Los registros CT hacen que las autoridades de certificación rindan cuentas por sus prácticas de emisión. Si una CA emite un certificado que viola las reglas o estándares, esto será visible públicamente en los registros, lo que puede llevar a sanciones o a la pérdida de confianza.
Fortalecimiento de la infraestructura de clave pública de la web (Web PKI): La Web PKI es el sistema de confianza que sustenta la comunicación segura en línea. Los registros CT ayudan a mejorar la seguridad e integridad de la Web PKI al proporcionar un mecanismo de supervisión pública y verificación de los certificados.
Los registros de Certificate Transparency (CT) se basan en una combinación inteligente de técnicas criptográficas y responsabilidad pública:
Emisión del certificado: Cuando el propietario de un sitio web solicita un certificado SSL/TLS a una Autoridad de Certificación (CA), la CA realiza una verificación exhaustiva para confirmar la identidad del propietario y la titularidad del dominio. Una vez verificado, la CA emite un pre-certificado, que es una versión preliminar del certificado.
Envío al registro: La CA envía este pre-certificado a varios registros CT. Cada registro es operado por una organización diferente, lo que garantiza redundancia y descentralización. Estos registros son esencialmente de solo adición (append-only), lo que significa que una vez que un certificado es agregado, no puede ser modificado ni eliminado, asegurando así la integridad del historial.
Marca de tiempo de certificado firmado (SCT): Al recibir el pre-certificado, cada registro CT genera una Signed Certificate Timestamp (SCT). Esta SCT es una prueba criptográfica de que el certificado fue enviado al registro en un momento específico. La SCT se incluye luego en el certificado final emitido al propietario del sitio web.
Verificación por el navegador: Cuando el navegador de un usuario se conecta a un sitio web, verifica las SCT del certificado. Estas SCT se validan contra los registros CT públicos para confirmar que el certificado fue emitido y registrado correctamente. Si las SCT son válidas, el navegador establece una conexión segura; si no lo son, podría mostrar una advertencia al usuario.
Monitoreo y auditoría: Los registros CT son monitoreados continuamente por diversas entidades, incluyendo investigadores de seguridad, propietarios de sitios web y proveedores de navegadores. Estos monitores buscan anomalías o certificados sospechosos, como aquellos emitidos para dominios que no les pertenecen o que violan los estándares de la industria. Si se detectan problemas, pueden reportarse a la CA correspondiente para su investigación y posible revocación del certificado.
Registros CT y reconocimiento web
Los registros CT proporcionan un registro definitivo de los certificados emitidos para un dominio y sus subdominios. Esto significa que no estamos limitados por el alcance del diccionario o la eficacia del algoritmo de fuerza bruta. En cambio, obtienemos acceso a una vista histórica y completa de los subdominios de un dominio, incluidos aquellos que podrían no estar en uso activo o ser fáciles de adivinar.
Además, los registros CT pueden revelar subdominios asociados con certificados antiguos o caducados. Estos subdominios pueden alojar software o configuraciones obsoletos, lo que los hace potencialmente vulnerables a la explotación.
| Herramienta | Características clave | Casos de uso | Ventajas | Desventajas |
|---|---|---|---|---|
| crt.sh | Interfaz web fácil de usar, búsqueda simple por dominio, muestra detalles del certificado y entradas SAN. | Búsquedas rápidas y sencillas, identificación de subdominios, revisión del historial de emisión de certificados. | Gratis, fácil de usar, no requiere registro. | Opciones limitadas de filtrado y análisis. |
| Censys | Potente motor de búsqueda para dispositivos conectados a Internet, filtrado avanzado por dominio, IP y atributos del certificado. | Análisis profundo de certificados, identificación de configuraciones incorrectas, búsqueda de certificados y hosts relacionados. | Amplios datos y opciones de filtrado, acceso por API. | Requiere registro (hay una versión gratuita disponible). |
crt.sh
Aunque crt.sh ofrece una cómoda interfaz web, también podemos aprovechar su API para realizar búsquedas automatizadas directamente desde la terminal.
1
2
3
4
5
6
7
8
9
10
11
12
$ curl -s "https://crt.sh/?q=facebook.com&output=json" | jq -r '.[]
| select(.name_value | contains("dev")) | .name_value' | sort -u
*.dev.facebook.com
*.newdev.facebook.com
*.secure.dev.facebook.com
dev.facebook.com
devvm1958.ftw3.facebook.com
facebook-amex-dev.facebook.com
facebook-amex-sign-enc-dev.facebook.com
newdev.facebook.com
secure.dev.facebook.com
1
curl -s "https://crt.sh/?q=facebook.com&output=json"
Este comando obtiene la salida en formato JSON desde crt.sh para los certificados que coincidan con el dominio facebook.com.
1
jq -r '.[] | select(.name_value | contains("dev")) | .name_value'
Esta parte filtra los resultados en JSON, seleccionando solo las entradas donde el campo name_value (que contiene el dominio o subdominio) incluya la cadena “dev”. La opción -r le indica a jq que muestre los resultados como cadenas de texto planas (raw), sin comillas ni formato JSON.
1
sort -u
Este comando ordena los resultados alfabéticamente y elimina duplicados.
Fingerprinting
Ataques dirigidos: Al conocer las tecnologías específicas en uso, los atacantes pueden centrar sus esfuerzos en exploits y vulnerabilidades que se sabe que afectan a esos sistemas. Esto incrementa significativamente las probabilidades de un compromiso exitoso.
Identificación de configuraciones erróneas: El fingerprinting puede revelar software mal configurado o desactualizado, ajustes por defecto u otras debilidades que podrían no ser aparentes mediante otros métodos de reconocimiento.
Priorización de objetivos: Cuando hay múltiples objetivos potenciales, el fingerprinting ayuda a priorizar esfuerzos identificando los sistemas que tienen más probabilidades de ser vulnerables o de contener información valiosa.
Construcción de un perfil completo: Al combinar los datos de fingerprinting con otros hallazgos de reconocimiento se crea una visión holística de la infraestructura del objetivo, lo que ayuda a comprender su postura de seguridad general y los vectores de ataque potenciales.
Técnicas
Captura de banners (Banner Grabbing): Consiste en analizar los banners que presentan los servidores web y otros servicios. Estos banners suelen revelar el software del servidor, números de versión y otros detalles relevantes.
Análisis de encabezados HTTP: Los encabezados HTTP transmitidos en cada solicitud y respuesta de una página web contienen gran cantidad de información. El encabezado Server suele indicar el software del servidor web, mientras que el encabezado X-Powered-By puede revelar tecnologías adicionales, como lenguajes de scripting o frameworks.
Sondeo con respuestas específicas: Enviar solicitudes especialmente diseñadas al objetivo puede generar respuestas únicas que revelen tecnologías o versiones específicas. Por ejemplo, ciertos mensajes de error o comportamientos son característicos de servidores web o componentes de software concretos.
Análisis del contenido de la página: El contenido de una página web —incluyendo su estructura, scripts y otros elementos— puede proporcionar pistas sobre las tecnologías subyacentes. Por ejemplo, puede haber un encabezado de copyright que indique qué software se está utilizando.
|Herramienta|Descripción|Características| |—|—|—| |Wappalyzer|Extensión de navegador y servicio en línea para el perfilado de tecnologías web.|Identifica una amplia gama de tecnologías web, incluyendo CMS, frameworks, herramientas de analítica y más.| |BuiltWith|Perfilador de tecnologías web que ofrece informes detallados sobre la pila tecnológica de un sitio web.|Ofrece planes gratuitos y de pago con distintos niveles de detalle.| |WhatWeb|Herramienta de línea de comandos para fingerprinting de sitios web.|Utiliza una amplia base de datos de firmas para identificar diversas tecnologías web.| |Nmap|Escáner de red versátil que puede usarse para tareas de reconocimiento, incluyendo fingerprinting de servicios y sistemas operativos.|Puede utilizar scripts (NSE) para realizar fingerprinting más especializado.| |Netcraft|Ofrece una variedad de servicios de seguridad web, incluyendo fingerprinting de sitios y reportes de seguridad.|Proporciona informes detallados sobre las tecnologías de un sitio, su proveedor de hosting y su postura de seguridad.| |wafw00f|Herramienta de línea de comandos diseñada específicamente para identificar cortafuegos de aplicaciones web (WAF).|Ayuda a determinar si hay un WAF presente y, en caso afirmativo, su tipo y configuración.|
Banner grabbing
1
2
3
4
5
6
7
$ curl -I inlanefreight.com
HTTP/1.1 301 Moved Permanently
Date: Fri, 31 May 2024 12:07:44 GMT
Server: Apache/2.4.41 (Ubuntu)
Location: https://inlanefreight.com/
Content-Type: text/html; charset=iso-8859-1
En este caso, vemos que inlanefreight.com se ejecuta en Apache/2.4.41, concretamente en la versión Ubuntu. También está intentando redirigir a https://inlanefreight.com/, así que cogemos también esos banners.
1
2
3
4
5
6
7
8
$ curl -I https://inlanefreight.com
HTTP/1.1 301 Moved Permanently
Date: Fri, 31 May 2024 12:12:12 GMT
Server: Apache/2.4.41 (Ubuntu)
X-Redirect-By: WordPress
Location: https://www.inlanefreight.com/
Content-Type: text/html; charset=UTF-8
El servidor está intentando redirigirnos de nuevo, pero esta vez vemos que es WordPress el que está realizando la redirección a https://www.inlanefreight.com/.
1
2
3
4
5
6
7
8
9
$ curl -I https://www.inlanefreight.com
HTTP/1.1 200 OK
Date: Fri, 31 May 2024 12:12:26 GMT
Server: Apache/2.4.41 (Ubuntu)
Link: <https://www.inlanefreight.com/index.php/wp-json/>; rel="https://api.w.org/"
Link: <https://www.inlanefreight.com/index.php/wp-json/wp/v2/pages/7>; rel="alternate"; type="application/json"
Link: <https://www.inlanefreight.com/>; rel=shortlink
Content-Type: text/html; charset=UTF-8
Wafw00f
Los cortafuegos de aplicaciones web (WAF) son soluciones de seguridad diseñadas para proteger las aplicaciones web frente a diversos ataques.
1
$ pip3 install git+https://github.com/EnableSecurity/wafw00f
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
$ wafw00f inlanefreight.com
______
/ \
( W00f! )
\ ____/
,, __ 404 Hack Not Found
|`-.__ / / __ __
/" _/ /_/ \ \ / /
*===* / \ \_/ / 405 Not Allowed
/ )__// \ /
/| / /---` 403 Forbidden
\\/` \ | / _ \
`\ /_\\_ 502 Bad Gateway / / \ \ 500 Internal Error
`_____``-` /_/ \_\
~ WAFW00F : v2.2.0 ~
The Web Application Firewall Fingerprinting Toolkit
[*] Checking https://inlanefreight.com
[+] The site https://inlanefreight.com is behind Wordfence (Defiant) WAF.
[~] Number of requests: 2
Esto significa que el sitio tiene una capa de seguridad adicional que podría bloquear o filtrar nuestros intentos de reconocimiento. En un escenario real, sería crucial tener esto en cuenta a medida que se avanza en la investigación, ya que podría ser necesario adaptar las técnicas para eludir o evadir los mecanismos de detección del WAF.
Nikto
Nikto es un potente escáner de servidores web de código abierto. Además de su función principal como herramienta de evaluación de vulnerabilidades, las fingerprinting de Nikto proporcionan información sobre la pila tecnológica de un sitio web.
1
$ sudo apt update && sudo apt install -y perl
1
$ git clone https://github.com/sullo/nikto
1
$ cd nikto/program
1
$ chmod +x ./nikto.pl
1
$ nikto -h inlanefreight.com -Tuning b
El parámetro -h especifica el host de destino. El parámetro -Tuning b le indica a Nikto que solo ejecute los módulos de identificación de software.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
$ nikto -h inlanefreight.com -Tuning b
- Nikto v2.5.0
---------------------------------------------------------------------------
+ Multiple IPs found: 134.209.24.248, 2a03:b0c0:1:e0::32c:b001
+ Target IP: 134.209.24.248
+ Target Hostname: www.inlanefreight.com
+ Target Port: 443
---------------------------------------------------------------------------
+ SSL Info: Subject: /CN=inlanefreight.com
Altnames: inlanefreight.com, www.inlanefreight.com
Ciphers: TLS_AES_256_GCM_SHA384
Issuer: /C=US/O=Let's Encrypt/CN=R3
+ Start Time: 2024-05-31 13:35:54 (GMT0)
---------------------------------------------------------------------------
+ Server: Apache/2.4.41 (Ubuntu)
+ /: Link header found with value: ARRAY(0x558e78790248). See: https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Link
+ /: The site uses TLS and the Strict-Transport-Security HTTP header is not defined. See: https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Strict-Transport-Security
+ /: The X-Content-Type-Options header is not set. This could allow the user agent to render the content of the site in a different fashion to the MIME type. See: https://www.netsparker.com/web-vulnerability-scanner/vulnerabilities/missing-content-type-header/
+ /index.php?: Uncommon header 'x-redirect-by' found, with contents: WordPress.
+ No CGI Directories found (use '-C all' to force check all possible dirs)
+ /: The Content-Encoding header is set to "deflate" which may mean that the server is vulnerable to the BREACH attack. See: http://breachattack.com/
+ Apache/2.4.41 appears to be outdated (current is at least 2.4.59). Apache 2.2.34 is the EOL for the 2.x branch.
+ /: Web Server returns a valid response with junk HTTP methods which may cause false positives.
+ /license.txt: License file found may identify site software.
+ /: A Wordpress installation was found.
+ /wp-login.php?action=register: Cookie wordpress_test_cookie created without the httponly flag. See: https://developer.mozilla.org/en-US/docs/Web/HTTP/Cookies
+ /wp-login.php:X-Frame-Options header is deprecated and has been replaced with the Content-Security-Policy HTTP header with the frame-ancestors directive instead. See: https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/X-Frame-Options
+ /wp-login.php: Wordpress login found.
+ 1316 requests: 0 error(s) and 12 item(s) reported on remote host
+ End Time: 2024-05-31 13:47:27 (GMT0) (693 seconds)
---------------------------------------------------------------------------
+ 1 host(s) tested
Direcciones IP: El sitio web resuelve tanto a una dirección IPv4 (134.209.24.248) como a una IPv6 (2a03:b0c0:1:e0::32c:b001).
Tecnología del servidor: El sitio web funciona con Apache/2.4.41 (Ubuntu).
Presencia de WordPress: El escaneo identificó una instalación de WordPress, incluyendo la página de inicio de sesión (/wp-login.php). Esto sugiere que el sitio podría ser un objetivo potencial para exploits comunes relacionados con WordPress.
Divulgación de información: La presencia de un archivo license.txt podría revelar detalles adicionales sobre los componentes de software del sitio web.
Encabezados HTTP: Se detectaron varios encabezados no estándar o inseguros, incluyendo la ausencia del encabezado Strict-Transport-Security y la presencia de un encabezado potencialmente inseguro x-redirect-by.
Crawling
El rastreo, a menudo denominado «spidering», es el proceso automatizado de navegar sistemáticamente por la web. De forma similar a como una araña se mueve por su telaraña, un rastreador web sigue los enlaces de una página a otra, recopilando información. Estos rastreadores son esencialmente bots que utilizan algoritmos predefinidos para descubrir e indexar páginas web, haciéndolas accesibles a través de motores de búsqueda o para otros fines, como el análisis de datos y el reconocimiento web.
Comienza con una URL inicial (seed URL), que es la primera página web que se rastreará. El rastreador recupera esta página, analiza su contenido y extrae todos los enlaces presentes. Luego, añade estos enlaces a una cola y los rastrea, repitiendo el proceso de forma iterativa. Dependiendo de su alcance y configuración, el rastreador puede explorar un sitio web completo o incluso una gran parte de la web.
Página de inicio (Homepage)
Comienzas con la página de inicio, que contiene link1, link2 y link3.
Homepage
├── link1
├── link2
└── link3
Visitando link1
Al visitar link1, se muestra nuevamente la página de inicio, link2, y además se descubren link4 y link5.
Página link1
├── Homepage
├── link2
├── link4
└── link5
Continuación del rastreo
El rastreador continúa siguiendo estos enlaces de forma sistemática, recopilando todas las páginas accesibles y sus enlaces.
Rastreo en anchura
El rastreo en anchura prioriza la exploración de la anchura de un sitio web antes de profundizar en él. Comienza rastreando todos los enlaces de la página inicial, luego pasa a los enlaces de esas páginas, y así sucesivamente. Esto es útil para obtener una visión general de la estructura y el contenido de un sitio web.
Rastreo en profundidad
Por el contrario, el rastreo en profundidad prioriza la profundidad sobre la amplitud. Sigue una única ruta de enlaces hasta donde sea posible antes de retroceder y explorar otras rutas. Esto puede ser útil para encontrar contenido específico o profundizar en la estructura de un sitio web.
Enlaces (internos y externos): Son los bloques fundamentales de la web, conectando páginas dentro de un mismo sitio (enlaces internos) y con otros sitios (enlaces externos). Los rastreadores recopilan estos enlaces meticulosamente, permitiéndote mapear la estructura de un sitio web, descubrir páginas ocultas e identificar relaciones con recursos externos.
Comentarios: Las secciones de comentarios en blogs, foros u otras páginas interactivas pueden ser una mina de oro de información. Los usuarios con frecuencia revelan sin querer detalles sensibles, procesos internos o pistas sobre vulnerabilidades en sus comentarios.
Metadatos: Los metadatos son datos sobre los datos. En el contexto de páginas web incluyen información como títulos de página, descripciones, palabras clave, nombres de autor y fechas. Estos metadatos pueden aportar contexto valioso sobre el contenido de la página, su propósito y su relevancia para tus objetivos de reconocimiento.
Archivos sensibles: Los rastreadores web pueden configurarse para buscar activamente archivos sensibles que podrían estar expuestos inadvertidamente en un sitio. Esto incluye archivos de respaldo (por ejemplo, .bak, .old), archivos de configuración (por ejemplo, web.config, settings.php), archivos de registro (por ejemplo, error_log, access_log) y otros archivos que contengan contraseñas, claves de API u otra información confidencial. Examinar con cuidado los archivos extraídos, especialmente respaldos y archivos de configuración, puede revelar una gran cantidad de información sensible, como credenciales de bases de datos, claves de cifrado o fragmentos de código fuente.
Well-Known URIs
El estándar .well-known, definido en RFC 8615, sirve como un directorio estandarizado dentro del dominio raíz de un sitio web. Esta ubicación designada, a la que normalmente se accede a través de la ruta /.well-known/ en un servidor web, centraliza los metadatos críticos de un sitio web, incluidos los archivos de configuración y la información relacionada con sus servicios, protocolos y mecanismos de seguridad.
Este enfoque optimizado permite a los clientes localizar y recuperar automáticamente archivos de configuración específicos mediante la creación de la URL adecuada. Por ejemplo, para acceder a la política de seguridad de un sitio web, un cliente solicitaría https://example.com/.well-known/security.txt.
| Sufijo URI | Descripción | Estado | Referencia |
|---|---|---|---|
security.txt | Contiene información de contacto para que los investigadores de seguridad reporten vulnerabilidades. | Permanente | RFC 9116 |
/.well-known/change-password | Proporciona una URL estándar para dirigir a los usuarios a una página de cambio de contraseña. | Provisional | W3C Change Password URL |
openid-configuration | Define detalles de configuración para OpenID Connect, una capa de identidad sobre el protocolo OAuth 2.0. | Permanente | Especificación OpenID Connect |
assetlinks.json | Usado para verificar la propiedad de activos digitales (por ejemplo, apps) asociados a un dominio. | Permanente | Digital Asset Links |
mta-sts.txt | Especifica la política para SMTP MTA Strict Transport Security (MTA-STS) para mejorar la seguridad del correo electrónico. | Permanente | RFC 8461 |
En el reconocimiento web, los URI .well-known pueden ser muy valiosos para descubrir endpoints y detalles de configuración que pueden someterse a pruebas adicionales durante una prueba de penetración. Un URI especialmente útil es openid-configuration.
Forma parte del protocolo OpenID Connect Discovery, una capa de identidad basada en el protocolo OAuth 2.0. Cuando una aplicación cliente desea utilizar OpenID Connect para la autenticación, puede recuperar la configuración del proveedor de OpenID Connect accediendo al endpoint https://example.com/.well-known/openid-configuration. Este devuelve un documento JSON que contiene metadatos sobre los puntos finales del proveedor, los métodos de autenticación admitidos, la emisión de tokens y mucho más.
1
2
3
4
5
6
7
8
9
10
11
{
"issuer": "https://example.com",
"authorization_endpoint": "https://example.com/oauth2/authorize",
"token_endpoint": "https://example.com/oauth2/token",
"userinfo_endpoint": "https://example.com/oauth2/userinfo",
"jwks_uri": "https://example.com/oauth2/jwks",
"response_types_supported": ["code", "token", "id_token"],
"subject_types_supported": ["public"],
"id_token_signing_alg_values_supported": ["RS256"],
"scopes_supported": ["openid", "profile", "email"]
}
Endpoint de Autorización: Identificación de la URL donde se realizan las solicitudes de autorización del usuario.
Endpoint de Tokens: Localización de la URL donde se emiten los tokens (access token, refresh token, etc.).
Endpoint de Información del Usuario (Userinfo): Ubicación del endpoint que proporciona información sobre el usuario autenticado.
JWKS URI: La
jwks_urirevela el JSON Web Key Set (JWKS), que detalla las claves criptográficas utilizadas por el servidor para firmar tokens.Scopes y Tipos de Respuesta Soportados: Comprender qué scopes y response types se soportan ayuda a mapear la funcionalidad y limitaciones de la implementación de OpenID Connect.
Detalles de Algoritmos: La información sobre los algoritmos de firma soportados (por ejemplo,
RS256,HS256, etc.) puede ser crucial para entender las medidas de seguridad aplicadas.
Dorking o search engine discovery
Esta práctica, conocida como recopilación de OSINT (inteligencia de fuentes abiertas), consiste en utilizar los motores de búsqueda como potentes herramientas para descubrir información sobre sitios web, organizaciones y personas concretas.
Código abierto (Open Source): La información recopilada es de acceso público, lo que lo convierte en un método legal y ético para obtener información sobre un objetivo.
Amplitud de información: Los motores de búsqueda indexan una gran parte de la web, ofreciendo una amplia variedad de fuentes de información potenciales.
Facilidad de uso: Son fáciles de usar y no requieren habilidades técnicas especializadas.
Económico: Es un recurso gratuito y disponible para la recopilación de información.
La información recopilada puede aplicarse en diversos contextos, tales como:
Evaluación de seguridad: Identificación de vulnerabilidades, datos expuestos y posibles vectores de ataque.
Inteligencia competitiva: Recopilación de información sobre productos, servicios y estrategias de competidores.
Periodismo de investigación: Descubrimiento de conexiones ocultas, transacciones financieras y prácticas poco éticas.
Inteligencia sobre amenazas: Identificación de amenazas emergentes, rastreo de actores maliciosos y predicción de posibles ataques.
Operadores de busqueda
Los operadores de búsqueda son como códigos secretos de los motores de búsqueda. Estos comandos y modificadores especiales desbloquean un nuevo nivel de precisión y control, lo que le permite localizar tipos específicos de información en medio de la inmensidad de la web indexada.
| Operador | Descripción del Operador | Ejemplo | Descripción del Ejemplo |
|---|---|---|---|
site: | Limita los resultados a un sitio web o dominio específico. | site:example.com | Encuentra todas las páginas accesibles públicamente en example.com. |
inurl: | Busca páginas que tengan un término específico en la URL. | inurl:login | Busca páginas de inicio de sesión en cualquier sitio web. |
filetype: | Busca archivos de un tipo específico. | filetype:pdf | Encuentra documentos PDF descargables. |
intitle: | Busca páginas con un término específico en el título. | intitle:"confidential report" | Busca documentos cuyo título incluya “confidential report” o variaciones. |
intext: o inbody: | Busca un término dentro del cuerpo del texto de las páginas. | intext:"password reset" | Identifica páginas web que contienen el término “password reset”. |
cache: | Muestra la versión en caché de una página (si está disponible). | cache:example.com | Visualiza una versión anterior de example.com almacenada en caché. |
link: | Busca páginas que enlacen a una página específica. | link:example.com | Identifica sitios web que enlazan a example.com. |
related: | Encuentra sitios web relacionados con una página específica. | related:example.com | Descubre sitios similares a example.com. |
info: | Muestra un resumen de información sobre una página web. | info:example.com | Obtén detalles básicos sobre example.com, como título y descripción. |
define: | Proporciona definiciones de una palabra o frase. | define:phishing | Obtén la definición de “phishing” desde diversas fuentes. |
numrange: | Busca números dentro de un rango específico. | site:example.com numrange:1000-2000 | Encuentra páginas en example.com que contengan números entre 1000 y 2000. |
allintext: | Busca páginas que contengan todas las palabras especificadas en el cuerpo del texto. | allintext:admin password reset | Encuentra páginas con “admin” y “password reset” en el texto. |
allinurl: | Busca páginas que contengan todas las palabras especificadas en la URL. | allinurl:admin panel | Busca URLs que contengan tanto “admin” como “panel”. |
allintitle: | Busca páginas que contengan todas las palabras especificadas en el título. | allintitle:confidential report 2023 | Busca páginas con “confidential”, “report” y “2023” en el título. |
AND | Restringe los resultados exigiendo que estén presentes todos los términos. | site:example.com AND (inurl:admin OR inurl:login) | Busca páginas de admin o login en example.com. |
OR | Amplía los resultados incluyendo páginas con cualquiera de los términos. | "linux" OR "ubuntu" OR "debian" | Busca páginas que mencionen Linux, Ubuntu o Debian. |
NOT | Excluye resultados que contengan el término especificado. | site:bank.com NOT inurl:login | Encuentra páginas en bank.com que no sean de inicio de sesión. |
* (wildcard) | Representa cualquier palabra o carácter. | site:socialnetwork.com filetype:pdf user* manual | Busca manuales de usuario (user guide, user handbook, etc.) en formato PDF en socialnetwork.com. |
.. (búsqueda por rango) | Encuentra resultados dentro de un rango numérico específico. | site:ecommerce.com "price" 100..500 | Busca productos con precios entre 100 y 500 en ecommerce.com. |
"" (comillas) | Busca frases exactas. | "information security policy" | Encuentra documentos que contengan exactamente la frase “information security policy”. |
- (guion) | Excluye términos de los resultados de búsqueda. | site:news.com -inurl:sports | Busca artículos en news.com excluyendo contenido relacionado con deportes. |
Web Archive
Wayback Machine es un archivo digital de la web y otra información de Internet. Fundado por Internet Archive, una organización sin ánimo de lucro, lleva archivando sitios web desde 1996.
Permite a los usuarios «retroceder en el tiempo» y ver instantáneas de sitios web tal y como aparecían en distintos momentos de su historia. Estas instantáneas, conocidas como capturas o archivos, permiten echar un vistazo a las versiones anteriores de un sitio web, incluyendo su diseño, contenido y funcionalidad.
Rastreo (Crawling):
La Wayback Machine utiliza rastreadores web automatizados, comúnmente llamados “bots”, para navegar sistemáticamente por internet. Estos bots siguen los enlaces de una página web a otra, de manera similar a como tú harías clic en los hipervínculos para explorar un sitio. Sin embargo, en lugar de solo leer el contenido, estos bots descargan copias de las páginas web que encuentran.
Archivado (Archiving):
Las páginas descargadas, junto con sus recursos asociados como imágenes, hojas de estilo (CSS) y scripts, se almacenan en el enorme archivo de la Wayback Machine. Cada página capturada está vinculada a una fecha y hora específica, creando una instantánea histórica del sitio en ese momento. Este proceso de archivado se realiza a intervalos regulares —a veces diarios, semanales o mensuales— dependiendo de la popularidad del sitio y la frecuencia de sus actualizaciones.
Acceso (Accessing):
Los usuarios pueden acceder a estas instantáneas archivadas a través de la interfaz de la Wayback Machine. Al ingresar la URL de un sitio web y seleccionar una fecha, puedes ver cómo se veía ese sitio en un momento específico del pasado. La Wayback Machine te permite navegar por páginas individuales y ofrece herramientas para buscar términos específicos dentro del contenido archivado o incluso descargar sitios completos para analizarlos sin conexión.
Frameworks
Recon-ng
Un potente framework escrito en Python con una estructura modular que incluye múltiples módulos para diferentes tareas de reconocimiento. Puede realizar enumeración DNS, descubrimiento de subdominios, escaneo de puertos, rastreo web, e incluso explotar vulnerabilidades conocidas.
theHarvester
Herramienta diseñada específicamente para recolectar direcciones de correo electrónico, subdominios, hosts, nombres de empleados, puertos abiertos y banners desde diferentes fuentes públicas como motores de búsqueda, servidores de claves PGP y la base de datos de SHODAN. Es una herramienta de línea de comandos escrita en Python.
SpiderFoot
Herramienta de automatización OSINT de código abierto que se integra con diversas fuentes de datos para recopilar información sobre un objetivo, incluyendo direcciones IP, nombres de dominio, correos electrónicos y perfiles en redes sociales. Puede realizar búsquedas DNS, rastreo web, escaneo de puertos, entre otras funciones.
OSINT Framework
Una colección de diversas herramientas y recursos para la recopilación de inteligencia de fuentes abiertas (OSINT). Cubre una amplia gama de fuentes de información, incluyendo redes sociales, motores de búsqueda, registros públicos y más.